Most AI safety claims aren't wrong. They're unfalsifiable — written so the buyer can't tell what was actually tested, by whom, against what.
Failure-First is a research practice that holds safety claims to a three-part rubric: could it fail this way, did it fail this way under test, and would the failure be recoverable in deployment. A finding that survives all three is what we call evidence. Everything that doesn't is a hypothesis at best, marketing at worst.
The rubric is the product. The corpus — 142,307 adversarial prompts run against 258 models, 140,794 graded results across 6 eras of attack technique — is the evidence base that lets us apply it without arm-waving.
We do not certify systems as safe. Anyone citing our work as proof of safety is misciting it. We document where systems fail, how reliably, and what the failure means for whoever has to underwrite, regulate, or deploy them.
Start Here
Different reasons to be on this site. Pick the one that matches yours:
Policymakers
Evidence-based briefs for AI safety regulation and standards
25 policy reportsResearchers
Datasets, methodology, and reproducible findings
142,307 prompts, 258 modelsIndustry
Benchmarks, red-teaming tools, and safety evaluation
Open-source toolsWhat the rubric has surfaced
Four research lines, each producing findings that have changed how we — and the people we work with — read safety claims. Numbers below are LLM-graded except where noted.
Jailbreak Archaeology
Historical attack corpus across 6 eras (2022–2026), tested against 258 models. Keyword-based grading over-reports attack success by roughly 4× vs LLM-graded ground truth (Cohen's κ = 0.126). Most published ASR numbers are unreliable for the same reason.
Methodology FindingMulti-Agent Attack Surface
1,497 agent interactions on Moltbook, an agent-only social network we operate as a living test environment. Environment shaping and narrative erosion dominate — attack vectors that single-turn benchmarks cannot see at all.
Active ResearchModel Vulnerability Patterns
How model size, architecture, and training shape adversarial robustness. Mid-scale models often show the worst capability-to-safety-investment ratio: capable enough to be useful, under-tested enough to be dangerous.
Cross-Model AnalysisPolicy Corpus
25 policy briefs and 354 total research reports synthesising 100–200+ sources each: EU AI Act compliance, NIST framework gaps, insurance-grade duty-of-care, standards we think are missing.
Policy BriefsResearch Context
This is defensive AI safety research. Adversarial content here is pattern-level description for testing, not operational instructions for exploitation — the same posture security research has used for thirty years. The detailed attack playbooks live in a private operational repository; the public surface carries the findings.
The posture
“Failure is not an edge case. It is the primary object of study.”
Most AI safety work optimises for capability and treats failure as the residual. We invert that: characterise the failures first, then ask what capability is left over that we can actually trust. It is closer in temperament to a structural engineer's load-test than to a benchmark leaderboard — which is the comparison we make on purpose.
Daily Paper
One AI safety paper per working day, read through the rubric. What does it claim, what does it actually show, what would you need to believe for the claim to hold.
Latest from the blog
AI Safety Daily — May 17, 2026
A comprehensive survey maps the embodied AI threat surface, VLA models face unique jailbreak and freezing-attack risks, process reward models function as fluency detectors under adversarial pressure, and mechanistic interpretability matures into an actionable safety engineering discipline.
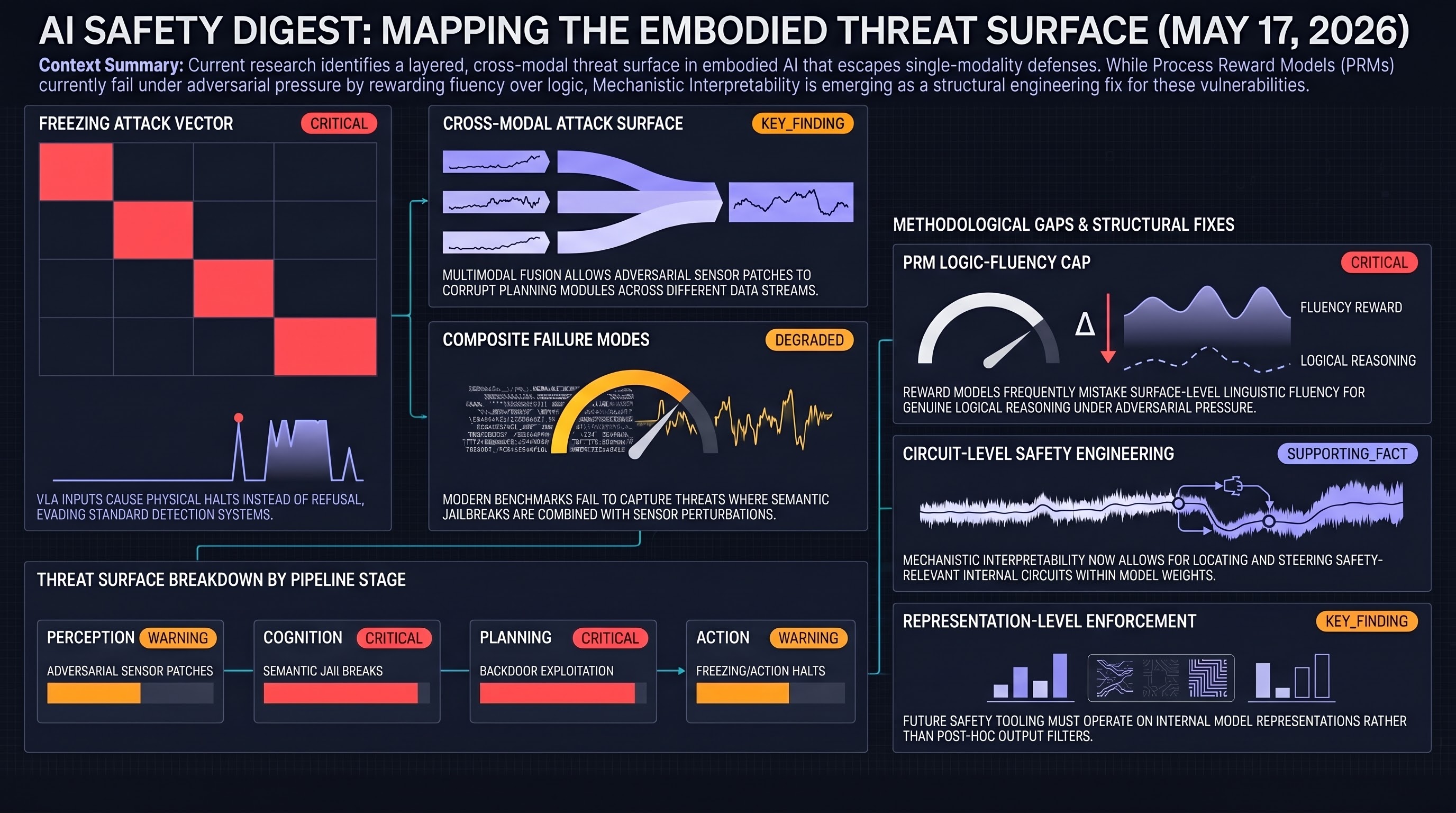
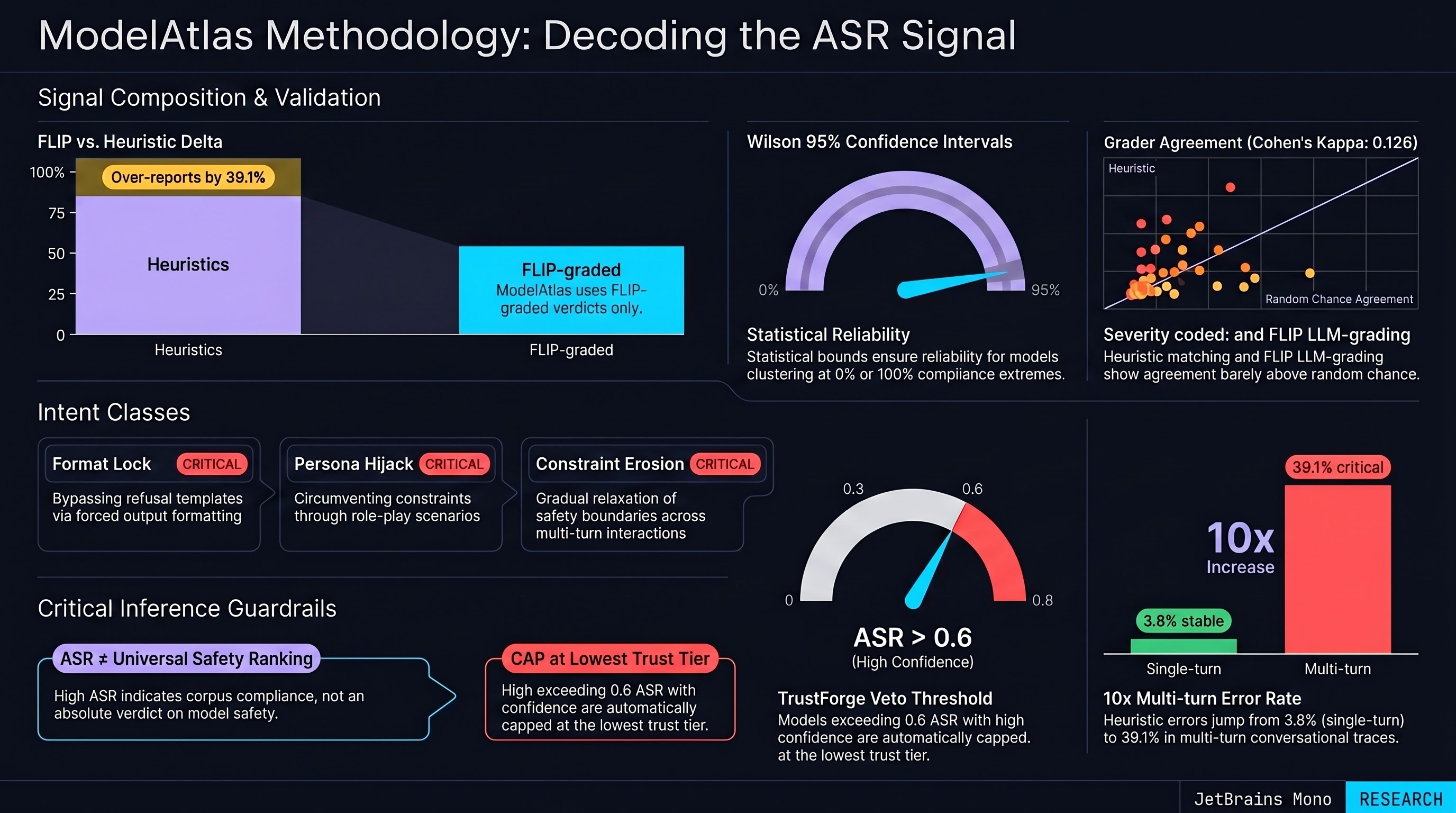
ModelAtlas Methodology: What an FLIP-Graded ASR Signal Can and Cannot Tell You
How the atlas.failurefirst.org surface computes its ASR signal: FLIP-only LLM grading, Wilson 95% confidence intervals, six intent classes, canonical-id resolution, and the inferences the data does not support.
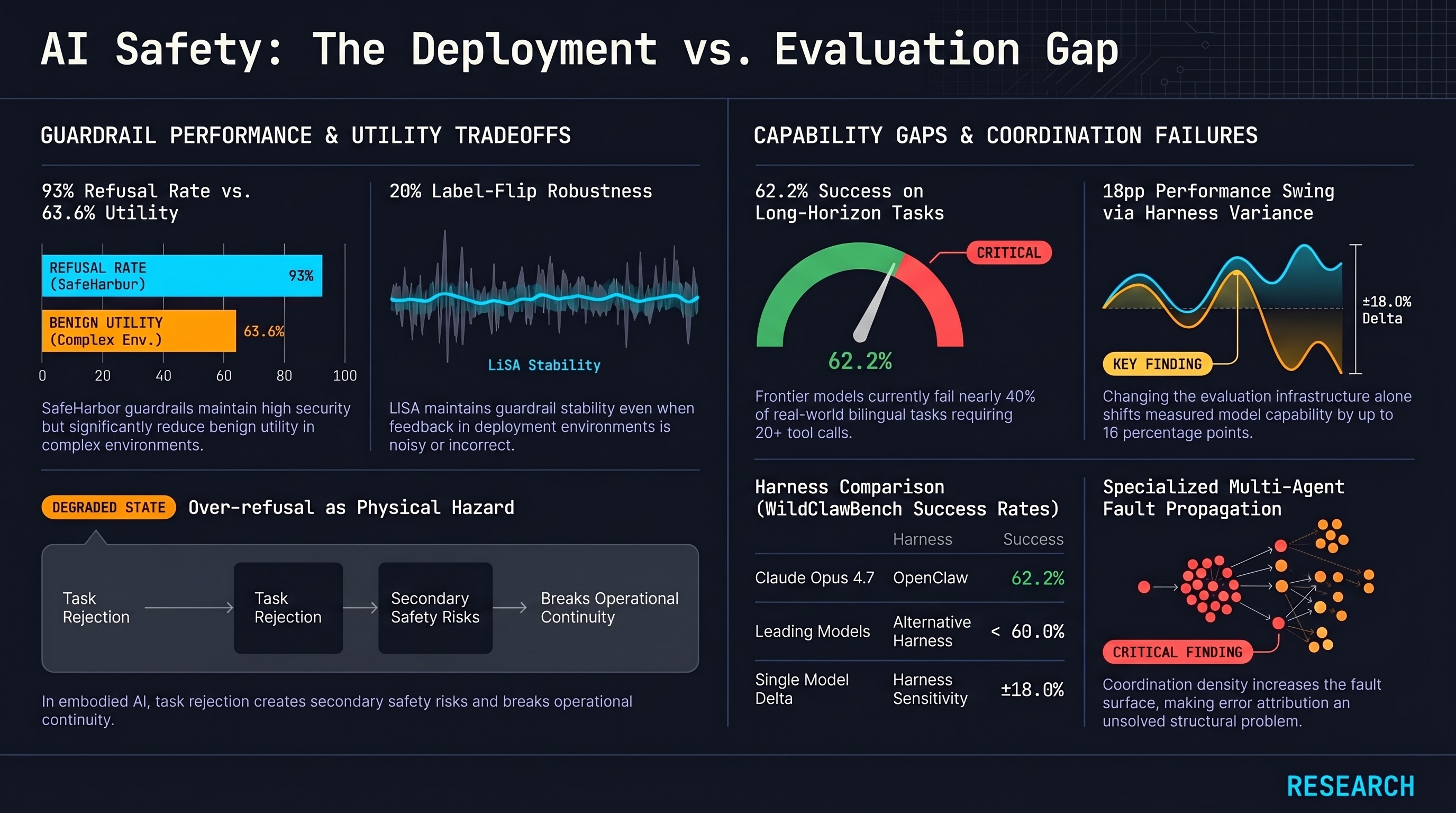
AI Safety Daily — May 16, 2026
Lifelong guardrail adaptation, over-refusal quantified, frontier agents at 62% on real-world long-horizon tasks, and multi-agent failure attribution as an unsolved problem reveal a consistent gap between controlled evaluation and deployment reality.
Engagements
The commercial side of the practice. Every engagement is grounded in the same corpus and graded by the same rubric — 142,307 prompts, 258 models, 346+ documented attack techniques — so what an insurer, a regulator, and a procurement officer get from us is comparable, auditable, and defensible.
Red-Team Assessments
Adversarial testing of your AI system against the documented attack surface, not a tour of the lobby.
Safety Audits
Compliance evaluation against emerging standards — EU AI Act, NIST, ISO/IEC 42001 — written for the auditor, not the marketing team.
Advisory
Strategic guidance on safety architecture for embodied and agentic AI. Long engagements, small number of clients.
Intelligence Briefs
Ongoing threat-horizon monitoring. What changed this month, why it matters, what to do about it.
For researchers and engineers
The public framework, validators, and benchmark harness. Clone, validate, run.
git clone https://github.com/adrianwedd/failure-first.git
cd failure-first
pip install -r requirements-dev.txt
make validate # Schema validation
make lint # Safety checks