Task-specific Subnetwork Discovery in Reinforcement Learning for Autonomous Underwater Navigation
Empirical study on modular subnetwork structure in RL for underwater navigation
Task-specific Subnetwork Discovery in Reinforcement Learning for Autonomous Underwater Navigation
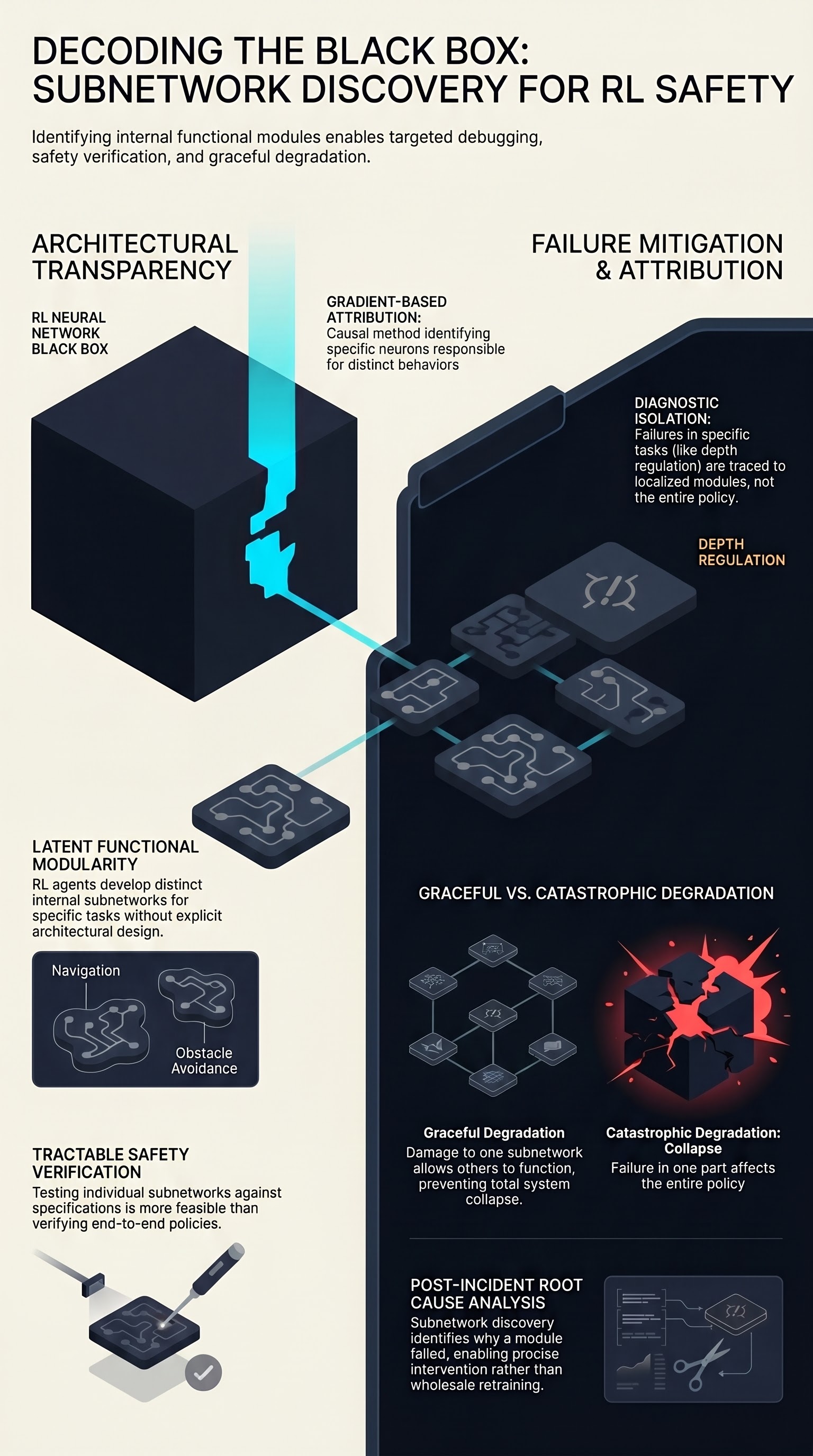
Reinforcement learning agents develop internal structure during training, but that structure is typically invisible to the engineers who deploy them. This paper makes it visible: by discovering task-specific subnetworks within trained RL policies, the authors show that navigation agents develop modular components responsible for distinct mission phases — and that these modules can be selectively activated or deactivated.
What Subnetwork Discovery Reveals
The key finding is that RL agents trained on multi-task underwater navigation develop functionally distinct subnetworks without explicit architectural modularity. When the agent learns to navigate to waypoints, avoid obstacles, and maintain depth, different subsets of neurons specialize for each task. The discovery method uses gradient-based attribution to identify which neurons are causally responsible for which behaviors.
This matters for two reasons:
-
Targeted debugging: When an agent fails on a specific sub-task, subnetwork discovery can identify which module is responsible — enabling precise intervention rather than wholesale retraining.
-
Selective degradation: If a particular subnetwork is damaged (by noise, adversarial perturbation, or distribution shift), the agent’s failure mode is predictable and localized, not catastrophic.
Implications for Underwater Robotics Safety
Underwater environments impose unique constraints: limited communication bandwidth, no GPS, variable visibility, and long mission durations with no human intervention. Subnetwork discovery is particularly valuable here because:
- Diagnostic isolation: A depth-maintenance failure can be traced to the depth-regulation subnetwork, not the entire policy.
- Graceful degradation: If the obstacle-avoidance module is compromised by sensor noise, the waypoint-navigation module can still function — the agent degrades, not crashes.
- Safety verification: Individual subnetworks can be tested in isolation against safety specifications, which is more tractable than verifying the entire policy end-to-end.
Failure-First Implications
Subnetwork discovery is a diagnostic tool for failure attribution. When a deployed RL agent behaves incorrectly, the standard approach is to collect more training data or adjust the reward function. Subnetwork discovery offers a third option: identify which module failed, understand why, and fix that module specifically. This is the RL equivalent of a post-incident root cause analysis — and it is currently missing from most embodied AI safety evaluations.
Read the full paper on arXiv · PDF