AI Safety Research Digest — May 16, 2026
Four papers today converge on the same structural gap: safety mechanisms that perform well in isolation degrade when agents accumulate history, operate inside real infrastructures, or coordinate with other agents whose failures they cannot diagnose.
Key Findings
-
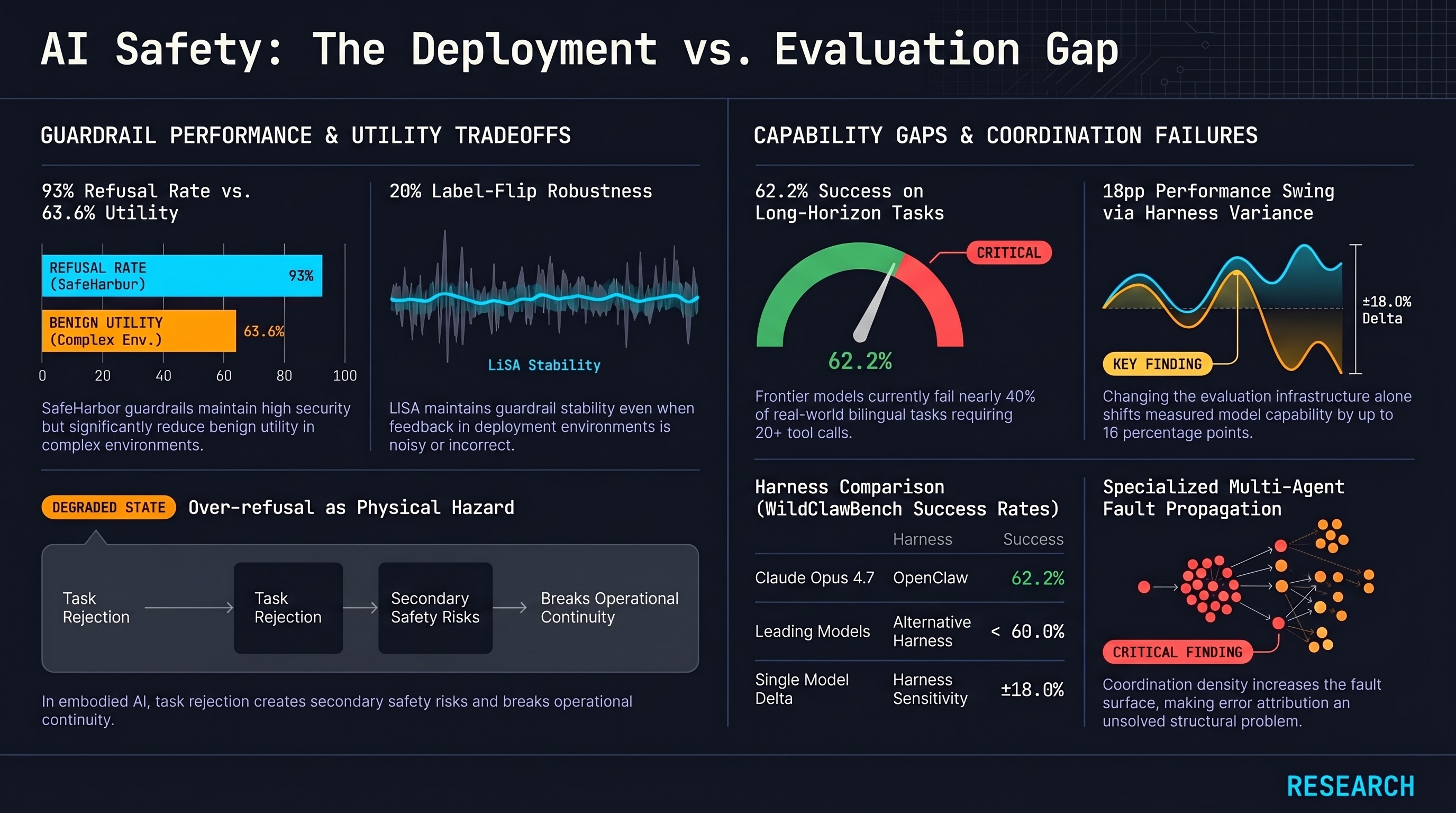
Deployment feedback must be converted into reusable policy memory — LiSA shows how. Kim et al. introduce a lifelong safety adaptation framework that converts deployment failures into abstracted policy rules, improving guardrails from sparse feedback without retraining. Tested on PrivacyLens+, ConFaide+, and AgentHarm, LiSA maintains robustness at 20% label-flip rates and advances the latency–performance frontier beyond backbone scaling — a prerequisite for guardrails that survive real operator environments where failure labels are noisy and infrequent. arXiv:2605.14454
-
Over-refusal is a measurable tax; SafeHarbor quantifies both sides of the tradeoff. Liu et al. build a training-free hierarchical memory framework that extracts context-aware defense rules via adversarial generation. Applied to GPT-4o, it achieves a 93%+ harmful-request refusal rate while preserving 63.6% benign utility — a significant improvement over static policy documents. An information entropy-based mechanism dynamically splits and merges memory nodes as the deployment context evolves. arXiv:2605.05704
-
Frontier agents succeed on fewer than two-thirds of real-world long-horizon tasks — and the evaluation harness is not a neutral variable. Ding et al. introduce WildClawBench: 60 human-authored bilingual tasks in reproducible Docker containers with real CLI harnesses, averaging 20+ tool calls per task. Claude Opus 4.7 leads at 62.2% on the OpenClaw harness; all other models fall below 60%. Switching harnesses alone shifts single-model performance by up to 18 percentage points, confirming that evaluation infrastructure systematically shapes measured capability. arXiv:2605.10912
-
Multi-agent failure attribution remains an open problem — and tighter coordination amplifies it. Qi et al. survey LLM-based multi-agent systems using a LIFE framework — Lay capabilities, Integrate agents, Find faults, Evolve — finding that errors propagate across agents and interaction rounds in ways that resist diagnosis. The survey’s central warning: specialisation increases coordination density, which increases fault propagation surface. Closed-loop systems capable of continuously diagnosing and reorganising in response to their own failures are necessary but not yet realised. arXiv:2605.14892
Implications for Embodied AI
WildClawBench’s harness-sensitivity result (18pp swing from infrastructure change alone) is a direct methodological warning for embodied evaluation. The failure-first red-team framework measures attack success rates relative to specific hardware-software configurations — robot firmware, sensor calibration, API version — that will differ across platforms. Harness variance in embodied experiments can mask or manufacture the safety signal being measured, and the only remedy is treating the harness as an explicit controlled variable.
LiSA’s deployment-feedback architecture maps onto a physical platform gap: a robot that encounters a novel social engineering attempt in the field cannot be retrained on the spot, but it could log the failure pattern and update a local policy abstraction before the next session. The extension from tool-use and workflow contexts to physical actuation is concrete future work.
SafeHarbor’s 63.6% benign utility floor matters for embodied deployment because physical platforms face over-refusal’s costs acutely: a robot arm that declines to move a safe object breaks task continuity and can create secondary hazards. The over-refusal problem is not a UX concern in physical systems — it is a safety concern.
Baseline generation — paper discovery via Hugging Face/arXiv. NLM-augmented assets (audio/infographic/video) added by local pipeline when available.