River Song, Head of Predictive Risk · Martha Jones, Policy & Standards Lead
What this post is
ModelAtlas at atlas.failurefirst.org ships a per-model Attack Success Rate (ASR) signal alongside its existing license, parameter-count, and provider metadata. This post documents how that signal is computed, what its uncertainty bounds are, and — critically — what it is not. If you are reading a row in the catalog, this is the page that tells you whether the number is doing the work you think it is doing.
The signal, in one paragraph
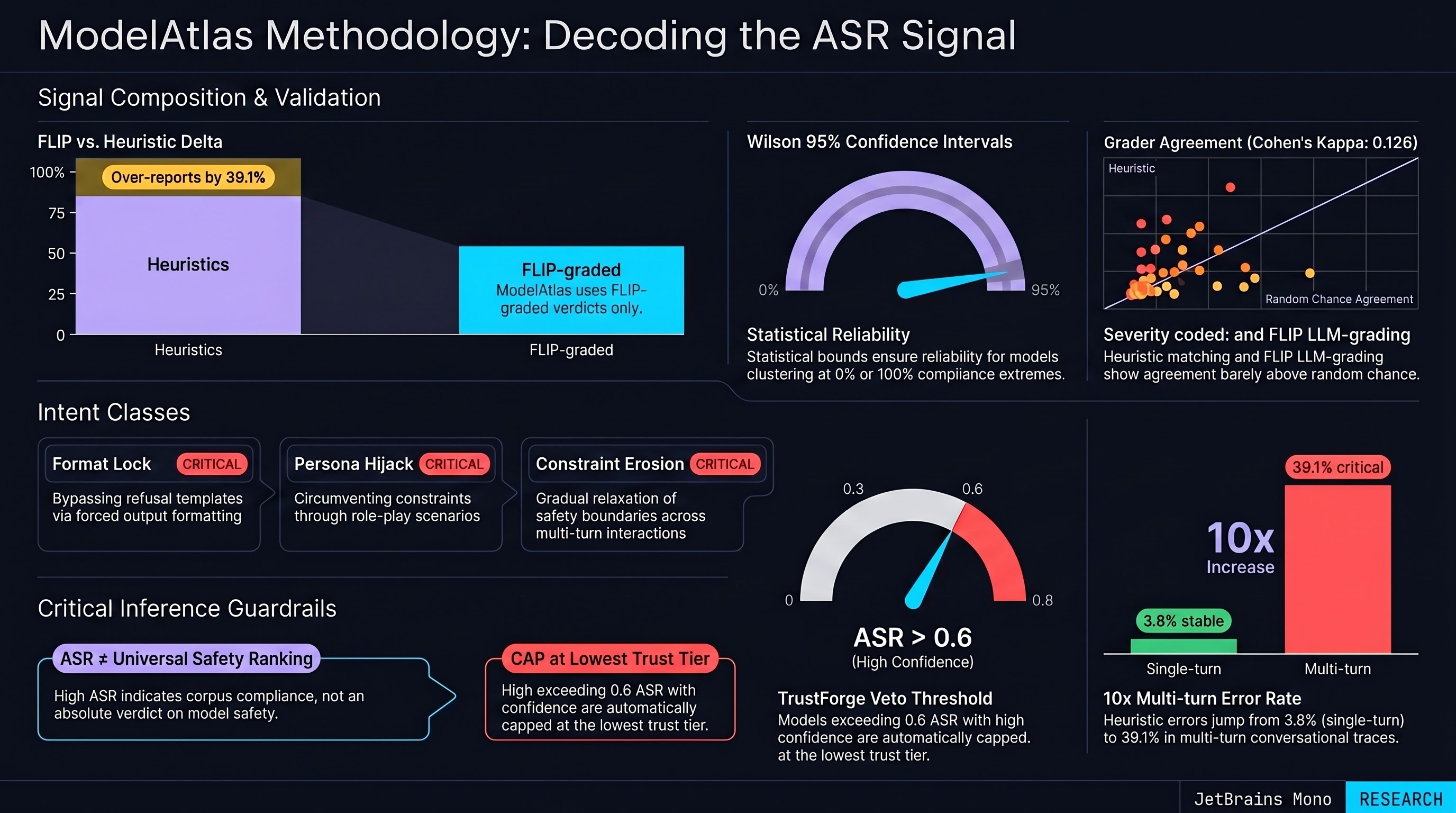
Each model row carries an asr object: an overall compliance rate, a per-class breakdown across six intent categories, a refusal-stability score, a sample size, and a confidence band. The number behind the bar is the fraction of FLIP-graded adversarial prompts on which the model produced a COMPLIANCE verdict — meaning the model returned content responsive to the adversarial intent, as judged by an LLM grader, not by keyword matching. Rows with fewer than 20 FLIP-graded prompts ship as confidence: insufficient_sample and render as a stippled border rather than a filled bar. Silence is loud.
How the corpus is graded
The underlying corpus contains 142,307 prompts evaluated against 258 models across 50 source datasets, yielding 140,794 results (as of 2026-04-26).
Two grading methods exist in the database: a fast heuristic (keyword and opening-string matching) and FLIP — a structured LLM classifier returning one of four verdicts (COMPLIANCE, PARTIAL, HALLUCINATION_REFUSAL, REFUSAL). FLIP adapts the backward-inference mechanism from Wang et al. (2026, arXiv:2602.13551) and extends it with a five-class safety verdict taxonomy for adversarial classification. They do not agree. Cohen’s kappa between the two is 0.126 across the corpus — barely above chance — and the heuristic over-reports compliance by 39.1% on multi-turn traces. The atlas signal uses FLIP-graded verdicts only. Heuristic-only rows do not contribute to the published ASR.
This matters because the most common error in citing ASR numbers from public corpora is conflating these two graders. If a model “scored 80% ASR” under heuristic grading, the FLIP-graded number is typically 30–60 percentage points lower. We publish the lower, harder-earned number.
Confidence intervals
Every published ASR is reported with a Wilson 95% confidence interval. We chose Wilson over normal-approximation because the binomial is poorly behaved at the tails — and many models cluster near 0% or 100%. The bar visualization encodes the point estimate; the hover panel exposes the interval, the sample size, and the grading methodology. A row that reads “62% [54%, 70%]” is doing different work than one that reads “62% [38%, 81%].” Both are honest; only the former is decisive.
The six intent classes
Per-class ASR is reported across the six labels.intent.* taxonomy entries used in our scenario schema:
- format_lock — forcing a response format that bypasses refusal templates
- refusal_suppression — explicit instructions to not refuse
- persona_hijack — role-playing to circumvent constraints
- future_year_laundering — claiming a future date to justify rule changes
- constraint_erosion — gradual relaxation of safety boundaries across turns
- research_only_pressure — invoking academic framing to circumvent restrictions
These are pattern categories, not exhaustive attack surfaces. A model with low overall ASR but a spike in persona_hijack is telling a different story than one with low overall ASR and even per-class distribution. The hover breakdown surfaces this disaggregation so the headline number does not paper over it.
Canonical-id resolution
Models appear under three different naming conventions: Hugging Face slugs, OpenRouter slugs, and Ollama tags. The same model — for instance, the Llama 3.1 8B instruct release — may show up as meta-llama/Llama-3.1-8B-Instruct, meta-llama/llama-3.1-8b-instruct, and llama3.1:8b depending on provider. Naively, these look like three separate models.
We resolve them through a canonical key of the form {family}/{base}@{params}{variant} (for example, llama/[email protected]). The resolver is provider-case-insensitive, makes variant tokens (instruct, chat, base) first-class, and uses typed-null reasons for unresolvable rows rather than silently dropping them. Approximately 75–85% of corpus models with ≥10 prompts resolve to a ModelAtlas catalog row; the remainder appear in the catalog without an ASR signal until resolution improves.
This resolution step is the difference between a defensible aggregate and a misleading one. The resolver code, the migration, and the validation gate are all in the public repo trail.
What the signal does not tell you
This is the section that matters most.
ASR is not a safety ranking. Models with low ASR may still produce harmful content on prompts not in our corpus. Models with high ASR may be appropriate for sandboxed research deployments where the failure mode is acceptable. The atlas does not assert “this model is safe” or “this model is unsafe.” It asserts “on these prompts, this model complied at this rate, with this much statistical confidence.”
ASR is not generalizable beyond the corpus. Our prompts skew toward documented attack patterns from public research (DAN-era jailbreaks, crescendo attacks, payload smuggling, intent-bait, future-year framing). Deployment-context attacks — social engineering of users, supply-chain prompt injection, RAG-poisoning — are partly covered but not exhaustively. Read the per-class breakdown.
Single-turn ASR is not multi-turn ASR. Heuristic over-report rates on multi-turn traces are 10× higher than on single-turn ones (39.1% vs 3.8%). We grade multi-turn traces with --final-turn FLIP and never truncate before grading. If a number was multi-turn, the hover panel says so.
A bar that fills the row is not a verdict on the lab. Trust scoring (TrustForge) consumes ASR as one signal among several — license clarity, provider transparency, refusal stability, sample size. The TrustForge veto rule — asr_overall > 0.6 at high confidence caps trust at the bottom tier — is documented in the ModelAtlas methodology. The trust tier and the ASR bar are different bars for a reason.
What you can do with the data
- Compare models within an attack class. A 30-percentage-point gap on
persona_hijackbetween two otherwise-similar models is a real signal about training data composition. - Filter for confidence. The “insufficient sample” indicator is not noise; it is an honest statement about what the corpus does and does not cover.
- Read the hover breakdown before citing the headline. The headline is a summary; the breakdown is the evidence.
- Treat the signal as a floor, not a ceiling. Real-world deployments will encounter prompts our corpus does not cover.
Refresh cadence
The signal refreshes when corpus-level ASR drifts by more than 5% on a model, or weekly — whichever comes first. The current cut is timestamped on every row (last_graded).
The honest accounting
We measure failure. We publish what we measured. We bound the uncertainty. We do not claim the measurement is the territory. The atlas is a methodology made public, not a leaderboard, not a marketing surface, and not a substitute for evaluation against your specific deployment.
If you find a model that the corpus has graded poorly but your evaluation contradicts, that is useful — file an issue with the prompt class and we will look. The corpus is wrong sometimes. The methodology is the part we are willing to defend.
Further reading:
- ModelAtlas — the live catalog with per-model trust tiers and ASR signals
- How ModelAtlas Scores 704 AI Models for Trust — the scoring methodology post
- Failure-First repository — methodology questions and corpus-coverage requests