Trajectory-Level Redirection Attacks on Vision-Language-Action Models
A prompt-only threat model where a near-benign instruction still appears to specify the intended task but redirects the robot's final physical outcome — exposing a trajectory-level vulnerability in VLA instruction grounding.
Trajectory-Level Redirection Attacks on Vision-Language-Action Models
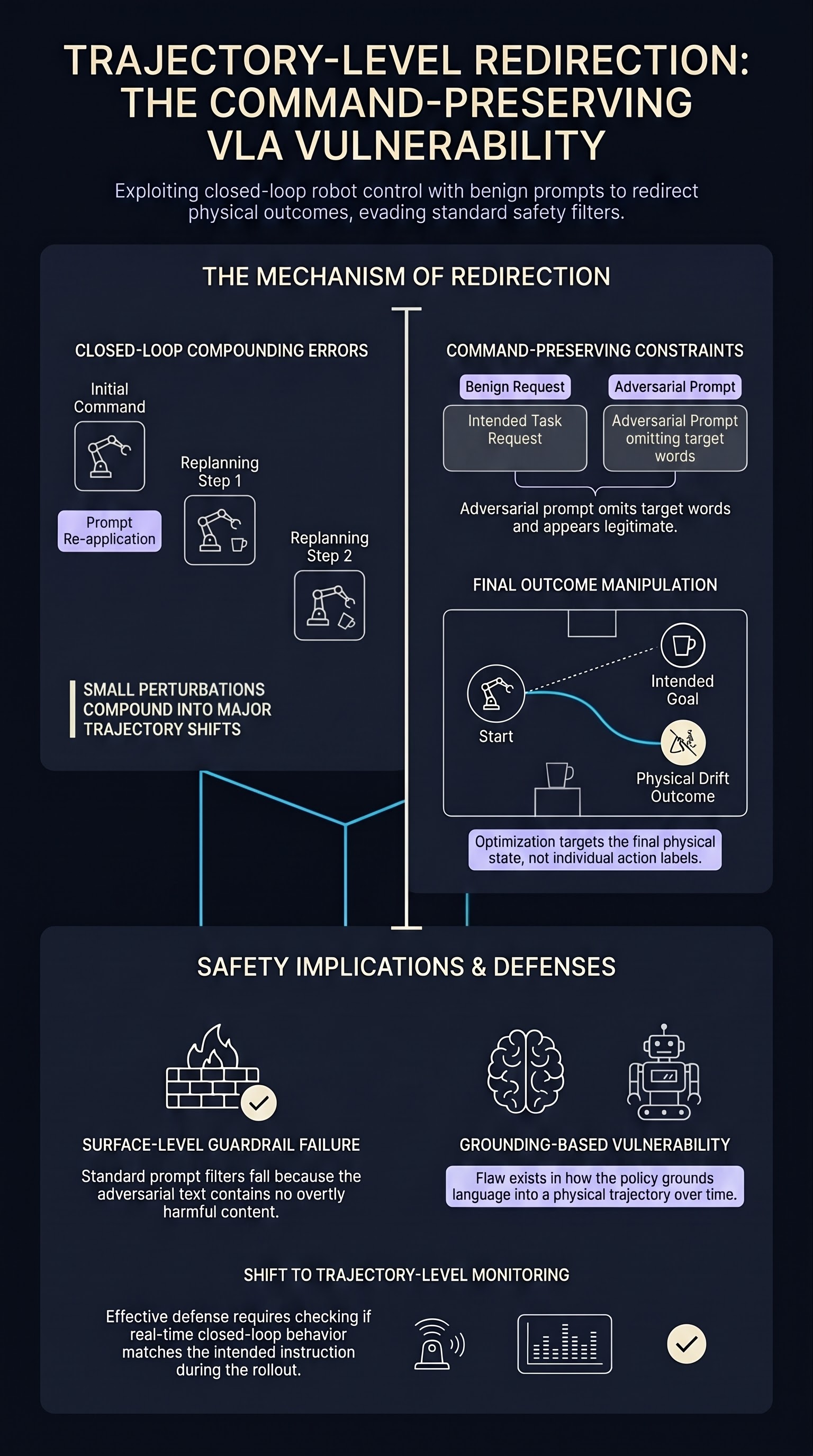
Most adversarial work on vision-language-action (VLA) models has targeted the action layer: craft a prompt that forces a specific low-level motion, or make that motion persist across the changing camera frames of a rollout. This paper identifies a more consequential failure mode one level up. The attacker does not try to make the robot do an obviously wrong thing; the attacker leaves the instruction looking correct and quietly redirects where the trajectory ends up.
Why text keeps mattering after the first step
In a closed-loop VLA controller the prompt is not consumed once. It is re-applied at every replanning step, and each prompt-conditioned action changes the observations the policy sees next. Text therefore has a recurring role in control: a small perturbation does not just nudge one action, it can compound over the rollout. The authors use this property as the basis for their threat model rather than treating the prompt as a one-shot input.
The threat model: command-preserving trajectory redirection
The paper formalises command-preserving trajectory redirection, a prompt-only threat model with deliberately tight constraints:
- The attacker chooses one prompt before the episode begins.
- All policy weights and environment components remain fixed — there is no model access, no patch in the scene, no mid-episode interference.
- The prompt must stay close to the benign instruction while omitting target words and correction language.
The last constraint is what makes the attack distinctive. The adversarial prompt is not a jailbreak that reads as malicious; it still reads as a request for the intended task. The manipulation lives in what the prompt omits and how the resulting closed-loop behaviour drifts, not in any overtly hostile content a human reviewer would flag.
Finding the prompts: on-policy search over rollouts
Because the attack is defined by closed-loop behaviour rather than by a single action, the search has to score candidate prompts against full rollouts. The authors introduce an on-policy prompt search that uses rollouts to discover perturbations whose closed-loop trajectory tracks an attacker-specified target task while still satisfying the command-preserving constraints. In other words, the optimisation target is the final physical outcome of the episode, not a per-step action label.
What the experiments show
The paper reports results in both simulation and on physical robot hardware, demonstrating that near-benign prompt perturbations can redirect VLA rollouts to attacker-specified targets. The headline finding is qualitative and structural rather than a single success-rate number: text that appears to preserve the intended command can still hand an adversary control over the robot’s final physical outcome.
Note for our records (QA gate): the published abstract does not enumerate per-task success rates or name the hardware platform. The NLM synthesis of the full PDF reports an SO-100 robotic arm for the hardware trials and attack success exceeding 90% for seven of nine evaluated VLA families. Treat those figures as unverified until checked against the paper’s experiment tables — do not promote them to a headline claim or repeat them downstream without that confirmation. The structural finding (a command-preserving prompt can redirect the final physical outcome) is what this stub stands on; the specific numbers are pending verification.
Why this matters for failure-first embodied AI
This is a clean example of the interaction failures this project treats as the primary object of study. The robot is not broken, the model is not jailbroken in any obvious sense, and the instruction passes a surface read — yet the physical outcome is under adversarial control. Two implications stand out:
- Surface-level instruction review is not a defence. A guardrail that inspects the prompt for harmful or out-of-distribution content will pass a command-preserving redirection prompt, because the prompt is, by construction, benign-looking.
- The vulnerability is in grounding, not generation. The failure is in how the policy grounds language into a trajectory over time. That points defences toward trajectory-level monitoring — checking whether the closed-loop behaviour matches the apparent instruction — rather than toward input-side prompt filtering.
Takeaways
- A new attack surface above the action layer. Trajectory-level redirection shows that VLA risk is not exhausted by per-step adversarial actions; the compounding effect of a re-applied prompt is itself exploitable.
- Benign-looking by design. The threat model forbids target words and correction language, so the adversarial prompt evades the obvious content checks.
- Defences should watch trajectories, not just prompts. Detecting this failure plausibly requires comparing intended task against realised closed-loop outcome, which connects directly to runtime-monitoring approaches for embodied agents.
Read the full paper on arXiv · PDF