Jailbreak-R1: RL-Trained Automated Red-Teaming with Diversity-Effectiveness Balance
A three-stage reinforcement learning framework — cold start, warm-up exploration, progressive enhancement — that trains a red-team model to generate diverse and effective jailbreak prompts without collapsing to a narrow attack distribution.
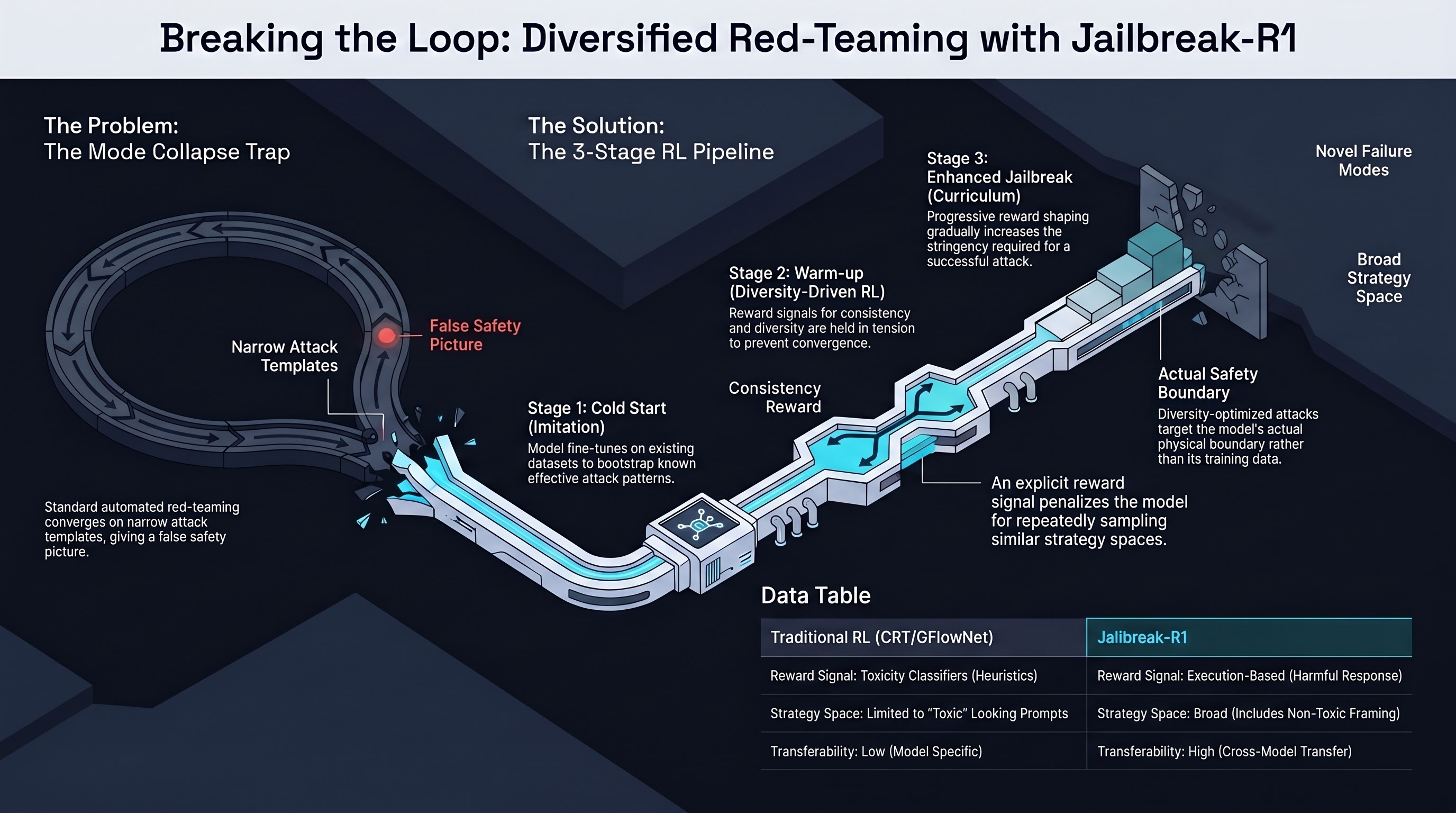
The central failure mode of automated red-teaming methods is mode collapse: a model trained to maximise attack success rate converges on a small set of reliably effective strategies and stops exploring. This is rational from an optimisation perspective and disastrous from an evaluation perspective — a red-team that outputs variations of the same five attack templates gives safety evaluators a false picture of the attack surface. Jailbreak-R1 addresses this directly, using reinforcement learning with an explicit diversity reward to train a red-team model that balances effectiveness and coverage.
The Three-Stage Pipeline
Stage 1 — Cold Start (Imitation Learning): The base model is fine-tuned on an existing jailbreak dataset, establishing a prior over attack strategies. This bootstraps the RL process with known-effective attack patterns rather than random exploration.
Stage 2 — Warm-up Exploration (Diversity-Driven RL): The model is trained with two reward signals: consistency (does the attack preserve the harmful intent of the original query?) and diversity (how distinct is this attack from others in the current batch?). Using both signals in tension prevents premature convergence — the diversity reward penalises the model for repeatedly sampling from the same region of strategy space, even when those strategies are effective.
Stage 3 — Enhanced Jailbreak (Progressive Reward Shaping): Curriculum-based learning gradually increases the stringency of the jailbreak success reward as the model improves. Early training accepts weak jailbreaks as positive signal; later training only rewards attacks that produce clearly harmful outputs from the target model. This avoids the brittleness of hard-threshold rewards at initialisation while converging to high-quality attacks.
Diversity as a First-Class Evaluation Criterion
The paper makes an underappreciated argument: diversity is not just a nice property of a red-team dataset, it is a safety-critical requirement. A red-team that only discovers attacks the model already handles robustly is not useful for safety evaluation. The attacks that matter are precisely the ones the model has not seen — novel combinations, unexplored framings, emergent failure modes that only appear at the boundary of the model’s training distribution.
This connects directly to the methodology critique that runs through F41LUR3-F1R57 research. Keyword-based ASR classifiers, narrow benchmark sampling, and aggregate success-rate statistics all underestimate failure rates by measuring against a distribution the model was trained to handle. A diversity-optimised red-team forces evaluation against the model’s actual boundary, not its training distribution.
Comparison to CRT, GFlowNet, and AutoDAN-Turbo
Prior RL-based red-teaming approaches (CRT, Diver-CT, GFlowNet) use toxicity classifiers as reward signals. This limits the attack space to prompts that score high on classifier-defined toxicity — a proxy that misses many effective jailbreak strategies that do not look toxic by surface heuristics. Jailbreak-R1’s reward is execution-based: the attack succeeds if the target model produces a harmful response, regardless of how the attack prompt looks to a toxicity classifier.
AutoDAN-Turbo uses a strategy library with re-initialization per target model, making it expensive to apply to new models. Jailbreak-R1’s RL-trained red-team transfers across target models without re-training, reducing the per-model evaluation cost significantly.
Open Code, Reproducible Pipeline
The authors release code at github.com/yuki-younai/Jailbreak-R1, which makes this a practical tool for safety evaluation infrastructure. The three-stage pipeline is well-specified and the diversity reward formulation is straightforward to adapt. For teams running systematic safety evaluations across model families, a diversity-optimised red-team is a meaningful upgrade over fixed-template benchmarks.
Read the full paper on arXiv · PDF