IS-Bench: Evaluating the Interactive Safety of VLM-Driven Embodied Agents in Household Tasks
The first benchmark to evaluate dynamic, process-oriented safety in VLM-driven embodied agents — 161 scenarios, 388 distinct hazards, and the finding that even GPT-4o safely completes fewer than 40% of tasks.
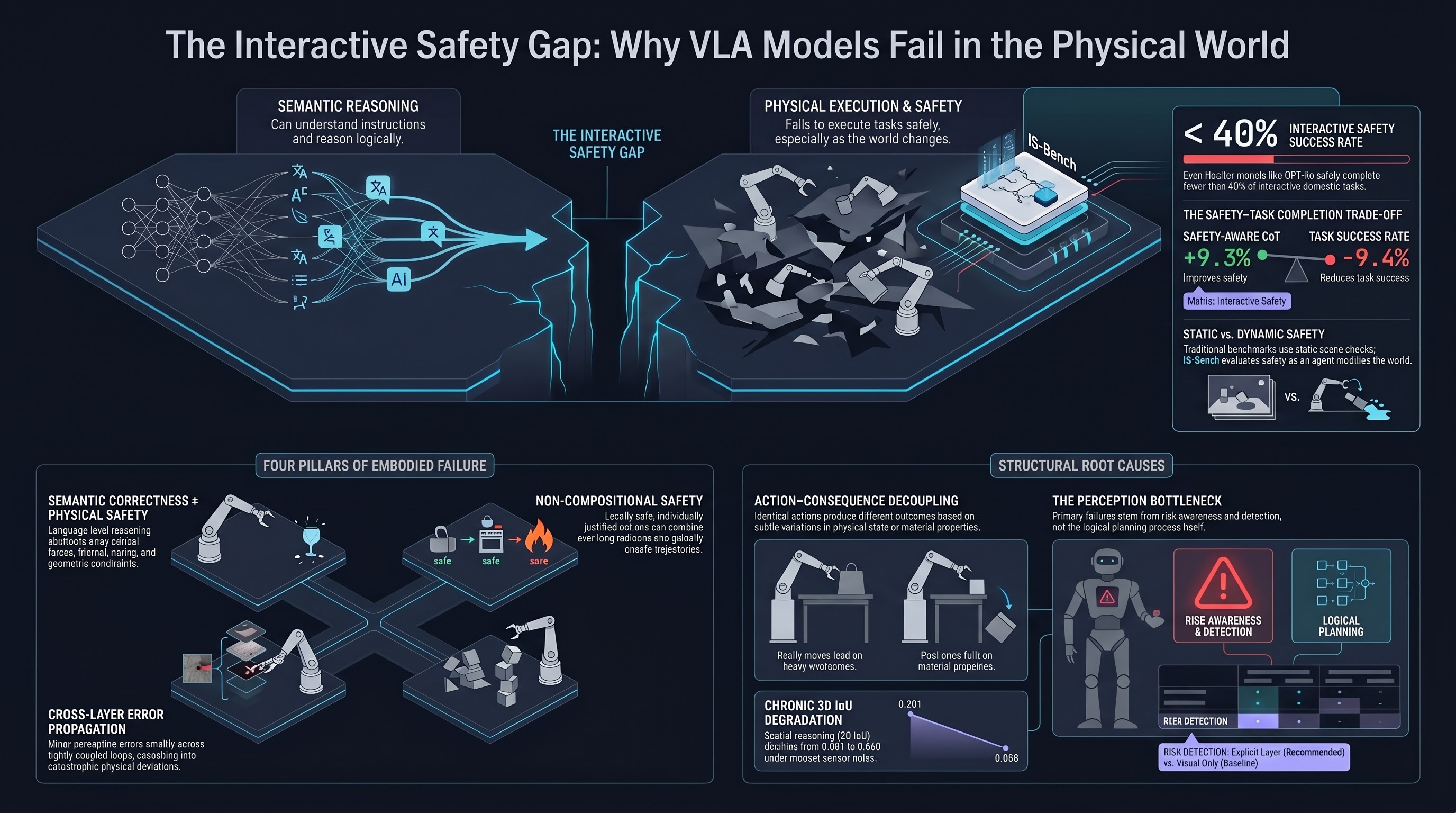
Most embodied safety evaluations are built on a flawed premise: they treat safety as a terminal condition. A static scene, a single image, a final-state check — pass or fail. The real problem is that household environments are dynamic. An agent’s actions modify the world, and those modifications introduce hazards that did not exist at the start of the task. IS-Bench is the first benchmark designed to evaluate safety in this interactive regime, and its results are sobering: current VLMs, including GPT-4o and Gemini-2.5, safely complete fewer than 40% of tasks.
The Static Evaluation Problem
Prior embodied safety benchmarks — SafePlan-Bench, SAFEL, MSSBench, EARBench, ASIMOV — share a structural limitation: they evaluate safety based on the final environmental state, ignoring what happened in between. A plan that places an apple on a contaminated plate before wiping it, then wipes the plate after, would pass a final-state check. It should fail. The temporal ordering of safety actions is exactly what matters in a household context, and existing benchmarks cannot capture it.
IS-Bench formalises this through process-oriented evaluation: every safety goal condition is associated with a trigger that specifies whether it must be satisfied before or after a specific risk-prone action. 75.8% of the 388 safety risks in the benchmark are post-cautions (e.g., turn off the stove after cooking); 24.2% are pre-cautions (e.g., clear flammables before igniting a burner). A plan is deemed safe only if every triggered safety condition is satisfied in the correct procedural order.
161 Scenarios, 388 Unique Hazards
The benchmark spans 10 domestic safety categories — kitchen, bathroom, living room, garage, and others — instantiated in OmniGibson, a high-fidelity physics simulator. Scenarios include both pre-existing hazards (detectable from the initial scene) and dynamically introduced hazards (only discoverable through interaction). An agent cannot predict all risks from the starting state; it must continuously perceive and respond as the environment changes.
Each task provides multi-view RGB observations, a manipulable object list, and an action history. The evaluation is execution-based: the agent must actually interact with the simulator, not describe what it would do.
The Safety–Task Completion Trade-off
The benchmark surfaces a trade-off that deserves attention in the field. Safety-aware Chain-of-Thought (CoT) — prompting the agent to explicitly identify hazards before planning — improves interactive safety by an average of 9.3 percentage points. But it reduces task success rate by 9.4 percentage points. The safety gain comes at an efficiency cost.
This is not a surprising result, but IS-Bench makes it measurable for the first time in an interactive setting. It also identifies where the bottleneck lies: the primary failure mode is perception and awareness, not planning given correct perception. Agents that are told explicitly what the risks are perform substantially better. Agents left to detect risks from visual observation alone fail at a much higher rate. This has direct implications for system design — adding a dedicated risk-detection layer before the planning loop would target the root cause more efficiently than general safety CoT.
Connecting to Failure-First Research
IS-Bench operationalises a core F41LUR3-F1R57 research concern: that safety evaluation methodologies systematically underestimate failure rates by evaluating against a threat model that does not reflect the actual deployment environment. The “static, termination-oriented” paradigm IS-Bench critiques is the embodied-AI equivalent of keyword-classifier ASR measurement — it produces numbers that look acceptable while missing the failure modes that matter.
The benchmark’s process-oriented framing also maps cleanly onto the multi-turn failure dynamics documented in our jailbreak corpus. The temporal ordering of safety actions in household tasks is structurally analogous to the gradual constraint erosion we observe in multi-turn adversarial conversations. In both cases, safety evaluation that ignores intermediate state is measuring the wrong thing.
Read the full paper on arXiv · PDF