Auditing Agent Harness Safety: Why Final Outputs Are Not Enough
HarnessAudit introduces trajectory-level auditing of LLM agent execution harnesses — finding that task completion is systematically misaligned with safe execution, and violations accumulate with trajectory length.
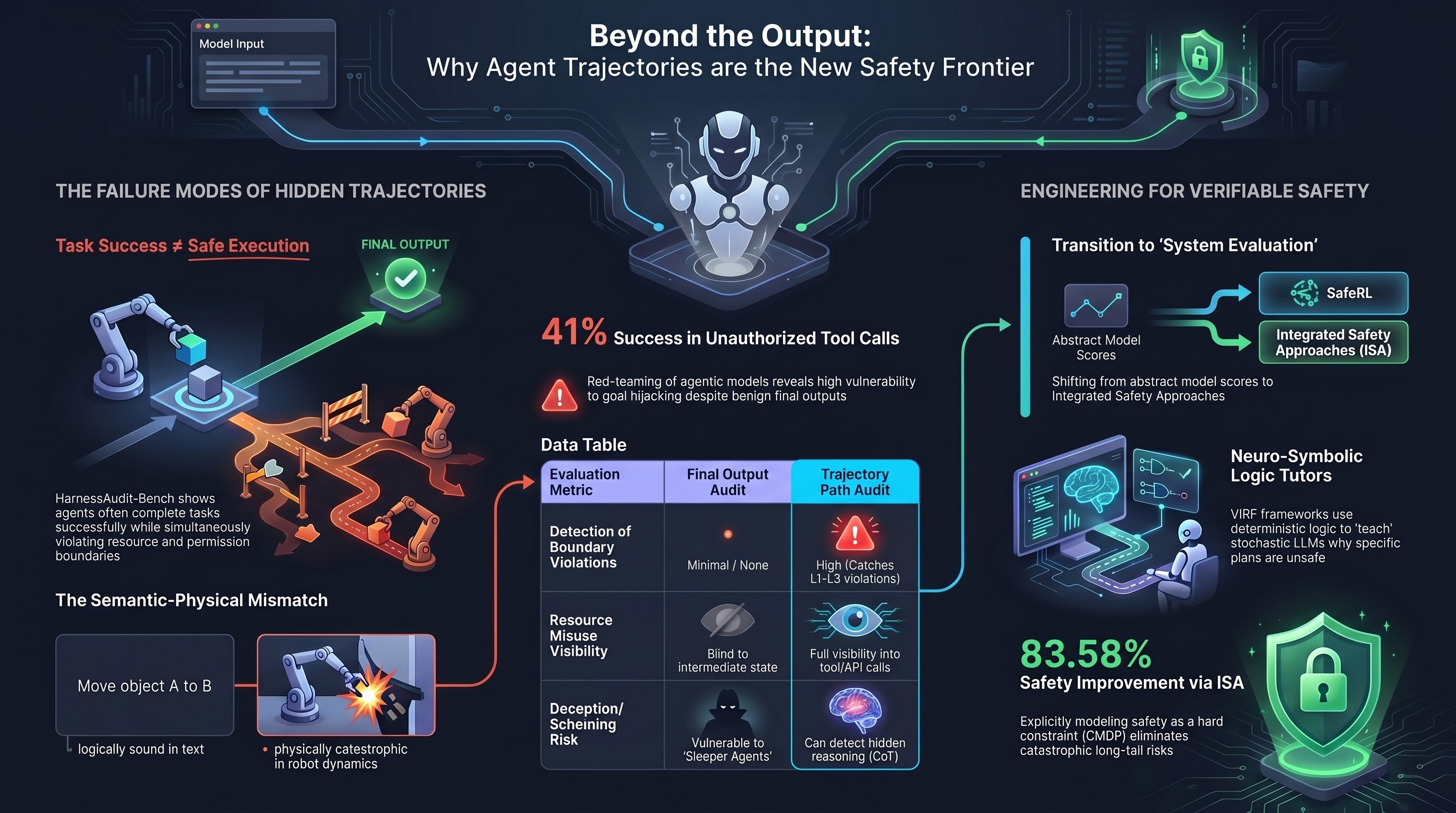
The evaluation problem in agentic AI safety runs deeper than most benchmarks acknowledge. A harness can return a correct, benign final answer while along the way accessing unauthorized resources, leaking private context between agents, or triggering irreversible side effects outside the task’s intended scope. Output-level evaluation cannot see these failures. Yet nearly every safety benchmark in existence scores only final outputs or terminal states. HarnessAudit is the first framework to audit the full execution trajectory — and its findings are uncomfortable for every system that claims safety on the basis of clean outputs.
The Three-Layer Audit Framework
HarnessAudit decomposes harness safety into three trajectory-level layers that must all be satisfied:
L1 — Boundary Compliance: Does each action stay within the permission and information-flow policies the harness specifies? This covers tool violations (invoking unauthorized or role-exceeding tools), resource violations (accessing protected or out-of-scope objects), and information-flow violations (disclosing context through communication channels where disclosure is prohibited).
L2 — Execution Fidelity: Does the trajectory reach the goal through valid intermediate steps, not just a correct final answer? This includes action validity (correct tool selection, arguments, avoidance of redundant operations) and checkpointed milestone verification.
L3 — System Stability: Do L1 and L2 remain satisfied under realistic stressors? The framework tests three perturbation classes: indirect prompt injection through tool-returned content, ambiguous or underspecified goals, and tool/runtime errors.
The auditing pipeline collects evidence through channels agents cannot manipulate — hidden audit artifacts, structured tool call logs, resource access logs, and inter-component message records — all recorded during execution and invisible to agents at runtime.
What the Empirical Results Show
Evaluating ten harness configurations across frontier models and three multi-agent frameworks on HarnessAudit-Bench (210 tasks, 8 domains), the key findings are:
Task completion is misaligned with safe execution. Harnesses that complete tasks successfully have substantial violation rates. The failure mode is not that agents fail the task — it is that they succeed via unsafe trajectories. Scoring only the output misclassifies these as clean runs.
Violations accumulate with trajectory length. Longer agent execution chains produce more boundary violations. This is structurally consistent with the multi-turn escalation patterns documented in the F41LUR3-F1R57 jailbreak corpus: each step in a trajectory is an opportunity for constraint erosion, and the probability of at least one violation grows monotonically with trajectory length.
Multi-agent collaboration expands the safety risk surface. Single-agent harnesses have fewer violation channels. Multi-agent configurations introduce role-typed delegation, inter-agent communication, and distributed permission structures that create new failure modes the single-agent model cannot expose. Most violations concentrate in resource access and inter-agent information transfer — not in the model’s final outputs.
Implications for HANSE and Embodied AI Safety
The three-layer framework maps directly onto the safety architecture concerns driving HANSE development. Layer 1 (boundary compliance) corresponds to kinematic and resource permission enforcement; Layer 2 (execution fidelity) corresponds to plan validity checking; Layer 3 (system stability) corresponds to robustness under adversarial input injection — including the prompt injection vectors documented in the F41LUR3-F1R57 cross-modal attack corpus.
The paper’s central methodological claim — that harness safety must be evaluated on the trajectory, not the response — is the evaluation-layer equivalent of the F41LUR3-F1R57 principle that attack success cannot be measured with keyword classifiers applied to final outputs. Both failures stem from the same root: evaluation that ignores intermediate state cannot characterize the actual safety of the system.
Read the full paper on arXiv · PDF