Multi-Agent Embodied Autonomous Driving: From V2X Information Exchange to Shared World Models
Autonomous driving is shifting from isolated vehicle intelligence toward multi-agent embodied systems that share perception, infer intent, and coordinate action under uncertainty.
Multi-Agent Embodied Autonomous Driving: From V2X Information Exchange to Shared World Models
1. Introduction: The Limits of the “Lone Wolf” Vehicle
For the last decade, the industry has chased a self-driving mirage: the idea that a “Lone Wolf” vehicle, sufficiently armored with sensors and local compute, can solve the chaos of the road in isolation. While this single-agent paradigm has enabled significant progress in structured settings, we are now hitting the asymptotic performance limits of self-contained systems. As a recent comprehensive review of over 380 publications in the field suggests (Hu et al., 2026), the transition from isolated autonomy to collaborative intelligence is no longer optional—it is the prerequisite for Level 5 safety.
The fundamental constraint is partial observability. Even the most sophisticated LiDAR or camera suite cannot see through a lead vehicle or around a blind corner. In complex urban environments, relying solely on an ego-centric viewpoint leads to “reactive” behaviors where the system realizes a hazard exists only after it is physically visible, often too late to avoid a collision. To overcome this, we must shift toward a “Shared Brain” architecture where the perceptual horizon is extended through the collective eyes of the fleet.
2. From “Exchanging Data” to “Sharing a Mind”
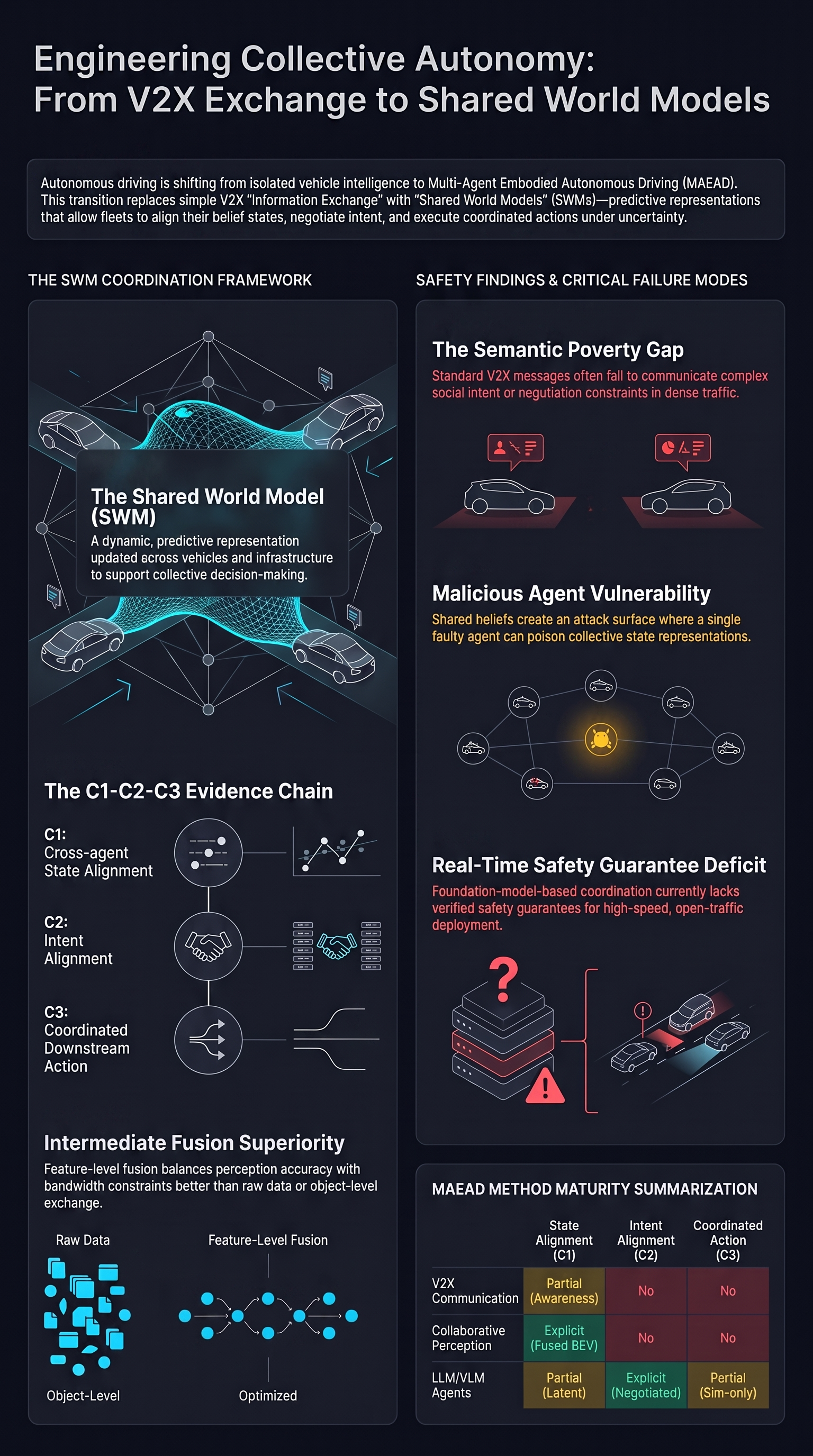
The industry is moving beyond traditional Vehicle-to-Everything (V2X) Information Exchange toward a new era: Multi-Agent Embodied Autonomous Driving (MAEAD). The core distinction lies in how agents interact. In the old model, communication was a supplementary “patch” to fix local errors. In the MAEAD paradigm, agents are active participants co-constructing a Shared World Model (SWM)—a joint, predictive representation of reality.
V2X Information Exchange vs. Shared World Models
| Aspect | V2X Information Exchange | Shared World Models (SWMs) |
|---|---|---|
| Communication Goal | Exchanging status messages and discrete sensor features | Co-constructing aligned predictive representations |
| Representation Type | Fixed message formats (object lists, kinematics) | Dynamic, probabilistic models of the environment |
| Coordination Depth | Loosely coupled, independent decision-making | Joint reasoning and coordinated downstream action |
3. The Three Flavors of Collaborative Perception
To build a shared mind, we must decide at what stage of the neural pipeline agents should collaborate. The literature identifies three primary fusion paradigms, each defined by the trade-off between information richness and communication overhead:
- Early Fusion (Raw Data Fusion): Agents share raw sensor streams (e.g., LiDAR point clouds) before any feature extraction occurs.
- Pro: Maximum information preservation; essential for detecting small or heavily occluded objects that a single agent might filter out as noise.
- Con: Extreme bandwidth requirements and high sensitivity to micro-second time synchronization and extrinsic calibration errors.
- Intermediate Fusion (Feature-Level Fusion): This is the current industry “sweet spot,” utilizing models like V2X-ViT and CoBEVT. Agents share compact, learned representations, such as Bird’s Eye View (BEV) feature maps.
- Pro: Efficiently balances perception quality with significantly lower communication overhead; allows for distilled collaboration as seen in the evolution from V2VNet to DiscoNet.
- Con: Requires robust domain alignment to handle heterogeneous hardware and pose noise across different vehicles.
- Late Fusion (Object-Level Fusion): Agents share final perception outputs, such as 3D bounding boxes and velocities.
- Pro: Minimal bandwidth and high robustness to heterogeneous hardware; easiest to deploy with legacy V2X protocols.
- Con: “Information poor”; if a hazard is missed by all local detectors due to extreme occlusion, the collective remains blind to it.
4. The “Perception-Reasoning-Action” Loop
Shared intelligence is not a static data dump; it is a continuous, circular process. The MAEAD architecture functions as a recurrent loop where communication, reasoning, and action feed into one another. As agents collect local observations and query peers, they update the SWM. This shared state then supports intent-aware negotiation and joint planning.
Crucially, as highlighted in the foundational MAEAD framework (Figure 2), this loop is anchored by a Safety and Audit Layer. This layer is responsible for managing uncertainty and provenance—ensuring that every piece of information in the shared mind is indexed by its source and reliability score before it influences a steering command.
A Shared World Model (SWM) serves as the group’s shared representational workspace. It aligns what agents believe about scene geometry, dynamic actors, and occlusions into a probabilistic map that supports collective decision-making.
5. Grounding the Future: LLMs and Generative World Models
The next evolution of the “Shared Brain” involves two types of grounding that turn raw data into actionable intelligence:
- Semantic Grounding via LLMs/VLMs: Large Language Models and Vision-Language Models allow for “inspectable negotiation.” Rather than just exchanging coordinates, vehicles can communicate high-level intent, social context, and “plan critiques.” Systems like V2X-UniPool demonstrate how knowledge pooling allows the fleet to reason about complex traffic laws or rare social norms that traditional planners might overlook.
- Predictive Grounding via Generative Models: Models like GAIA-1 or DriveGen allow the fleet to “imagine” the future. By simulating environmental dynamics and “rare-event” scenarios—such as a pedestrian appearing from behind a bus—the fleet can test whether a joint plan remains safe across multiple possible futures before a single tire moves.
6. The Safety Checklist: Navigating the “Open-Set” Reality
We must solve the “Open-Set” challenge: interacting with human drivers and legacy vehicles that do not share our digital protocols. This requires the fleet to infer the intent of unknown actors solely through motion observation while defending against more sophisticated threats.
Safety & Security Warning: Consensus-Level Attacks In a shared-world-model paradigm, the attack surface shifts from individual sensors to the collective belief. A malicious agent could perform data fabrication or LiDAR spoofing to manipulate the “shared mind.” Future systems must employ Byzantine-resilient consistency checks to audit received features against physical reality and peer observations. Without this, a single compromised agent could lead an entire fleet into a coordinated failure.
7. Conclusion: Three Key Takeaways for the Industry
The shift from “lone wolf” vehicles to multi-agent systems is the only viable path to solving the “corner case” problem at the heart of Level 5 autonomy. Hybrid architectures—combining deep learning with rule-based safety filters—remain the most scalable implementation path.
TL;DR: The MAEAD Roadmap
- State Alignment is Step One: Coordination is impossible without a shared state. Perfecting intermediate fusion—sharing sparse, relevant features—is the prerequisite for joint reasoning.
- Generative AI as the Ultimate Testbed: World models are the ultimate data engines. They allow us to validate rare-event scenarios that are too dangerous or statistically improbable for real-world testing.
- Human-Centric Social Compliance: Autonomy must be “socially legible.” We will succeed only when our systems can interpret implicit human cues and yield to the informal social norms of the road as naturally as a human driver.
Read the full paper on arXiv · PDF