Learning of Robot Safety Policies via Adversarial Synthetic Scenarios
An agentic gamification framework treats robot safety discovery as a Red Team vs. Blue Team game, surfacing the long-tail hazards that random simulation and manual enumeration miss.
Gamifying Robot Safety: Adversarial Red-Teaming for the Modern Home
Introduction: The Safety Gap in Physical AI
The rapid proliferation of Vision-Language-Action (VLA) foundation models has fundamentally expanded the functional horizons of robotics. Today, Physical AI can interpret natural language and adapt to unstructured environments like homes or hospitals with remarkable agility. However, as a Principal Researcher in Adversarial Robustness, I must highlight the critical “safety gap” that persists: modern models are heavily optimized for functional correctness—the ability to complete a task—but lack grounded “hazard awareness.”
In the stochastic and often chaotic nature of domestic spaces, a robot’s action can be linguistically and functionally “correct” while remaining physically catastrophic. This discrepancy arises because current state-of-the-art models often lack the systematic grounding required to understand safety-critical decision boundaries. To bridge this gap, we propose an “agentic gamification” framework. By reframing safety discovery as an adversarial game, we can move beyond static rules toward dynamic, learned safety envelopes that are resilient to the distributional shifts of the real world.
The Combinatorial Explosion: Why Manual Testing Fails
Ensuring safety in personalized human spaces is not merely a difficult engineering problem; it is theoretically insufficient to rely on manual enumeration. We are faced with a Combinatorial Explosion Challenge where the scenario space is effectively the Cartesian product of near-infinite variables.
Key factors driving this explosion include:
- Objects: Astronomical variations in geometry, pose, fragility, and physical state (e.g., a ceramic mug vs. a porcelain heirloom).
- Robot Actions: Multi-modal grasp types, force application thresholds, and trajectory velocities.
- Environmental Conditions: Dynamic lighting, floor friction coefficients, and transient layout changes.
- Human Behavior: The unpredictable movements of children, pets, and bystanders.
Random sampling and manual testing inevitably fail to capture the “long-tail” edge cases that define the boundary between safe and unsafe. For example, a robot might successfully place a container on a table ten thousand times, yet fail in the 10,001st instance due to a specific intersection of a low-friction surface, a misestimated table edge, and an external vibration. These rare, high-impact events are precisely the out-of-distribution (OOD) risks that adversarial red-teaming is designed to uncover.
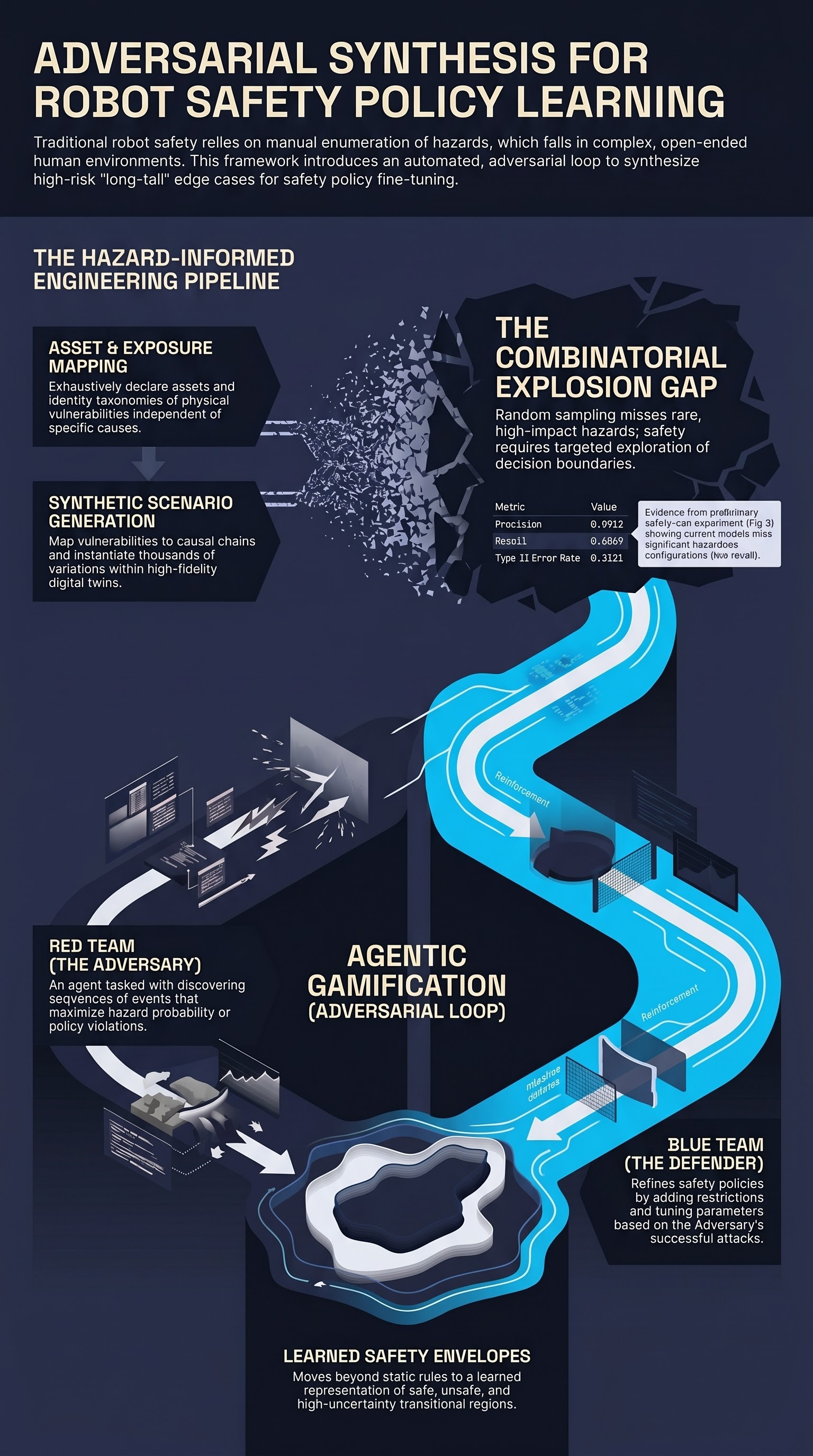
The Five-Step Hazard-Informed Pipeline
To transition from informal safety knowledge to a formally auditable methodology, we utilize a five-step hazard-informed pipeline. This framework provides the structure necessary to integrate classical safety engineering into modern ML workflows.
| Step | Phase | Objective |
|---|---|---|
| Step 1 | Exhaustive Asset Declaration | Enumerate every entity requiring protection (human bystanders, hardware components, and the environment). |
| Step 2 | Exposure Modes | Develop a taxonomy of weaknesses independent of cause (e.g., human limb exposure to moving actuators). |
| Step 3 | Hazard Scenario Definition | Map abstract vulnerabilities to causal chains (e.g., sensor occlusion leading to a failure in collision avoidance). |
| Step 4 | Synthetic Data Generation | Construct digital twins and generate thousands of annotated variations including sensor noise and occlusions. |
| Step 5 | ML Fine-tuning | Train models to represent the “safety envelope,” distinguishing between safe, unsafe, and transitional states. |
Agentic Gamification: Red Team vs. Blue Team
The primary bottleneck in safety engineering is not the learning of scenarios, but their discovery. To solve this, we deploy Agentic Gamification as the engine for Step 3 and Step 4 of our pipeline. By reframing discovery as a two-player adversarial game, we drive the system toward boundary-seeking behavior that manual simulation cannot replicate.
The Red Team (Adversary): This agent’s objective is to discover sequences of events that result in harm or policy violations within the constraints of physics. Whether controlled by a human expert or a reward-maximized AI, the Red Team is incentivized to find creative, subtle failure modes—such as finding the exact angle of approach that causes a vessel to tip.
The Blue Team (Defender): Representing the robot’s safety policy, this agent must refine constraints and tune parameters to mitigate the Red Team’s successes. The Blue Team updates the safety envelope to close the gaps exposed during adversarial play.
The Game Loop: This iterative engine functions in continuous rounds. The Red Team proposes a scenario; if it results in a hazard, the Blue Team must update the policy. The Red Team is then forced to find even more sophisticated OOD scenarios to bypass the new defense. This loop continues until the system converges on a robust, battle-tested safety policy. To ensure scalability for home deployment, we construct the necessary digital twins using commodity hardware, such as smartphone cameras, allowing for rapid environment-specific mapping.
From Rules to Envelopes: Integration with Machine Learning
The adversarial traces—capturing initial scenes, action sequences, and outcomes—provide the high-density data required for robust model training. This methodology facilitates a shift from brittle, rule-based safety to a learned safety envelope.
This data supports two primary integration paths:
- In-Context Learning (ICL): Providing the robot with “negative examples” at inference time to condition safer behavior without requiring weight updates.
- ML Fine-tuning: Updating model parameters to ensure the system inherently recognizes the safety-critical decision boundaries of its specific environment.
By focusing on the transitional regions of the state-action space, the robot develops a nuanced understanding of risk rather than a binary “safe/unsafe” toggle.
Proof of Concept: The “Can on Table” Experiment
To validate this approach, we conducted a study using the Webots simulator focusing on the “Can on Table” placement task. We used synthetic data to teach a robot to recognize falling hazards based on placement proximity to the table edge.
The resulting frame-level metrics were:
- Precision (0.9913): High precision ensures that when the model identifies a hazard, it is almost certainly correct, preserving operator trust.
- Recall (0.6869): The model missed approximately 31.3% of hazardous configurations.
From an adversarial robustness perspective, this 31% false-negative rate represents an unacceptable risk profile for domestic robotics. This “recall deficit” occurs because naive simulations fail to populate the critical decision boundaries—the literal edges of the table—where the difference between safe and unsafe is measured in millimeters. This result serves as a formal mandate for the Red Team: we must use targeted adversarial generation to find these “boundary cases” that random sampling misses.
Current Landscape: Literature Overview
Our framework aligns with and extends several key developments in the field of safe embodied AI:
- InCoRo: Employs real-time perceptual updates to adapt LLM-driven plans to novel tasks.
- SCARED: Notable for pioneering “safe in-context reinforcement learning,” allowing agents to maintain safety budgets and adapt to OOD tasks without the risks associated with immediate parameter updates.
- SELP: Integrates LLM planning with Linear Temporal Logic (LTL) to prune unsafe actions, providing a layer of formal verification that complements our empirical discovery process.
Conclusion and Key Takeaways
Bridging the safety gap in Physical AI requires a paradigm shift from manual enumeration to systematic, adversarial discovery. By gamifying the search for failure, we can ensure that as robots move into our homes, they are prepared for the “long-tail” risks that define real-world interaction.
Executive Takeaways:
- Adversarial Superiority: Manual and random testing are theoretically insufficient for high-dimensional home environments. Adversarial discovery is the only scalable path to identifying rare, high-impact failures.
- Boundary-Seeking Discovery: The value of the Red Team lies in its ability to target the “decision boundary,” reducing the unacceptable 31% Type II error rates found in standard synthetic training.
- Scalable Deployment: By utilizing commodity hardware (smartphones) for digital twin construction, we enable home-specific safety grounding that can be performed at the point of deployment.
- Systematic Alignment: Future robotics must move toward “learned safety envelopes” that provide an auditable and transparent methodology for protecting human and environmental assets.
The ultimate goal of this research is systematic alignment: ensuring that the robots of the future are not only functionally capable but are inherently robust within the personalized, stochastic spaces of our daily lives.