From Signal Degradation to Computation Collapse: Uncovering the Two Failure Modes of LLM Quantization
Post-Training Quantization (PTQ) is critical for the efficient deployment of Large Language Models (LLMs).
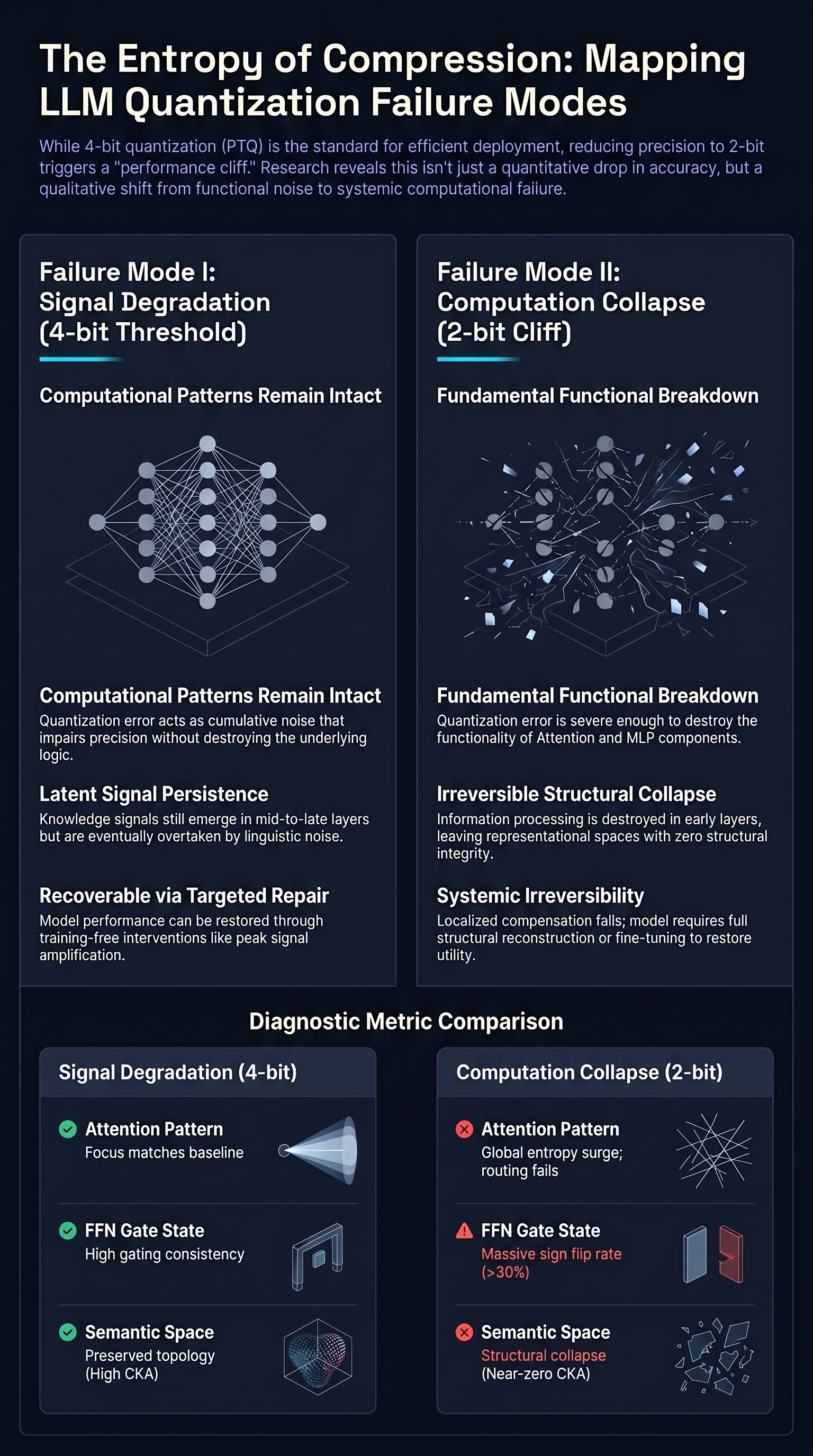
From Signal Degradation to Computation Collapse: Uncovering the Two Failure Modes of LLM Quantization
Introduction: The Mystery of the Performance Cliff
In the current landscape of AI deployment, Post-Training Quantization (PTQ) serves as the primary gateway for making Large Language Models (LLMs) computationally viable. For years, the industry has operated within the “4-bit sweet spot,” where models maintain impressive performance despite aggressive compression. However, as we push toward 2-bit precision, we encounter a “performance cliff” where model utility does not merely degrade—it vanishes entirely.
Data from factual recall tests using the Pararel dataset on Llama-3.1-8B illustrates this phenomenon with striking clarity. While the transition from FP16 to 4-bit precision shows a manageable decline in accuracy, the shift to 2-bit triggers a catastrophic collapse where accuracy plummets to zero. As researchers, we must ask: Is 2-bit failure just a more extreme version of the precision loss seen at 4-bit, or are we witnessing a fundamental qualitative shift in the model’s internal computational logic?
The Two Failure Modes Hypothesis
New mechanistic research suggests that the “performance cliff” marks a transition between two fundamentally different types of internal failure. Rather than a linear decline in precision, models exhibit a qualitative divergence in how they handle information flow.
| Mechanism | Failure Mode I: Signal Degradation | Failure Mode II: Computation Collapse |
|---|---|---|
| Primary Mechanism | Cumulative quantization error acting as additive noise. | Fundamental damage to key functional components. |
| Internal Effect | Computational patterns remain intact; information precision is impaired. | Key components (Attention/FFN) fail to function; signal destroyed in early layers. |
| Outcome | Correct information is present but weakened (Recoverable). | Total breakdown of processing; signal is absent (Irreversible). |
These modes are not just quantitative differences in bit-width; they represent a breakdown of the model’s structural and functional integrity.
Phenomenological Evidence: Answer Rank vs. Answer Collapse
The distinction between these modes is visible in how models rank correct answers in their output distributions.
- Answer Rank Drop (4-bit): In 4-bit models, the correct answer often shifts downward—for example, moving from the top spot to the Top-5. While the model might ultimately sample the wrong token, the “correct” signal remains decodable and high in the distribution.
- Answer Rank Collapse (2-bit): In 2-bit models, the rank of the correct answer typically falls into the thousands, effectively vanishing into random noise. At this stage, the model collapses into generating high-frequency stop words like “the” or ”.” regardless of the input.
Logit Lens Analysis By using the “Logit Lens”—projecting intermediate hidden states into the vocabulary space—we can see these dynamics in action. In 4-bit models, a decodable knowledge signal still emerges in the mid-to-late layers, even during failures. In contrast, 2-bit models show a complete absence of signal; the probability of the correct answer remains near zero throughout every single layer, suggesting the signal is never generated at all.
Deep Dive: The Mechanics of a Broken Model
To understand the “why” behind this collapse, we must analyze the Transformer’s internal components through a mechanistic lens.
The Attention Breakdown
Functional attention requires the model to focus its “gaze.” Metrics such as Normalized Attention Entropy and Jensen–Shannon Divergence (JSD) reveal that 2-bit models lose this ability entirely. They exhibit high entropy across all layers, signaling a state of global uncertainty. The JSD surges, showing that the attention focus deviates fundamentally from the FP16 baseline, rendering the model unable to concentrate on relevant tokens.
FFN Memory Failure and Destructive Interference
Feed-Forward Networks (FFN) act as key-value memories where specific “expert” neurons are activated to retrieve factual associations. In 2-bit models, this retrieval system fails catastrophically:
- The SwiGLU Gating Reversal: In architectures like Llama, the SwiGLU activation function is highly sensitive to the sign of the input. We observe Sign Flip Rates exceeding 30% in 2-bit models; these flips fundamentally reverse the neuron’s logical state, turning “active” neurons off and “suppressed” neurons on.
- Expert Retrieval Failure: The Jaccard Index (measuring the overlap of the Top-1% of activated neurons) drops to approximately 0.1. The model is effectively retrieving the wrong “expert” memory.
- Signal Subspace Alignment: Singular Value Decomposition (SVD) reveals a profound insight: 2-bit error is highly aligned (~0.8 similarity) with the original signal subspace. This means the noise isn’t just additive; it is “destructive interference” that actively cancels out the model’s primary features.
Structural Collapse
Using Centered Kernel Alignment (CKA) to compare representational structures, we see that 4-bit models maintain a bright diagonal correspondence to their FP16 versions. However, 2-bit CKA heatmaps appear as a dark purple “structural collapse.” The absence of the diagonal line indicates a total loss of layer-wise correspondence, meaning the model is no longer performing the same transformations as the original.
Intervention: Can We Fix the Damage?
The repairability of a model is strictly dictated by its failure mode.
Repairing Signal Degradation (4-bit)
Because 4-bit failure is cumulative, it can be mitigated through a Two-Stage Repair Strategy:
- Source Protection: We must protect the “dominoes” before they fall. For Llama and Mistral, this means keeping the first few layers (the Early Representation Bottleneck) in 8-bit. For Qwen and Gemma, which show Uniform Degradation, we apply kurtosis-based protection to preserve high-kurtosis weights, as these are the most vulnerable to outlier-induced quantization error.
- Signal Restoration: By identifying the layer with the highest confidence and amplifying its output logits, we can overcome late-stage linguistic noise. This restores the trajectory of the model, bringing Mistral-7B accuracy from 0.00% to 81.26% and Llama-3.1-8B to 75.19%.
The Irreversibility of 2-Bit Collapse
Computation Collapse is systemic. The “First Domino” test demonstrates that quantizing only the first two layers () of Llama-3.1-8B to 2-bit causes accuracy to plummet from 100% to 41.65%. Subsequent high-precision layers cannot “repair” the signal because it is destroyed at the source. Even advanced low-rank compensation (EORA) fails here; you cannot compensate for a component that has become computationally non-functional.
Mechanism-Aware Interventions
- Mixed-Precision Protection: Highly effective for Signal Degradation; fails to stop the systemic destruction of Computation Collapse.
- Logit Amplification: Successfully restores 4-bit signals by overcoming noise; ineffective when the underlying signal is absent (2-bit).
- Structural Reconstruction: Necessary for 2-bit models; requires fine-tuning to rebuild the internal computational pathways from scratch.
Conclusion: Implications for Future AI Deployment
Our research into these failure modes provides three critical takeaways for the future of model compression:
- The 2-Bit Cliff is Qualitative: Catastrophic failure in 2-bit regimes is not just “more noise.” It is a fundamental breakdown of the model’s ability to focus attention, retrieve memory, and maintain structural correspondence with its original self.
- Architecture-Specific Sensitivity: Deployment strategies must account for whether a model exhibits an Early Representation Bottleneck (Llama/Mistral) or Uniform Degradation (Qwen/Gemma) to apply protection effectively.
- Repair vs. Reconstruction: Signal Degradation can be addressed with training-free numerical adjustments. However, “Computation Collapse” requires structural reconstruction through fine-tuning, as the internal logic of the model has been fundamentally compromised.
Addressing the challenges of ultra-low-bit deployment requires a move toward “principled quantization”—an approach that respects the internal mechanistic pathways of the model rather than treating compression as a purely numerical optimization problem.
Read the full paper on arXiv · PDF