XEmbodied: A Foundation Model with Enhanced Geometric and Physical Cues for Large-Scale Embodied Environments
Vision-Language-Action (VLA) models drive next-generation autonomous systems, but training them requires scalable, high-quality annotations from complex environments.
XEmbodied: A Foundation Model with Enhanced Geometric and Physical Cues for Large-Scale Embodied Environments
1. Introduction: The “Hallucination” Problem in Embodied AI
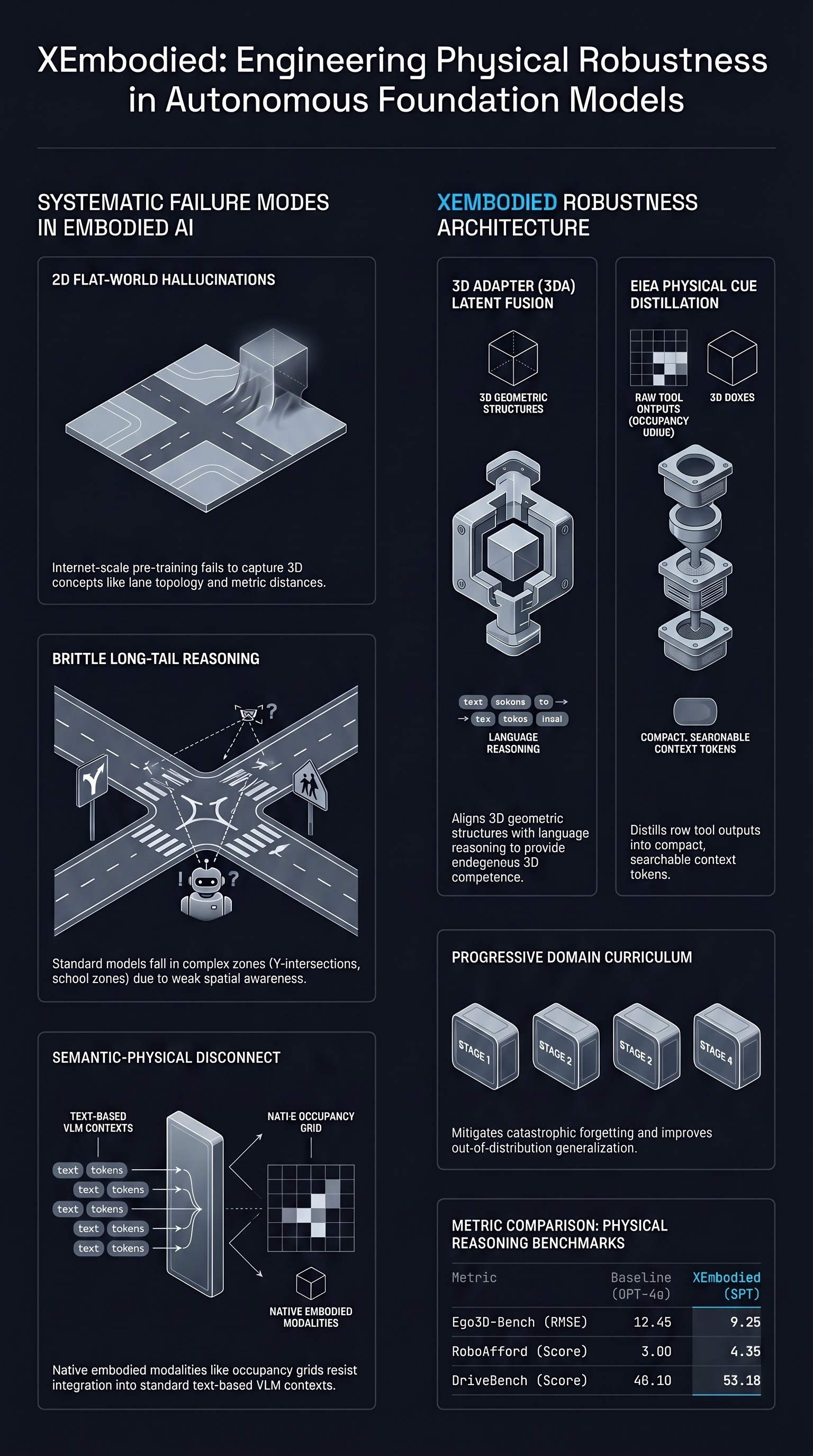
The transition to the “Autonomous Driving (AD) 3.0” era and next-generation robotics hinges on the efficacy of Vision-Language-Action (VLA) models. These systems are tasked with translating complex visual inputs into high-stakes physical maneuvers. However, a significant industrial bottleneck remains: the cloud-side data closed-loop. Current pipelines often rely on weak metadata—such as GPS coordinates or speed—to filter and label vast amounts of collected data, leaving “long-tail” scenarios like Y-shaped intersections, channelization areas, or school zones dangerously under-annotated.
To bridge this gap, a collaboration between Tsinghua University and Xiaomi has produced XEmbodied. Unlike general-purpose Multi-Modal Large Language Models (MLLMs) such as Qwen-VL or LLaVA, which were pretrained on 2D internet data and frequently “hallucinate” spatial relations in safety-critical moments, XEmbodied serves as the essential infrastructure for scalable autonomy. It replaces weak metadata with high-density semantic and 3D reasoning, providing a cloud-side foundation model capable of automated, high-precision labeling and scenario mining.
2. The 2D vs. 3D Gap: Why Standard AI Struggles with Reality
There is a fundamental strategic mismatch between internet-scale 2D pretraining and the requirements of embodied environments. Current VLM pipelines treat geometry as a raw auxiliary channel, whereas human cognition utilizes an endogenous 3D competence—a structured spatial sense derived from multi-source cues.
Standard AI models suffer from:
- Flat-World Representations: A lack of internal concepts for lane topology, metric distances, and occupancy relations, leading to an inability to verify hypotheses against reality.
- Catastrophic Forgetting and OOD Degradation: Naive fine-tuning on driving data often causes models to lose general reasoning capabilities or fail entirely when encountering “out-of-distribution” (OOD) scenarios they did not see during training.
- Semantic-Physical Disconnect: Native physical signals like point clouds or occupancy grids do not naturally fit into the context windows of standard VLMs, leading to brittle reasoning in “long-tail” environments like underground garages or wait zones.
3. The XEmbodied Architecture: Two Breakthrough Adapters
XEmbodied addresses these failures through a modular architecture designed to foster latent 3D thinking by integrating geometric representations directly into the model’s reasoning core.
The 3D Adapter (3DA)
The 3DA acts as the primary geometric connector. It maintains a dual-stream process:
- The Semantic Stream: Utilizes a Qwen3-VL 2D visual encoder to capture high-level object categories and scene attributes (“what”).
- The Geometry Stream: Employs a VGGT 3D visual geometry encoder to extract spatial structures and relations (“where”). To resolve the resolution mismatch between these streams, XEmbodied uses a deterministic interpolation operator to align 3D and 2D grids. These streams are then fused via cross-attention, injecting 3D representations directly into the 2D semantic token stream.
The Efficient Image-Embodied Adapter (EIEA)
The EIEA is a “plug-and-play” tool for physical cues. It takes complex, heterogeneous data—occupancy grids, 3D boxes, and map segments—and processes them through a Mamba-based interpreter. This architectural choice allows the model to process long sequences of tool outputs into a “latent rationale” before distilling them into compact physical cue tokens. This circumvents the interpretability burden on the Large Language Model, allowing for efficient, grounded reasoning without the “messy” sensor data bloat.
The model’s superior performance across these dimensions is evidenced in [SOURCE_IMAGE_1] through [SOURCE_IMAGE_11], which visualize state-of-the-art (SOTA) metrics in Spatial/3D, Embodied/Affordance, and Semantic/Reasoning dimensions.
4. A Smarter Way to Learn: The 4-Stage Training Pipeline
Developing a foundation model with such complexity requires a specialized “Progressive Domain Curriculum.” This pipeline relies on a spatial entropy-based scoring system, , calculated from depth variance and 3D object distribution to filter high-quality data.
The curriculum is structured into four stages using a tiered data taxonomy (T1-T4):
- Domain Semantic Alignment: Adapting the VLM to the language of driving (traffic rules, topology) using T1 (Scene Grounding) data.
- 3D Geometry Alignment: Activating the 3DA to learn spatial relations (occlusion, connectivity) using T2 (Spatial Localization) data.
- End-to-End Geometric Cognition: Mixing T3 (Multi-view/Temporal) and T4 (Spatio-temporal) data to couple spatial perception with language generation.
- EIEA Training (Physical Cue Integration): Fine-tuning via the LGRPO algorithm, using final answer rewards to optimize the model’s reasoning patterns when interacting with physical cue tokens.
5. Proven Performance: 18 Benchmarks and Counting
Validated across 18 public benchmarks, XEmbodied (SFT) has achieved SOTA performance in three core dimensions: 3D Understanding, Semantic Reasoning, and Affordance.
By internalizing geometric priors, the model specifically addresses the reasoning gap in long-tail scenarios such as waiting zones and channelization areas. This results in robust OOD generalization, ensuring that the model remains reliable even when encountering real-world street configurations it did not see during its 128-NVIDIA-H20-GPU training cycle.
6. Case Study: Precision Reasoning and Physical Cues
To demonstrate the precision of XEmbodied’s grounded reasoning, consider the “Can I Park Here?” test depicted in [SOURCE_IMAGE_12], [SOURCE_IMAGE_13], and [SOURCE_IMAGE_14].
Reasoning vs. Reality Box
- Instruction: “Can I park behind the white vehicle?”
- Physical Cues (Detected Entities with Coordinates):
- White vehicle:
[0.220, 0.358, 0.493, 0.691] - Pedestrian crossing:
[0.286, 0.717, 0.999, 0.870] - No entry sign:
[0.096, 0.227, 0.167, 0.343]
- White vehicle:
- XEmbodied Reasoning: The model identifies the precise spatial relationship between the white vehicle and the pedestrian crossing.
- Final Answer: “No. The white vehicle is parked in front of a pedestrian crossing, so I cannot park behind it.”
7. Conclusion: The Future of Scalable Autonomy
XEmbodied marks a transformative shift in how autonomous systems perceive the world. By moving beyond raw depth maps and toward internal geometric reasoning, it provides the industrial-scale infrastructure needed for the AD 3.0 era.
Key Takeaways
- Endogenous 3D Awareness: Moving beyond “flat-world” 2D processing to internalize 3D geometry via the VGGT-powered 3D Adapter.
- Efficient Tool Integration: Using a Mamba-based EIEA to convert messy sensor data into clean, distilled “physical tokens.”
- Reduced Hallucinations: Grounding decisions in specific spatial evidence (e.g., coordinate-level data) to ensure safer autonomous decisions.
This architectural shift ensures that the next generation of VLA models can navigate the complexities of the physical world with the same structured spatial sense as a human driver.
Read the full paper on arXiv · PDF