Fringe Projection Based Vision Pipeline for Autonomous Hard Drive Disassembly
Unrecovered e-waste represents a significant economic loss.
Fringe Projection Based Vision Pipeline for Autonomous Hard Drive Disassembly
1. Introduction: The Billion-Dollar E-Waste Blind Spot
In 2022, the global community generated a staggering 62 million metric tons of e-waste. Far from being just an environmental hazard, this represents a massive industrial oversight: an estimated USD 91 billion in material value remains unrecovered due to inadequate recycling infrastructure. Hard Disk Drives (HDDs) are a primary target for recovery because they are concentrated reservoirs of high-value materials, including Neodymium (a critical rare earth metal), gold, nickel, and palladium.
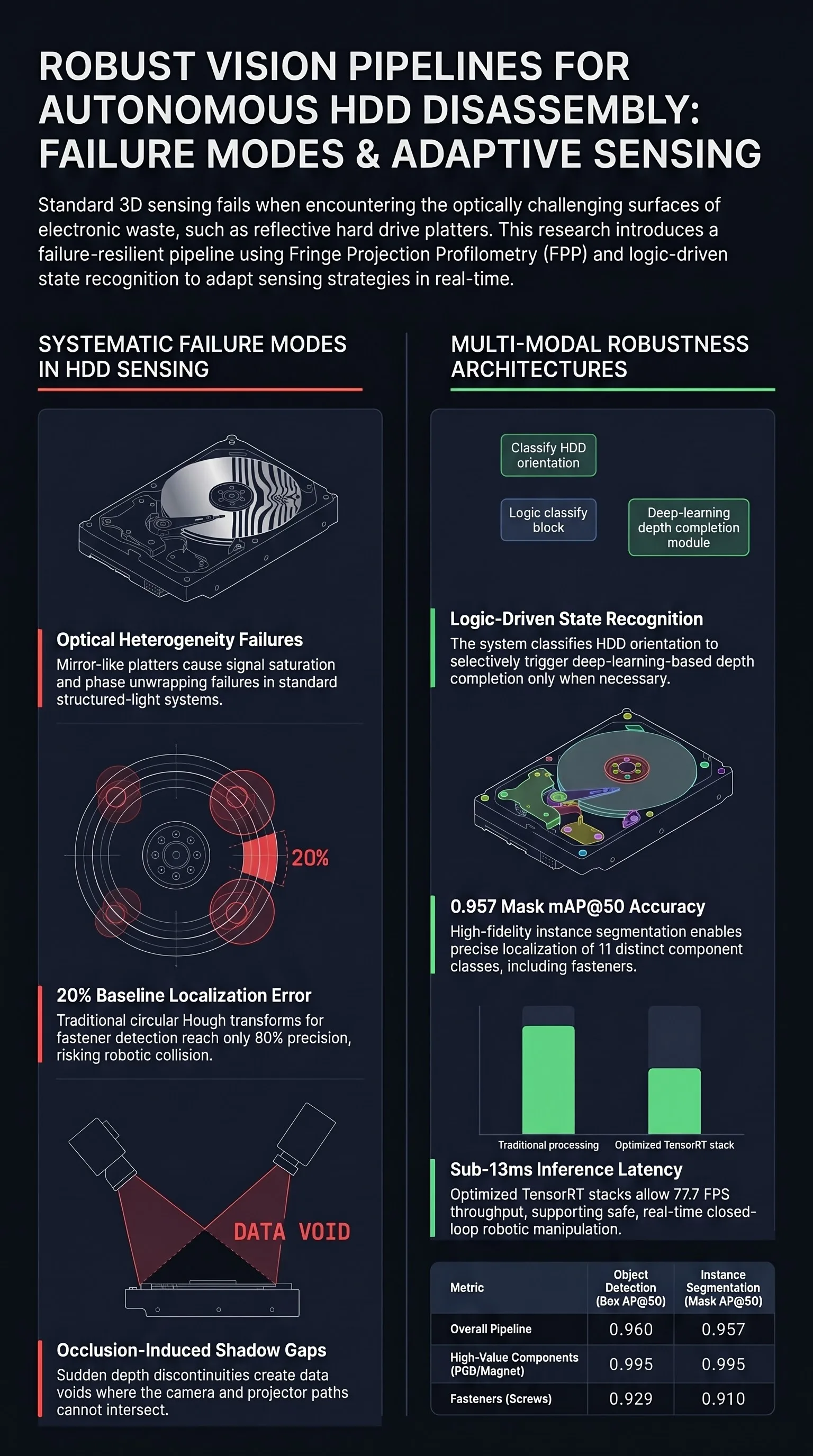
The bottleneck for large-scale recovery is the inherent difficulty of automation. Current attempts at automated processing are often fragmented, lacking the robust 3D sensing and specific fastener localization required for high-stakes disassembly. Our mission was to develop a vision pipeline capable of holistic scene understanding and dense reconstruction, navigating the extreme optical challenges posed by mirror-like surfaces and sub-millimeter fasteners.
2. The Hardware Paradox: Why Standard 3D Sensing Fails
HDDs are a “worst-case scenario” for computer vision due to their extreme optical heterogeneity. Within a single 3.5-inch assembly, a sensor must simultaneously resolve:
- Mirror-like central platters that generate severe specular reflections and phase-unwrapping failures.
- Reflective metallic components such as magnets and read-write heads that saturate traditional CMOS sensors.
- Matte, texture-rich PCBs and light-absorptive plastic casing elements.
Traditional 3D solutions are insufficient. Hyperspectral setups are cost-prohibitive and too slow for high-throughput industrial lines, while standard RGB-D sensors like the Intel RealSense D435i lack the depth precision for fine-scale fastener manipulation. Previous literature, such as the work by Yildiz et al., relied on circular Hough transforms for screw localization—a method that suffers from a 20% failure rate (80% precision) primarily due to unreliable candidate generation.
To solve this, we turned to Fringe Projection Profilometry (FPP). By employing an 18-step phase-shifting algorithm and graycoding for absolute phase unwrapping, we achieve sub-millimeter accuracy at kilohertz-rate acquisition speeds. Using 1-bit quasi-sinusoidal patterns with binary defocusing allows us to maintain high-fidelity spatial data even in a high-speed industrial cell.
3. Inside the Pipeline: A Logic-Driven Hybrid Architecture
Our architecture rejects the “one-size-fits-all” sensing model. Instead, we utilize a Logic-Driven State Recognition mechanism that adapts the sensing modality based on the object’s orientation.
The process begins with a lightweight YOLOv11n architecture for 2D semantic detection. This model is significantly more efficient than its predecessors, utilizing C3k2 blocks (replacing the older C2f blocks) for optimized feature extraction and C2PSA blocks (parallel spatial attention) to correlate distant visual features. If the “Platter” class is detected, the system enters the Platter Facing state, triggering the Multi-Modal Depth Completion Network (MMDC-Net). MMDC-Net doesn’t just fill gaps; it fuses sparse, reliable FPP data with relative depth priors from Depth Anything V2 and projector-illuminated grayscale images to predict dense geometry in reflective regions.
The Three-Step Workflow (Reference Figure 1):
- 2D Semantic Detection: YOLOv11n identifies 11 component classes (magnets, bearings, screws, etc.).
- State Recognition: The system classifies the orientation (Platter Facing vs. PCB Facing) based on the presence of a central platter.
- Adaptive 3D Profiling: The 3D protocol adapts: standard FPP for the matte PCB side, and FPP augmented by MMDC-Net for the mirror-like platter side.
4. Sim-to-Real: Solving the Data Scarcity Problem
Labeled datasets for end-of-life electronics are notoriously scarce. We bypassed this using a “Digital Twin” in Blender to generate 3,685 synthetic images. To ensure industrial-grade accuracy, we faced a major challenge: synthetic screw masks often merge into a single connected binary blob during rendering.
To solve this, we implemented SAM 3 (Segment Anything Model) as an offline instance-separation step. By prompting SAM 3 to identify discrete “white circles” within merged masks, we could automatically separate individual screw instances. These were then converted into the normalized polygon format required for YOLO training. Crucially, while we primed the model on thousands of synthetic images, we achieved success by fine-tuning on exactly 160 real-world projector-illuminated images. This demonstrates a viable path for deploying AI in niche industrial domains where “Big Data” is unavailable.
5. Performance Benchmarks: Speed Meets Precision
Evaluation on an NVIDIA RTX 5000 Ada workstation confirms the pipeline’s readiness for real-world deployment.
| Metric | Value |
|---|---|
| Instance Segmentation: Box mAP@50 | 0.960 |
| Instance Segmentation: Mask mAP@50 | 0.957 |
| Depth Completion: RMSE | 2.317 mm |
| Depth Completion: MAE | 1.836 mm |
| Combined Inference Latency | 12.86 ms |
| System Throughput | 77.7 FPS |
A standout feature is our Pixel-Wise Alignment. In traditional setups, a top-down camera and a physically offset stereo sensor (as seen in Yildiz et al.) require constant, complex registration. Our system uses a shared optical axis—the same camera captures both the 2D semantic masks and the 3D geometry. This inherent alignment eliminates the registration stage entirely, providing a significant advantage for robotic path planning and fastener association.
6. The Failure-First Perspective: Robustness and Limitations
Designing for the “real world” requires an honest assessment of systematic failure modes. Despite the accuracy of MMDC-Net, our FPP-based system faces two primary physical constraints:
- Occlusion-Induced Shadows: FPP requires an unoccluded path between the projector and the camera. Sudden depth discontinuities, such as tall casing walls or deep cavities within the HDD frame, block the fringe patterns, creating data voids.
- Data Voids: While our completion framework is optimized for the central platter, it does not currently algorithmically fill shadows or voids that occur on the outer casing or periphery components.
7. Conclusion: Key Takeaways for the Future of Recycling
This research establishes three critical pillars for the future of autonomous e-waste recovery:
- Hybrid Sensing is Essential: Purely geometric or semantic systems fail in the face of optical heterogeneity. A logic-driven pipeline that selectively triggers depth completion is the only way to handle the mirror-like surfaces of high-value e-waste.
- Sim-to-Real is Viable: Synthetic data, processed through instance-separation tools like SAM 3, allows for the precise detection of small fasteners (screws) that are the linchpin of disassembly.
- Efficiency is Deployment-Ready: Our Platter Facing learned inference stack achieves a latency of 12.86 ms on the RTX 5000 Ada. This sub-13ms performance makes the pipeline a prime candidate for integration into high-speed, real-time robotic disassembly cells.
By cracking the code of the HDD, we move the industry one step closer to a truly circular economy, where the billions of dollars currently lost to landfills are reclaimed through robust, autonomous AI systems.
Read the full paper on arXiv · PDF