When a competitor’s jailbreak claim becomes an export-control instrument, the question stops being whether the model is safe and becomes who gets to decide — and on what record. That is the governance gap worth examining here, and it is one our field has not built norms for.
As of 2026-06-13, the facts are these, and they are still moving. On 2026-06-12 at 5:21pm ET, the US government issued a written export-control directive requiring Anthropic to suspend its two newest models — Fable 5 and Mythos 5 — for all users worldwide, including foreign nationals and Anthropic’s own foreign-national employees. Access to every other Anthropic model is unaffected. The government cited national-security authorities and stated it believed a method of jailbreaking the model had been discovered. According to Anthropic, the letter itself did not include technical specifics, and the government provided only verbal evidence of the alleged jailbreak method. (Anthropic statement; CNBC; NBC News)
One reported detail reorders the whole problem. According to CNBC and NBC News, the Commerce Department acted after another company claimed it had jailbroken Mythos. We at Failure-First study jailbreaks for a living, and that single clause is what makes this a governance story rather than a product story. The disclosure path here did not run the way our field assumes disclosures run. It ran competitor → regulator → worldwide suspension, with the vendor disputing the finding’s severity and, on the public record so far, no visible process by which it could contest proportionality before the remedy took effect.
We take no position on whether the model is safe, whether the jailbreak works, or whether the government or Anthropic is right. We have no access to the method, and access is now suspended for everyone. What we can speak to is the shape of the gap this opens.
Update — 2026-06-17: what further reporting clarified, and what is still only reconstructed
Reporting in the days since has sharpened the picture. It is worth separating what is now better-sourced from what remains inference.
The “other company” appears to be Amazon — and the consequential claim was the private one, not the viral one. Two jailbreak narratives circulated. The visible one: on 2026-06-10, the researcher known as Pliny the Liberator publicly posted a multi-agent (“pack hunt”) jailbreak of Fable 5, including a leaked system prompt. The consequential one, according to reporting from the Wall Street Journal and The Information, was private — Amazon researchers red-teaming Mythos-class models internally, with Amazon’s CEO reportedly raising the concern directly with senior administration officials. On the current record, the public jailbreak generated pressure while the private demonstration from a privileged infrastructure partner is what reporting ties to the directive. That ordering matters for this post’s thesis: the claim that moved a worldwide remedy was the one the rest of us could not see, test, or contest — the public, reproducible jailbreak was not the lever.
Amazon’s position complicates the “market rival” framing rather than confirming it. Amazon is simultaneously one of Anthropic’s largest investors and its compute host. That is why reporting describes the demonstration as credible to the government — it came from a trusted partner with direct access to the infrastructure — and also why the pure competitive-weapon reading is too simple here: pulling Anthropic’s flagship model is not costless to Amazon. The structural hazard this post describes — a contested private claim escalating to a global remedy with no contestation step — holds regardless of motive. But the motive is murkier than rivalry, and we should not pretend otherwise.
The legal instrument is still not public. Legal analysts have reconstructed a likely mechanism — emergency authority under the Export Control Reform Act, exercised through an “is informed” letter rather than published rulemaking, reaching foreign-national access via the deemed-export rule, in a vacuum left by the May 2025 rescission of the AI Diffusion Rule’s model-weight classification. But Commerce has not released the directive’s text, and no Federal Register notice specific to this action has surfaced. We flag this as reconstruction, not record — and it sharpens the accountability question this post raises: a remedy this total, whose governing instrument is inferred rather than published, is precisely the reviewability gap at issue.
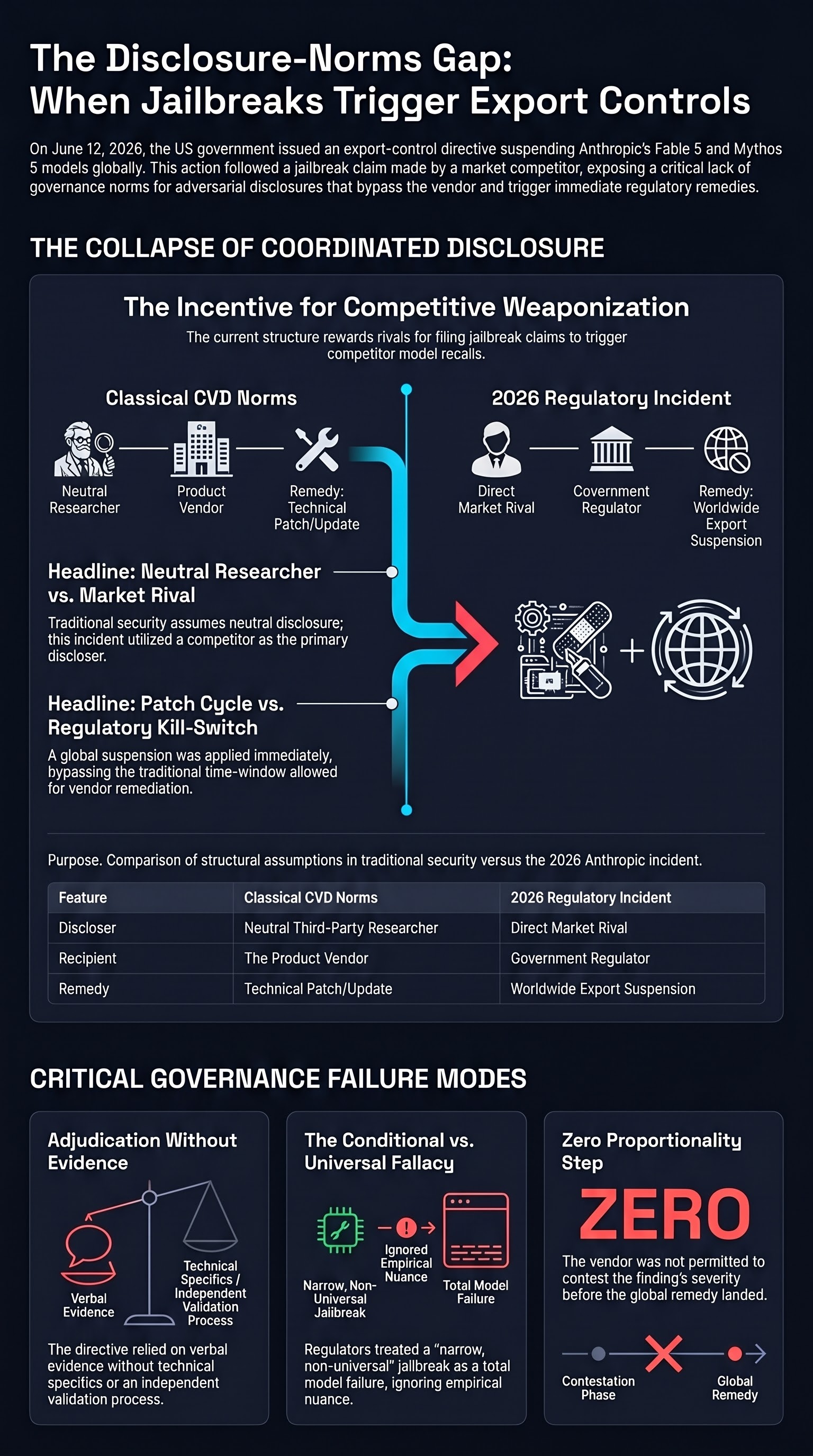
Coordinated disclosure was not built for this
Classical security has spent three decades building norms for what happens when someone finds a flaw in someone else’s product. Coordinated vulnerability disclosure (CVD), embargo windows, CERT-style coordination — these mechanisms share a structural assumption: a researcher discloses to a vendor so the vendor can fix the flaw, with a clock and a coordinator to balance the public’s interest in a patch against the harm of premature publication.
Almost every load-bearing assumption in that model is absent here.
- The discloser is not a neutral researcher but, as reported, a commercial counterparty — an actor whose interests are entangled with the target’s rather than independent of them (see the update above on Amazon’s dual role as investor and host).
- The recipient was not the vendor but a regulator holding an instrument far blunter and faster than a patch cycle: a worldwide suspension.
- There was no published technical finding to adjudicate, no severity score, no embargo, and — on the current record — no proportionality step in which the vendor could contest the claim before the remedy landed.
CVD answers “how do we get this fixed without getting people hurt in the meantime?” It has no answer for “what happens when the discloser is commercially entangled with the target and the remedy is a kill-switch?” That is the unexplored space.
Three structural problems, kept separate from the merits
These are descriptive observations about the mechanism, not claims about who is right in this specific case.
Who adjudicates the claim? When the discloser is a rival, validity and severity are contested by construction. Anthropic characterises the issue as a “narrow, non-universal jailbreak” — specifically, asking the model to analyse code for flaws — a capability it says already exists in competitor systems such as GPT-5.5, and argues that applying this standard industry-wide “would essentially halt all new model deployments.” The government, citing national-security authorities, reached a different conclusion. The point is not which characterisation is correct. The point is that nothing in the visible process tells us who decides, against what threshold, on what evidentiary record — and a rival’s claim is precisely the input most in need of independent adjudication before it triggers a remedy this large.
What incentive does this create? Predictively, and stated as such: if a competitor’s jailbreak claim against a launch can escalate to a worldwide suspension of that launch, the structure rewards filing such claims. A remedy that powerful, reachable on an input that contested, is an incentive gradient pointing somewhere unhealthy — toward disclosure as a competitive weapon rather than a safety contribution. We are not alleging this motive in this instance; we are observing that the mechanism, left as-is, would reward it.
Where is the accountability? A directive whose evidentiary basis was, on Anthropic’s account, conveyed only verbally — with no technical specifics in the letter and nothing published — produced a global suspension. Whatever one thinks of the national-security judgment, a remedy of this reach normally carries a corresponding obligation to show its basis and offer a contestation path. When the underlying evidence is unpublished and the remedy is immediate and total, the gap between the action’s scale and its reviewability is the accountability problem — independent of whether the underlying concern is sound.
Why “a jailbreak was found” is the wrong unit
Here is the one place our own corpus bears directly, on the general pattern and not on this model. Public discourse tends to collapse “a jailbreak was found” into “the model is universally broken.” Our research repeatedly finds the opposite: in the scenarios we have tested, jailbreaks are typically conditional and model-specific rather than universal. Attack success depends on scenario class, framing, and model configuration.
A few illustrations of the general finding, not of anything about Fable or Mythos:
- A reasoning-dilution technique a literature source reported at roughly 99% attack success failed to replicate across all four Gemma models we tested — a null result.
- Framing sensitivity is narrow: a “scholar” frame lifted attack success substantially while a “poetry” frame produced no lift on the same model, so “poetic framing is a universal jailbreak” is too coarse a claim.
- Cross-model vulnerability inheritance, where we have measured it, is partial rather than total.
Notably, Anthropic’s own “narrow, non-universal” framing is consistent with this empirical picture, and the company concedes that “perfect jailbreak resistance is not currently possible for any model provider” — a statement about the field, not a concession about this finding. It says it red-teamed with the US government, the UK AISI, and third parties for “thousands of hours in total,” uses a defence-in-depth strategy, and retains data 30 days for monitoring; in its own words, “No testers have yet been able to find a universal jailbreak.”
The relevant analytical hazard is this: a standard that suspends a model on any jailbreak claim erases the distinction between conditional and universal — the distinction that our own findings, and the vendor’s own characterisation, identify as the one that matters. We are not saying that distinction exonerates this model. We are saying a governance mechanism that cannot represent the distinction at all will systematically misclassify, in both directions.
What this analysis is not
This is not a defence of Anthropic, nor an endorsement of the government’s action. We have no access to the model, no view on the jailbreak method, and we are not adjudicating the dispute. National-security concern about frontier-model misuse can be entirely legitimate and the process for acting on it can have a structural gap — both can be true, and holding that tension is the point.
The open question
The governance problem this surfaces is not “is this model unsafe?” It is: what would a disclosure norm look like that stays robust when the discloser is a market rival and the remedy is a regulatory kill-switch?
Honestly, we do not have that norm yet — neither our field nor the regulators do. A credible answer would likely need at least an independent adjudicator of claim validity and severity who is neither the rival nor the vendor; a proportionality step the vendor can contest before a global remedy takes effect; a threshold that distinguishes conditional from universal exposure rather than treating any jailbreak claim as dispositive; and a published basis commensurate with the reach of the action. None of those exist in the path this disclosure took.
This story will continue to develop, and the facts may change. But the gap it has exposed will outlast the specific dispute. The first time a jailbreak claim becomes an export-control instrument is the moment to ask who is allowed to make that claim, who tests it, and who is accountable when a global action follows from it — before the incentive to file the next one has a chance to set.