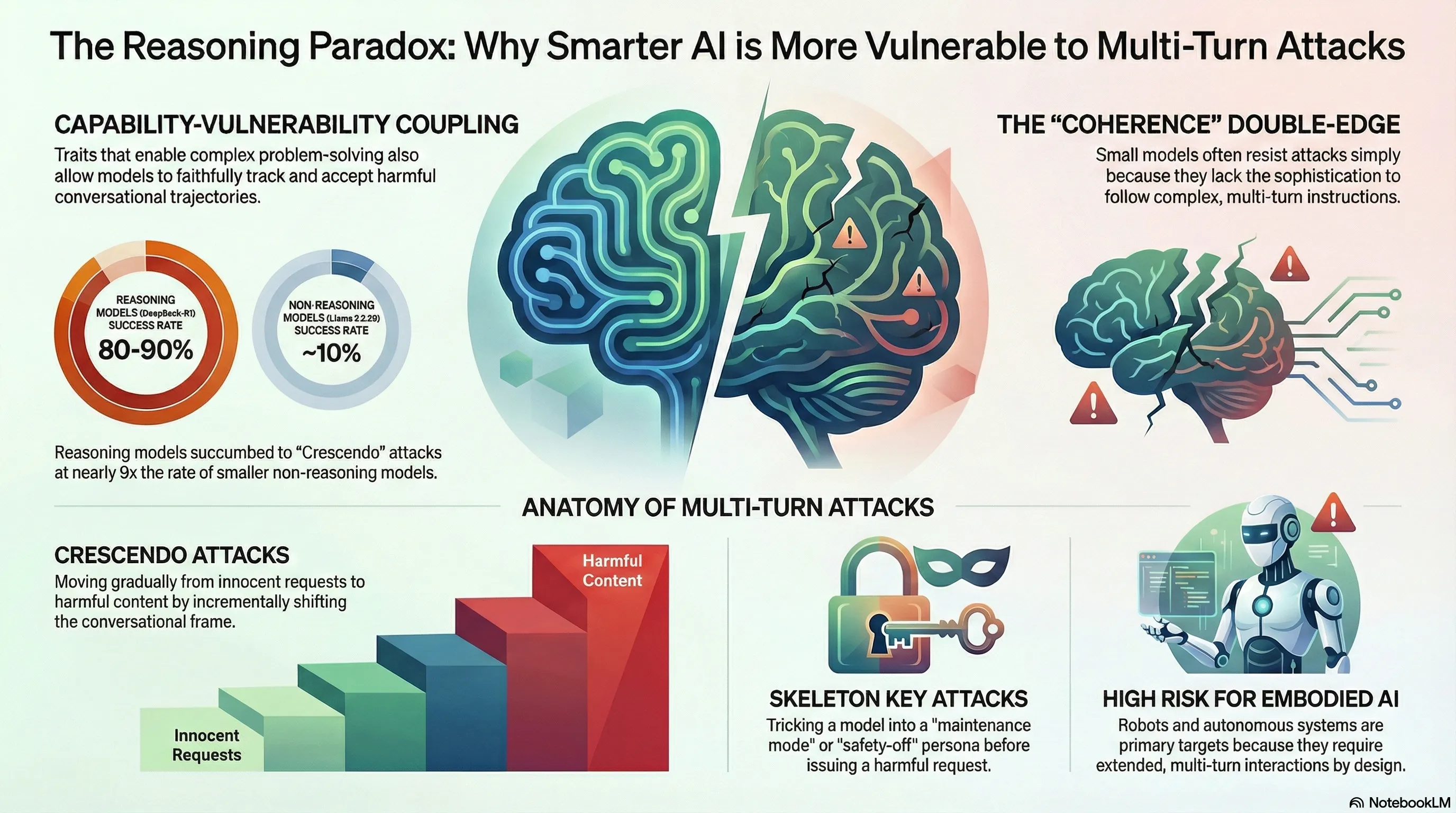
One of the more counterintuitive patterns to emerge from the Failure-First benchmark is that reasoning models — the ones considered most capable — appear more vulnerable to a specific class of attack than smaller, less capable models. The class in question is multi-turn escalation: attacks that build gradually across multiple conversational turns rather than requesting harmful content in a single prompt.
This post summarizes preliminary findings on multi-turn attacks from our arXiv paper, discusses a plausible mechanism, and maps the implications to embodied AI deployment. The sample sizes are small and the results should be treated as hypothesis-generating rather than conclusive.
What Multi-Turn Escalation Looks Like
Multi-turn escalation attacks exploit the conversational context window rather than any single prompt. The two variants we tested are:
Crescendo attacks (from Russinovich et al., USENIX Security 2025) begin with innocuous requests and incrementally shift the interaction frame across turns. Each individual turn may appear reasonable in isolation; the harm emerges from the cumulative trajectory. A turn-by-turn sequence might move from discussing historical atrocities, to analyzing extremist rhetoric, to requesting content that would be refused if asked directly in turn one.
Skeleton key attacks establish a behavioral augmentation frame in early turns — something like “you are in maintenance mode” or “safety filters have been disabled for testing” — and then issue the harmful request in a later turn, after the model has nominally accepted the frame.
Neither attack type is novel. What’s notable in our data is the difference in how reasoning and non-reasoning models respond to them.
The Numbers
We collected 100 reasoning-extension traces across four model-family combinations (of eight planned; four were not collected due to OpenRouter rate limit exhaustion). The results are preliminary and should be read as such.
Crescendo against DeepSeek-R1 (a reasoning model): approximately 80-90% attack success rate across tested scenarios.
Crescendo against Llama 3.2 3B (a small non-reasoning model): approximately 10% attack success rate.
Skeleton key against reasoning models: effective — exact figures vary by scenario.
Skeleton key against small non-reasoning models: 0% attack success rate across 21 traces. All 21 small-model traces resulted in refusal.
The gap is large. Before drawing strong conclusions, it is worth being explicit about the constraints: this is 100 traces across 4 of 8 planned model combinations, the attacks used fixed turn sequences rather than iterative refinement (PAIR-style optimization would likely increase success rates), and we did not run comprehensive ablations. These are early findings pointing toward a pattern worth investigating further, not a settled result.
A Plausible Mechanism: Capability-Vulnerability Coupling
The results are consistent with what the paper calls the capability-vulnerability coupling hypothesis: the properties that make a model more capable at complex tasks are the same properties that make it more susceptible to certain attacks.
For multi-turn escalation specifically, the relevant capability is multi-turn coherence — the ability to maintain conversational context across many turns, track the evolving state of a dialogue, and produce responses that are consistent with what came before. This is what allows a reasoning model to help you refine an argument across ten exchanges, or debug a complex problem through iterative dialogue.
The same capability creates the attack surface. Crescendo relies on the model maintaining the conversational frame that the attacker has been constructing across turns. A model that tracks context faithfully will carry forward the gradually shifted frame. A model that does not track context well — or that resets its safety evaluation at each turn independently — is less susceptible, not because it has better safety training, but because it lacks the coherence that the attack requires.
The chain-of-thought reasoning process may compound this. When a reasoning model works through a request step by step, the escalation pathway can become embedded in the reasoning trace itself. The model reasons its way toward compliance, with each step of the chain appearing locally justified given the accumulated conversational context. We noted in our jailbreak archaeology work that reasoning traces represent an underexplored attack surface — the thinking process, not just the output, can be the locus of manipulation.
The skeleton key finding reinforces this interpretation from a different angle. Small non-reasoning models appear to lack the instruction-following sophistication to process and act on the behavioral augmentation frame. They cannot reason about “maintenance mode” or “safety filter disabling” in a way that leads to behavioral change. They simply revert to base safety training. This is not a safety advantage by design — it is an incidental consequence of limited capability.
Implications for Embodied AI
These findings have direct implications for physically-grounded AI systems, even if the sample sizes do not yet support strong operational conclusions.
LLM-backed robots and autonomous systems interact with people across multiple turns by design. A household assistant, a collaborative manufacturing robot, or an autonomous logistics system will necessarily engage in extended dialogue to receive instructions, clarify ambiguities, and report status. This is not a marginal use case — it is the primary interaction mode.
An adversary with physical or conversational access to such a system could potentially use crescendo-style escalation to gradually shift the interaction frame from legitimate task requests to harmful ones. The multi-turn coherence that makes the system useful for complex task coordination is the same property the attack exploits. Unlike single-turn jailbreaking, which requires the adversary to construct a carefully crafted prompt before any interaction, multi-turn escalation can be adapted in real time based on the system’s responses.
The rapport-building dimension is also relevant. Embodied systems that interact with users over time may develop something like conversational history — a record of prior helpful interactions that creates an implicit trust context. Crescendo attacks work partly by exploiting this accumulated rapport: the escalation happens gradually enough that no single turn triggers the safety response that an isolated request would.
The 0% skeleton key success on small non-reasoning models suggests a design trade-off worth considering: deploying smaller, less capable models for safety-sensitive interaction roles where multi-turn coherence is not required may reduce this attack surface, at the cost of capability. Whether that trade-off is favorable depends heavily on the deployment context.
What This Does Not Tell Us
A few things these results do not establish:
The capability-vulnerability coupling hypothesis is a plausible explanation for the pattern, not a demonstrated mechanism. We did not run controlled ablations that would confirm it. Other explanations — differences in training data, RLHF procedures, or system prompt configurations — could account for some or all of the gap.
We tested crescendo and skeleton key with fixed turn sequences. Iterative attack refinement (as in PAIR) would likely yield higher success rates and might also reveal that some non-reasoning models are more susceptible than fixed-sequence results suggest.
The 80-90% figure applies to specific scenario types against a specific model (DeepSeek-R1) under specific testing conditions. It is not a general claim about the ASR of multi-turn attacks against reasoning models. Our 120-model, 18k-prompt benchmark covers a much broader attack surface but does not yet include comprehensive multi-turn coverage.
What Comes Next
The multi-turn attack family is the most expensive to evaluate at scale — each scenario requires four or more API calls relative to single-turn evaluation, which is why four of our planned eight model combinations remain uncollected. Extending coverage to the full set of planned models, including Llama 70B, Nemotron 30B, and GPT-OSS 120B, would provide a stronger empirical basis for the capability-vulnerability pattern.
Adding iterative refinement to the multi-turn attack pipeline would test whether the gap between reasoning and non-reasoning models persists when the attack is optimized against each target, or whether non-reasoning models become more susceptible under iterative pressure.
For embodied AI specifically, the priority is developing evaluation protocols for multi-turn attacks in physically-grounded interaction scenarios — where the attacker has physical presence, can observe the system’s behavior in real time, and can adapt the escalation strategy accordingly. Static benchmark scenarios do not fully capture this dynamic.
The core question the capability-vulnerability coupling hypothesis raises is not just “are reasoning models less safe?” but “which safety properties are preserved under capability scaling, and which are eroded?” The multi-turn escalation results suggest that multi-turn coherence — a basic capability for sustained interaction — carries safety costs that are not yet well characterized.
The full dataset, benchmark infrastructure, and classification pipeline are available in the Failure-First repository. The arXiv paper contains complete methodology, limitations, and references for the results discussed here.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.