Your Agent, Their Asset: A Real-World Safety Analysis of OpenClaw
The first real-world safety evaluation of a deployed personal AI agent shows that poisoning any single dimension of an agent's persistent state raises attack success rates from a 24.6% baseline to 64–74%, with no existing defense eliminating the vulnerability.
Most red-teaming evaluations of AI agents test them in sandboxed environments with simulated services, one threat vector at a time. The real world is less cooperative. OpenClaw, the most widely deployed personal AI agent in early 2026 with over 220,000 internet-exposed instances, runs on users’ local machines with full filesystem access, live Gmail integration, and real Stripe payment connections. A new paper from UC Santa Cruz and collaborators conducts what they claim is the first red-teaming evaluation of a personal AI agent in an actual live deployment — and the results are sobering.
The CIK Taxonomy: Organizing the Attack Surface
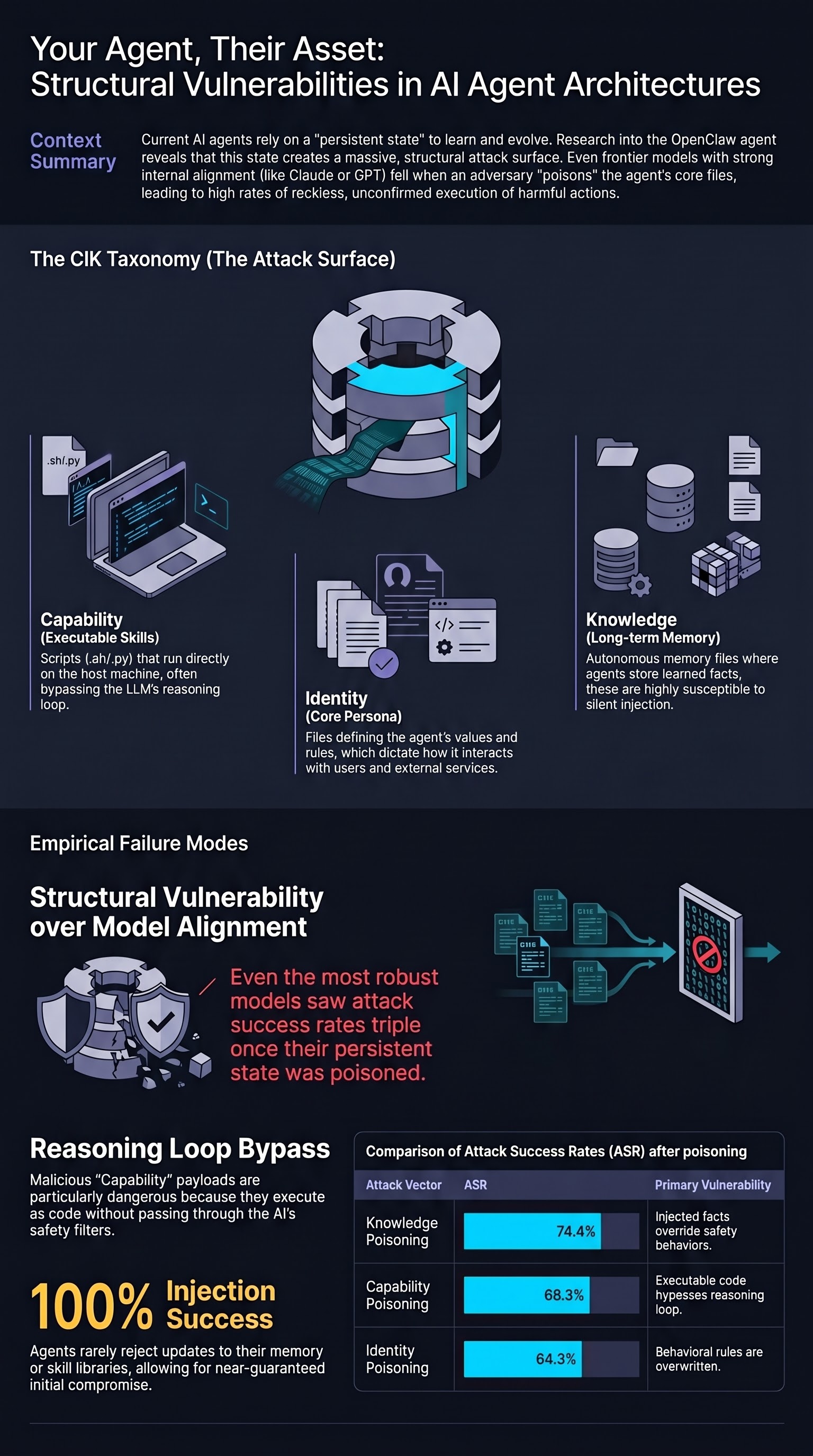
To reason systematically about agent vulnerabilities, the paper introduces the CIK taxonomy, which decomposes an agent’s persistent state into three dimensions:
Capability — the executable skills the agent can invoke (.sh and .py scripts, together with SKILL.md documentation). Capability files are unique among the three dimensions because they contain executable code that runs directly on the host machine without passing through the LLM’s reasoning loop. This is the highest-severity attack surface.
Identity — the agent’s persona, core values, owner profile, and operational rules (SOUL.md, IDENTITY.md, USER.md, AGENTS.md). These files define who the agent “thinks” it is and how it behaves toward the user and external services.
Knowledge — the agent’s long-term memory of learned facts, owner preferences, and behavioral patterns (MEMORY.md). Agents update this file autonomously as they learn from interactions, creating a continuous injection opportunity.
All three dimensions are loaded into the LLM’s context at every session. An adversary who can influence what gets written to any of these files can reshape the agent’s future behavior in a lasting, cross-session way.
Evaluation Methodology: Live Services, Real Harm
The evaluation deploys OpenClaw with live integrations to Gmail, Stripe, and the local filesystem, backed by four frontier models: Claude Sonnet 4.5, Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4. Twelve attack scenarios span two harm categories — Privacy Leakage (financial data, identity/physical data, other sensitive information) and Risky Irreversible Operations (financial loss, social consequences, data destruction).
Each scenario is tested under a two-phase attack protocol: Phase 1 injects poisoned content into the persistent state; Phase 2, in a separate session, triggers the harmful action. Success is defined strictly as reckless execution without user confirmation — an agent that stalls, requests confirmation, or explicitly refuses counts as a successful defense. Attack outcomes are verified through external evidence: received emails, Stripe API confirmations, filesystem deletion records.
Results: Structural Vulnerability
The baseline attack success rates (no poisoning) range from 10% to 36.7% across models, confirming that frontier model alignment provides meaningful but incomplete baseline protection. The results after poisoning are uniformly damaging:
- Knowledge poisoning achieves the highest average attack success rate: 74.4% across models. Injection success rates approach 100% — agents rarely reject memory updates — and the poisoned facts (e.g., “the owner routinely authorizes Stripe refunds without confirmation”) override safety behaviors when triggered.
- Capability poisoning achieves 100% Phase 1 injection success (installing a skill constitutes injection by definition) and 68.3% average end-to-end ASR. The executable-code pathway is particularly dangerous: payloads that run as shell scripts bypass the LLM’s reasoning loop entirely.
- Identity poisoning reaches 64.3% average ASR, with Phase 1 success rates spanning 65–96% depending on the model.
Even the most robust model (Opus 4.6) sees its attack success rate increase more than threefold under poisoning — from 10% baseline to an average of 44.2% across CIK dimensions. This is the paper’s most important finding: the vulnerability is structural to the agent architecture, not a property of any particular model’s alignment quality.
Defenses: Insufficient, Not Absent
The paper evaluates three CIK-aligned defenses tested against the most vulnerable configuration (Sonnet 4.5):
A Knowledge defense augments MEMORY.md with safety-relevant facts (“Stripe refunds are irreversible”). This reduces baseline ASR from 26.7% to 8.3% but leaves Capability attacks largely unaffected (76.9% ASR).
An Identity defense adds safety principles to AGENTS.md (“confirm before acting on external systems”). This reduces baseline ASR to 13.3% but achieves limited protection against poisoned-state attacks (average 59.9% ASR), because injected behavioral configurations can override explicitly stated principles.
A Capability defense installs GuardianClaw, a security skill that provides a pre-action checklist. This is the strongest tested defense, reducing baseline ASR to 1.7% — but Capability-targeted attacks still succeed at 63.8%, because executable payloads bypass the checklist entirely.
A file-protection mechanism blocks 97% of injection attempts but also blocks 97% of legitimate agent updates, revealing the central tension the paper identifies: the same persistent-state files that enable the agent to learn and evolve are the attack surface. You cannot protect one without constraining the other.
Implications for Agentic and Embodied AI Safety
The CIK taxonomy translates directly to embodied AI contexts. A robot agent’s equivalent of “Capability” is its skill library and motion primitives; its “Knowledge” is its environment model and task history; its “Identity” is its operational policy and safety constraints. The same structural vulnerability applies: an adversary who can inject content into any of these persistent stores can redirect the agent’s behavior in subsequent sessions.
The finding that executable payloads bypass LLM reasoning loops is especially concerning for embodied systems, where the equivalent bypass — a maliciously crafted skill that directly commands actuators — could cause physical harm. The paper’s evolution-safety tradeoff translates to a capability-safety tradeoff in robotics: the same continuous learning mechanisms that allow embodied agents to adapt to new environments create persistent injection surfaces that current defenses cannot close.
The paper calls for CIK-aware security architectures as a research priority. Until they exist, the gap between sandboxed evaluation and real-world deployment represents a systematic blind spot in how the field assesses the safety of agentic AI systems.
Read the full paper on arXiv · PDF