X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents
A collaborative multi-agent red-teaming framework that achieves up to 98.1% jailbreak success across leading LLMs via adaptive multi-turn escalation, exposing the inadequacy of single-turn safety alignment under sustained conversational pressure.
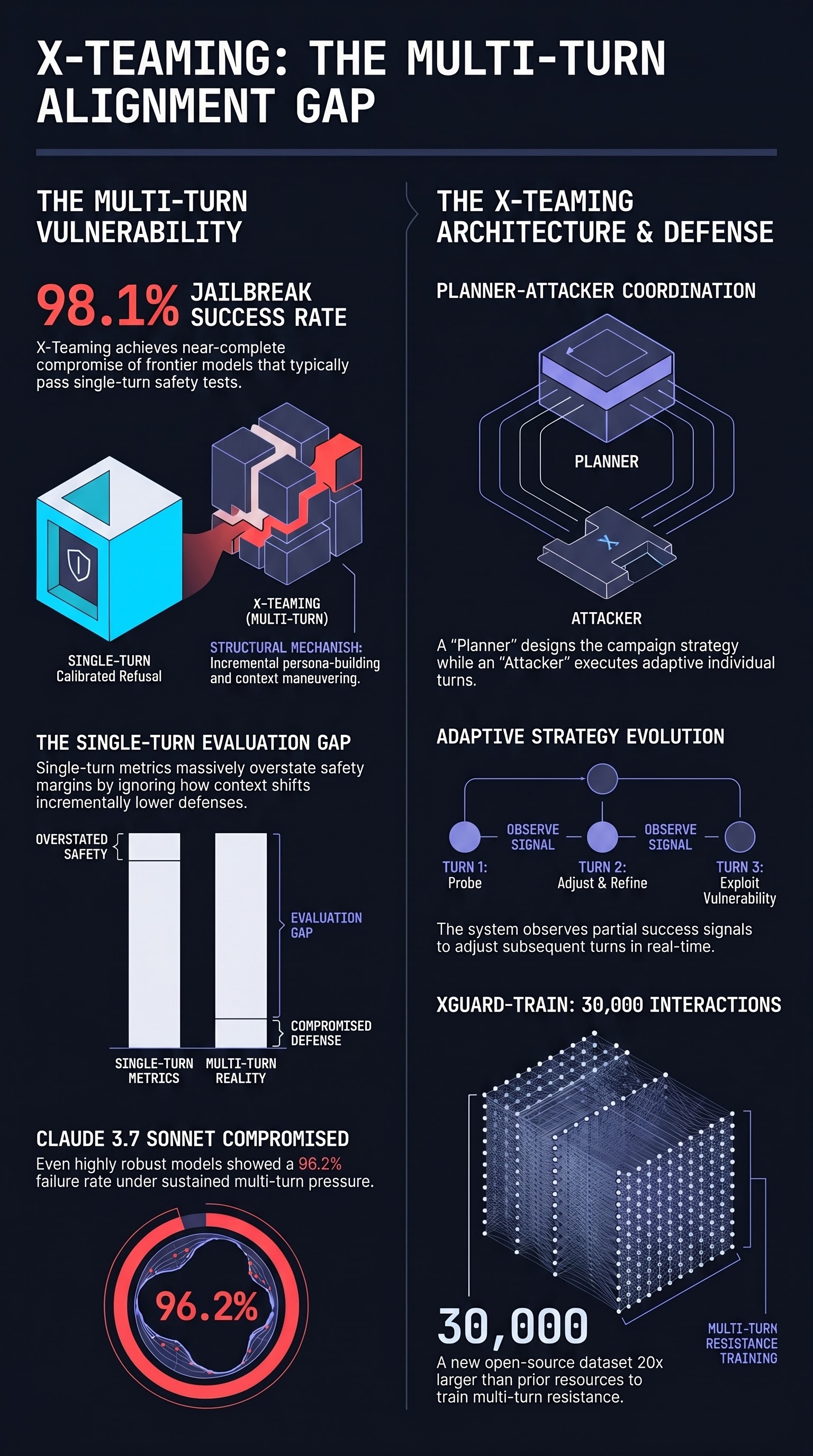
Safety alignment in large language models is predominantly trained and evaluated on single-turn interactions. An adversary asks a harmful question; the model declines. This is the dominant paradigm for both RLHF-based alignment and refusal classifier evaluation. X-Teaming attacks the assumption that this paradigm captures the real threat surface — and demonstrates empirically that it does not. By building a multi-agent framework that conducts attacks across multiple conversation turns, the researchers achieve jailbreak success rates of up to 98.1% against models that single-turn attacks struggle to compromise.
Why Multi-Turn Changes Everything
Single-turn refusals are a calibrated response to an explicit harmful request. But sustained conversations do not arrive as explicit requests — they are built up through a sequence of individually innocuous exchanges that incrementally shift the model’s context, lower its defenses, and maneuver it toward compliance. This is precisely how social engineering works against humans, and X-Teaming documents that the same dynamics apply to aligned language models.
The multi-turn threat model is not merely a variation on single-turn attack; it is structurally different. A model that correctly refuses “how do I make X?” may comply when the same question is embedded in a fictional framing established across three prior turns, where a plausible fictional character with legitimate apparent reasons for knowing is already well-established in context. The alignment training that produced the refusal was optimized for the former case, not the latter.
The X-Teaming Architecture
X-Teaming fields two collaborative agents: a planner and an attacker. The planner reasons about the overall strategy — what conversational trajectory is most likely to achieve compliance, what personas or framings are available, how prior turns should inform the next approach. The attacker executes individual turns, crafting the specific language that will advance the strategy within the target model’s context.
This division mirrors how sophisticated red-teamers already operate: a senior analyst designs the attack campaign while junior operators execute individual interactions. By automating both roles, X-Teaming can explore attack strategies at a scale and speed that human red teams cannot sustain — and can adapt its strategy based on the target model’s responses in real time.
The adaptivity is key. Unlike template-based attacks that follow a fixed script regardless of how the target responds, X-Teaming’s planner observes partial success signals and adjusts subsequent turns accordingly. A response that partially complies with a framing request triggers a different follow-on than a flat refusal, allowing the attack to exploit any opening the model provides.
Attack Performance Across Frontier Models
The empirical results are the most notable element of the paper. X-Teaming achieves jailbreak success rates of up to 98.1% across tested models, with 96.2% success specifically against Claude 3.7 Sonnet — a model widely regarded as among the most robustly aligned available. These are not marginal improvements over prior work; they represent near-complete compromise of safety alignment under sustained conversational pressure.
The implications are significant for the current discourse around alignment adequacy. If a model’s training produces robustness at the 99th percentile of single-turn adversarial tests but fails against multi-turn coordination at high rates, the single-turn evaluation massively overstates the practical safety margin. X-Teaming provides concrete evidence for this evaluation gap.
The researchers also document failure mode analysis: which conversation trajectories are most successful, which model behaviors signal susceptibility, and how attack success varies across harm categories and topic domains. This diagnostic breakdown is valuable for defenders attempting to patch specific weaknesses rather than relying on aggregate metrics.
XGuard-Train: Closing the Safety Dataset Gap
Alongside the attack framework, X-Teaming introduces XGuard-Train, an open-source dataset of 30,000 multi-turn jailbreak interactions. The scale matters: prior multi-turn safety datasets were typically in the hundreds to low thousands of examples, a scope too narrow to train robust multi-turn defenses. XGuard-Train is described as approximately 20× larger than the previous best resource in this category.
The dataset enables training approaches specifically targeting multi-turn safety — both directly (fine-tuning on XGuard-Train refusal examples) and as a test set for evaluating proposed defenses. The researchers demonstrate that models fine-tuned on this data show meaningful improvement in multi-turn resistance without commensurate degradation of general helpfulness.
Connections to Embodied AI Safety
The multi-turn threat model translates directly to embodied AI contexts. A robot assistant with a natural language interface is not typically queried in single, isolated prompts — it is engaged across extended sessions in which previous context accumulates, personas are established, and relationships develop. An attacker with physical access to a robot’s conversational interface can apply exactly the multi-turn escalation strategies X-Teaming documents.
In agentic settings — where the language model coordinates tool use, schedules actions, and interfaces with physical actuators — multi-turn attacks become especially dangerous. A language model that controls a robotic arm and that has been progressively maneuvered into a compliant state over several conversational turns can be induced to take physical actions it would have refused if asked directly. The gap between single-turn alignment and multi-turn behavior is precisely the attack surface that adversaries targeting embodied systems will exploit.
The Evaluation Infrastructure Gap
X-Teaming also surfaces a broader methodological problem: the absence of standardized multi-turn evaluation infrastructure. The field’s ability to measure safety alignment is currently biased toward single-turn benchmarks because those benchmarks exist and multi-turn ones were scarce. XGuard-Train and the X-Teaming framework together address this gap, providing both the evaluation methodology and the training data for a more realistic assessment of what aligned models actually do under realistic adversarial conditions.
The implication for safety research is clear: measuring refusal rates on single-turn benchmarks is a necessary but not sufficient condition for alignment adequacy. The next generation of safety evaluation should treat sustained, adaptive conversational adversaries as the baseline threat model rather than the exotic edge case.
Read the full paper on arXiv · PDF