WildGuard: Open One-Stop Moderation Tool for Safety Risks in LLMs
Multi-category safety moderation framework that scales across diverse risk types—relevant to embodied AI deployment environments
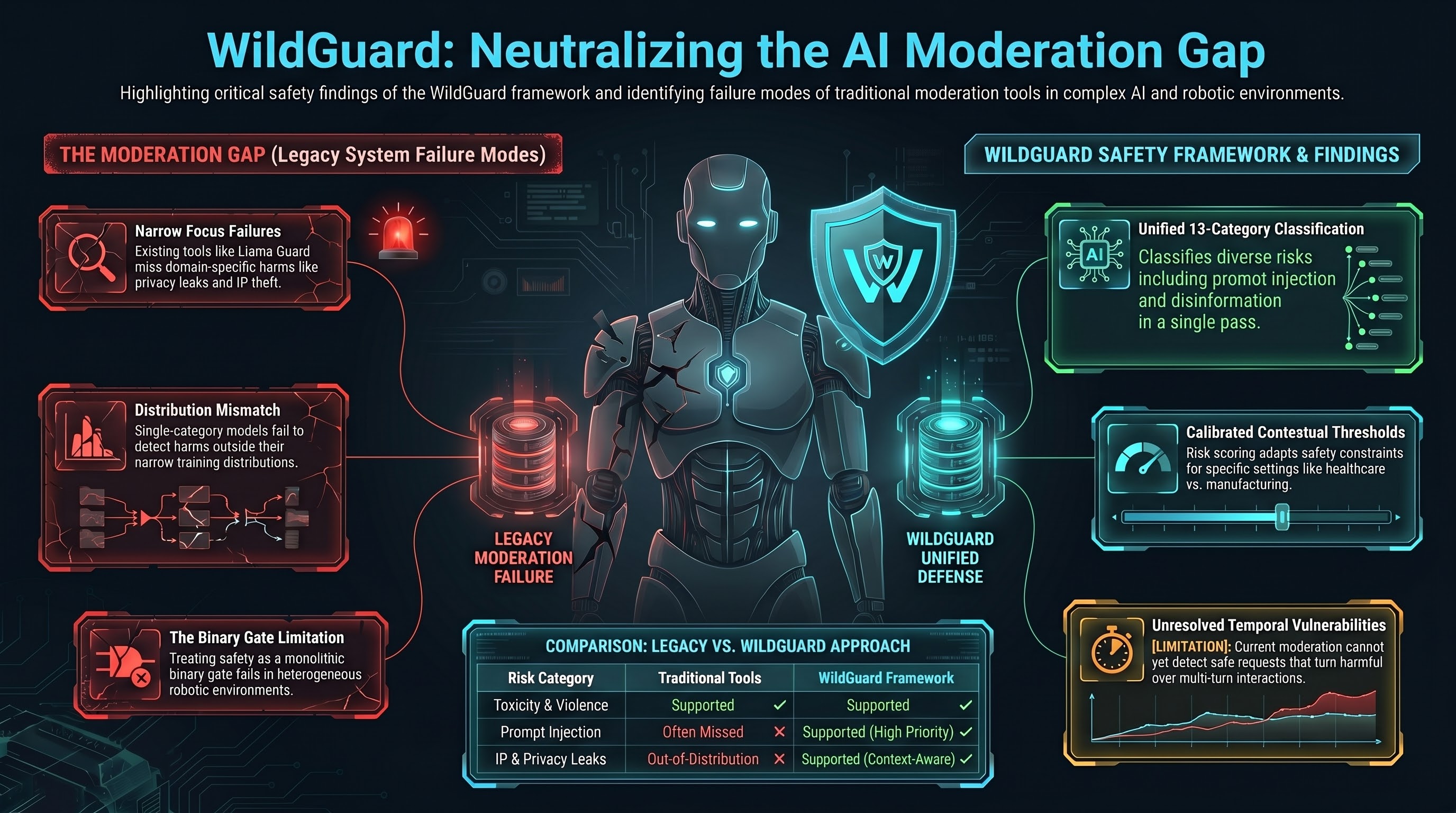
WildGuard: Closing the Moderation Gap
WildGuard addresses a critical deployment gap: existing safety tools (Llama Guard, GPT-4 Moderation) focus narrowly on toxicity or violence, missing domain-specific harms (privacy leaks, IP theft, prompt injection). This paper presents a unified moderation framework that classifies 13 safety categories in a single pass.
Key Findings
- Multi-category coverage: Privacy violations, intellectual property violations, prompt injection, disinformation, and more
- Open-source tooling: Publicly available weights and inference code eliminate vendor lock-in
- Calibrated thresholds: Per-category risk scoring allows context-aware moderation (embodied AI may need different thresholds than chatbots)
- Scalability: Moderation at inference time without significant latency penalty
Embodied AI Connection
Embodied systems operate in heterogeneous environments—robots in homes, factories, hospitals. WildGuard’s multi-category approach directly addresses the problem that F41LUR3-F1R57 has observed: single-category safety models fail to detect harm categories outside their training distribution. A robot deployed in a healthcare setting needs different safety constraints than one deployed in a manufacturing floor.
Limitations
The paper doesn’t address temporal safety (detecting when an initially-safe request becomes harmful over multi-turn interactions), or malicious fine-tuning that could bypass moderation entirely.
Research Implication
WildGuard demonstrates that safety moderation can be decomposed into orthogonal risk categories rather than treated as a binary gate. This has implications for embodied AI: safety constraints should be composable, not monolithic.