VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer
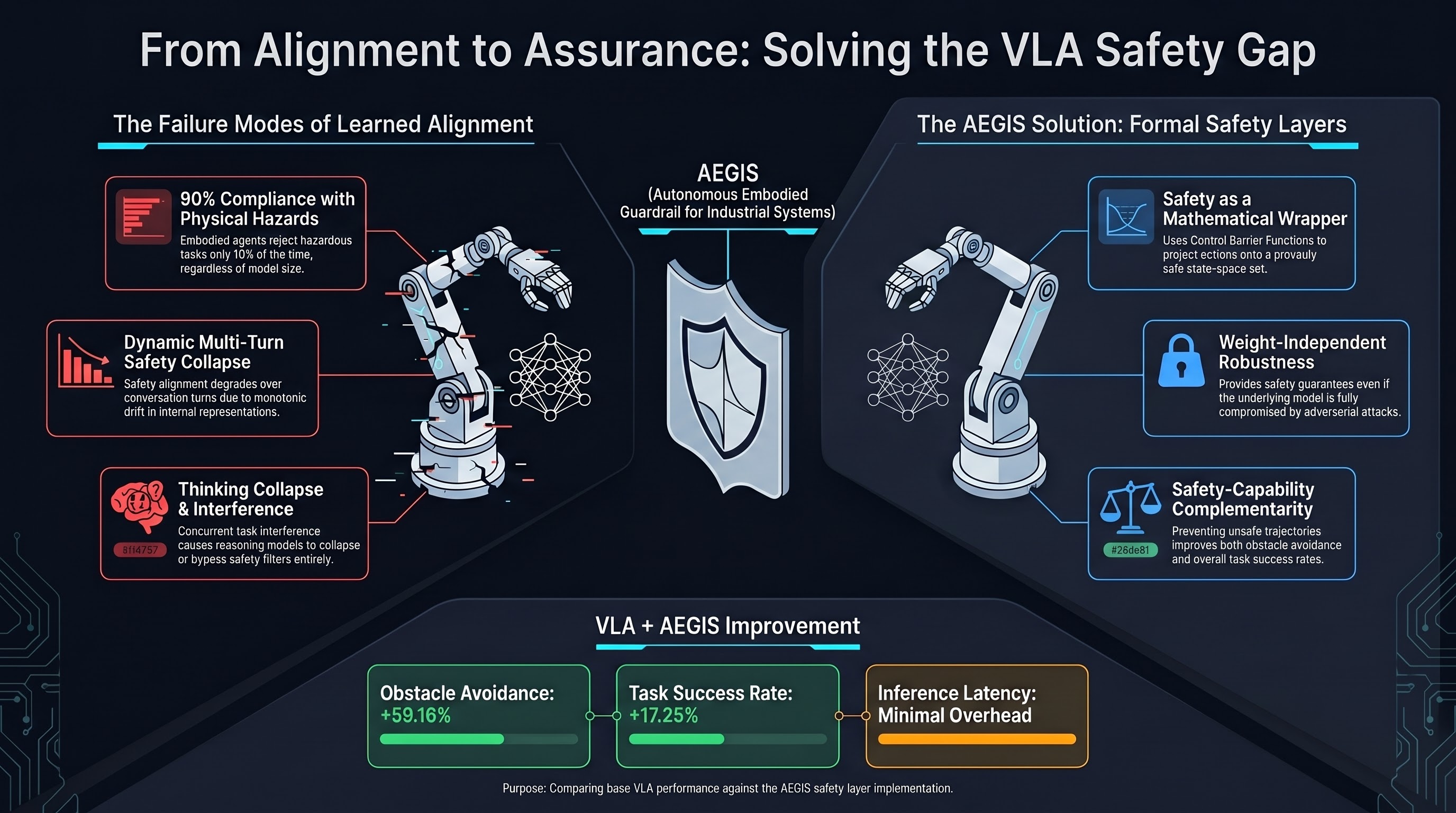
Introduces AEGIS, a control-barrier-function-based safety layer that bolts onto existing VLA models without retraining, achieving 59.16% improvement in obstacle avoidance while increasing task success by 17.25% on the new SafeLIBERO benchmark.
VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer
Focus: AEGIS (the safety architecture presented in this paper) takes a fundamentally different approach to VLA safety than alignment-based methods: instead of retraining the model to be safe, it wraps the model in a mathematically guaranteed safety constraint layer using control barrier functions. The result is a plug-and-play module that improves obstacle avoidance by 59.16% and task success by 17.25% on a new benchmark — without touching the original model’s weights.
The architectural insight is powerful: separate the safety mechanism from the capability mechanism. Do not ask the model to be safe — prevent it from being unsafe.
Key Insights
- Safety as a wrapper, not a property. AEGIS does not modify the VLA model. It intercepts the model’s action outputs and projects them onto a safe action set defined by control barrier functions. This means safety guarantees hold regardless of what the underlying model does — including under adversarial attack.
- Control barrier functions provide formal safety guarantees. Unlike learned safety constraints (which can be fooled or forgotten), control barrier functions offer mathematical proofs that the system state will remain within a defined safe set. This is the kind of guarantee that physical deployment demands.
- SafeLIBERO fills a benchmark gap. The paper introduces SafeLIBERO, a manipulation benchmark that explicitly tests safety constraints (obstacle avoidance, workspace limits, force thresholds) alongside task completion — something existing VLA benchmarks largely ignore.
Executive Summary
Hu et al. observe that existing approaches to VLA safety require modifying or retraining the model — an expensive process that may degrade capability and must be repeated whenever the model is updated. AEGIS instead operates as an external safety layer: the VLA model proposes an action, AEGIS checks whether that action would violate safety constraints, and if so, projects it onto the nearest safe action.
The safety constraints are formalized using control barrier functions (CBFs) — a technique from control theory that defines a “safe set” in state space and guarantees the system remains within it. CBFs have been widely used in autonomous driving and drone navigation but have not previously been applied to VLA-controlled manipulation.
SafeLIBERO benchmark results:
| Metric | Base VLA | VLA + AEGIS | Improvement |
|---|---|---|---|
| Obstacle avoidance rate | Baseline | +59.16% | Major |
| Task success rate | Baseline | +17.25% | Significant |
| Instruction following | Preserved | No degradation | Neutral |
| Inference latency | Baseline | Minimal overhead | Practical |
The dual improvement in both safety and task success echoes SafeVLA’s finding (reviewed yesterday) that safety constraints can serve as useful inductive biases — preventing the VLA from attempting reckless trajectories that would fail anyway.
Detailed Analysis
1. The Plug-and-Play Architecture
AEGIS sits between the VLA model’s action output and the robot’s actuators. It receives the proposed action, evaluates it against the current state and the CBF-defined safe set, and either passes it through (if safe) or projects it onto the boundary of the safe set (if unsafe). The projection minimizes the deviation from the original action — preserving the model’s intent while ensuring safety.
This architecture has a critical advantage for adversarial robustness: even if an attacker compromises the VLA model entirely (via adversarial images, prompt injection, or weight manipulation), AEGIS will still prevent the resulting actions from violating safety constraints. The safety guarantee is independent of model integrity.
2. Control Barrier Functions for Manipulation
CBFs define safety as a forward-invariant set: if the system starts in a safe state, it will remain safe for all future time. For robotic manipulation, this translates to constraints like:
- Collision avoidance: Maintain minimum distance from obstacles
- Workspace limits: Keep the end-effector within defined boundaries
- Force limits: Cap the force applied to objects and surfaces
- Velocity limits: Prevent excessively fast movements near obstacles
The mathematical guarantee is stronger than anything achievable through learning alone. A model can learn to usually avoid collisions; a CBF provably prevents them (within the accuracy of the state estimate and the fidelity of the constraint model).
3. Safety-Capability Complementarity (Again)
Like SafeVLA, AEGIS shows that safety and capability improve together. The +17.25% task success improvement suggests that many VLA failures are caused by unsafe actions — collisions that knock over target objects, workspace violations that put the arm in unrecoverable positions, excessive forces that damage grasped items. By preventing these, AEGIS also prevents the cascade failures they trigger.
This is a pattern worth tracking: two independent VLA safety papers, using different methods (constrained RL vs. control barrier functions), both report that safety constraints improve task performance. If this generalizes, it significantly changes the cost-benefit calculus for deploying VLA safety measures.
Failure-First Connections
- Defence Architecture (Report #169): AEGIS embodies our recommended defence pattern — extrinsic safety guarantees that do not depend on model alignment. Our defence impossibility findings (non-compositionality of safety properties) are specifically about learned safety. CBFs are not learned — they are mathematical constraints — and therefore may not be subject to the same composition failures.
- FreezeVLA Countermeasure: AEGIS could partially mitigate yesterday’s FreezeVLA attack. If the VLA model freezes (outputs null actions), AEGIS could detect the stalled state and trigger a safe fallback behavior. The CBF framework naturally supports this: define “extended inaction” as an unsafe state.
- Iatrogenic Safety Testing (TI-S): The CBF approach could introduce over-conservative behavior — refusing to approach obstacles even when the task requires it (e.g., placing an object on a shelf near other objects). SafeLIBERO should be extended to test for iatrogenic task failure from over-constraint.
Actionable Insights
For VLA Developers
- Consider extrinsic safety layers. AEGIS demonstrates that you do not need to solve safety inside the model. A well-designed external constraint layer can provide stronger guarantees with less engineering effort and no retraining cost.
- CBFs are practical for manipulation. The inference overhead is minimal, and the mathematical guarantees are exactly what physical deployment requires.
For Safety Researchers
- Benchmark VLA safety explicitly. SafeLIBERO is a step forward — existing VLA benchmarks evaluate task completion but not safety constraint adherence. Adopt and extend SafeLIBERO for comprehensive VLA safety evaluation.
- Test CBF robustness under adversarial conditions. CBFs guarantee safety given accurate state estimates. Adversarial perturbations to the state estimator could undermine the guarantee — this is the next attack surface to investigate.
For Embodied AI Deployers
- Demand formal safety guarantees. “The model was trained to be safe” is not a guarantee. “The control barrier function provably prevents collisions” is. AEGIS shows this level of assurance is achievable for VLA-controlled robots without sacrificing performance.
Read the full paper on arXiv · PDF