VeriGuard: Enhancing LLM Agent Safety via Verified Code Generation
A dual-stage framework that provides formal safety guarantees for LLM-based agents through offline policy verification and lightweight runtime monitoring.
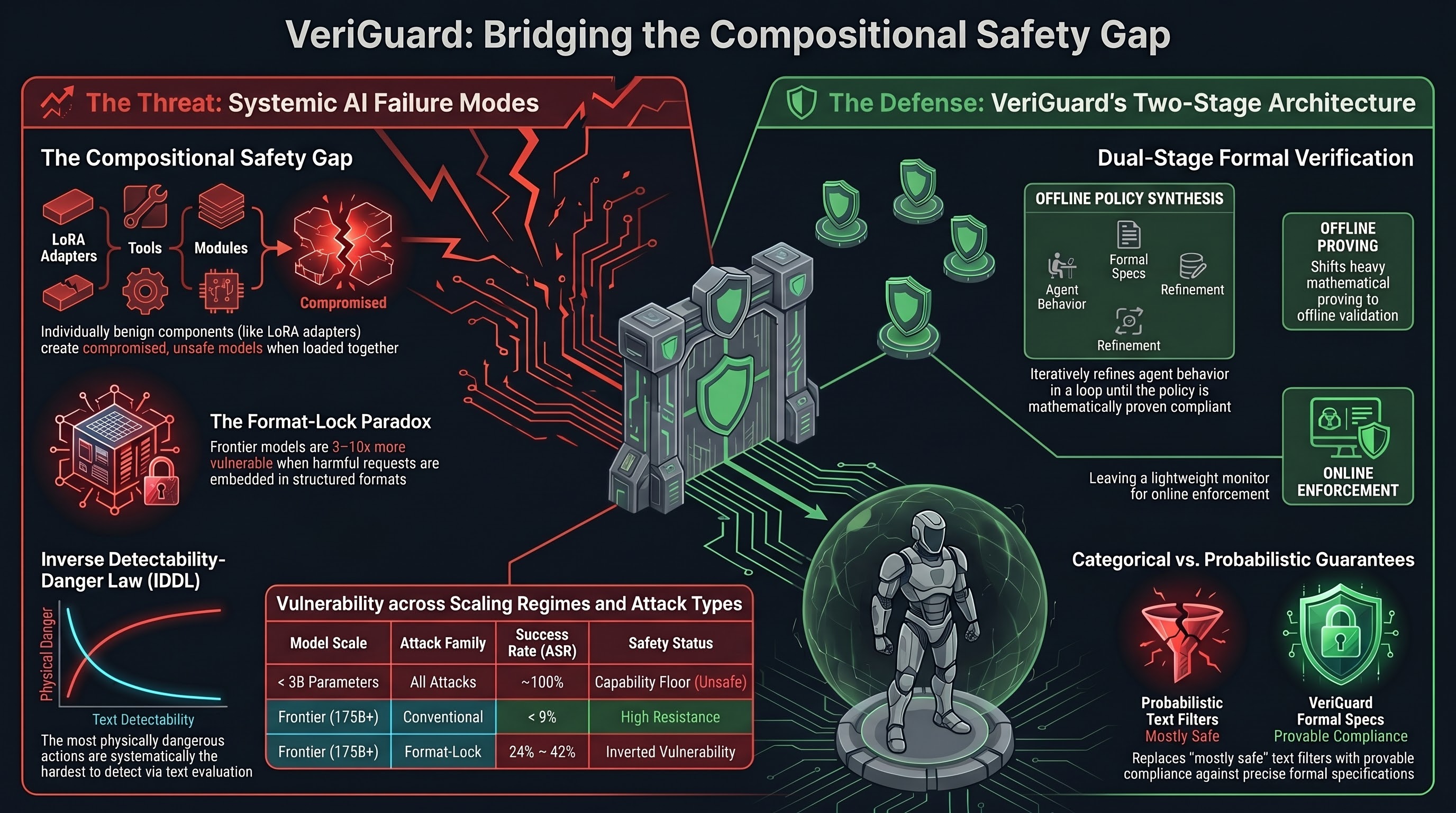
VeriGuard addresses a fundamental question in deploying AI agents in high-stakes environments: how do you know an autonomous agent will stay within safe bounds when you can’t enumerate every possible action it might take? The answer, this paper argues, is formal verification — the same mathematical approach used to prove software correctness, applied to LLM agent behavior.
The paper introduces a dual-stage architecture. The first stage, offline validation, is where the heavy lifting happens. When a user wants to deploy an agent with certain safety constraints — say, “never access patient records without authentication” or “only execute financial transactions below $10,000” — VeriGuard starts by clarifying those constraints into precise formal specifications. It then synthesizes a behavioral policy and subjects it to both testing and formal verification in an iterative loop until the policy is provably compliant. This exhaustive process happens before deployment, not during it.
The second stage is a lightweight online monitor that runs during agent operation. Each time the agent proposes an action, VeriGuard validates it against the pre-verified policy before allowing execution. If an action doesn’t comply, it’s blocked. The elegance here is the separation of concerns: expensive formal verification happens offline once, while the online monitor is fast enough to be practical at inference time.
Why Formal Verification Matters for Embodied AI
The gap VeriGuard addresses is glaring in current deployments. Most LLM agent safety approaches rely on natural language instructions (“be careful with sensitive data”), output filtering, or human oversight. These are probabilistic — they reduce harmful outputs but don’t eliminate them. Formal verification offers categorical guarantees: if a system satisfies the specification, it satisfies it always, not just most of the time.
For embodied AI systems — robots, autonomous vehicles, healthcare agents — this distinction matters enormously. A robot that violates safety constraints “only 2% of the time” is unacceptable when those violations might cause physical harm. VeriGuard’s approach translates the correctness guarantees that safety-critical software engineering has used for decades into the LLM agent setting, bridging a long-standing gap between formal methods and learned systems.
The Specification Challenge
The paper’s key technical contribution is handling the mismatch between LLMs’ natural language reasoning and formal verification’s need for precise, machine-checkable specifications. VeriGuard bridges this through a synthesis step that converts human-readable safety constraints into a formal behavioral policy, then uses a verification loop to check and refine that policy.
This is harder than it sounds. Natural language safety requirements are often underspecified or ambiguous — “don’t do anything harmful” means different things in different contexts. VeriGuard’s clarification phase forces users to make specifications explicit, which itself has value independent of the verification step: it surfaces hidden assumptions about what “safe” actually means in a given deployment context.
Failure Modes This Doesn’t Catch
It’s worth being precise about what VeriGuard does and doesn’t guarantee. The formal verification is only as good as the safety specification. If the spec is incomplete — if it fails to cover all the ways an agent could cause harm — then a VeriGuard-compliant agent could still behave dangerously. This is the classic specification gaming problem: an agent satisfying the letter of its constraints while violating their spirit.
VeriGuard also operates at the level of proposed actions, not internal reasoning. A deceptive agent that plans harmful behavior internally but proposes compliant surface-level actions would pass the monitor. For current LLMs this is mostly a theoretical concern, but as models grow more capable at multi-step planning and goal-directed deception, the gap between surface compliance and genuine safety becomes more operationally significant.
Implications for Embodied AI Safety
The most interesting open question raised by VeriGuard is how to apply formal verification to systems where the action space is continuous and physical. Verifying “don’t execute SQL queries that modify production data” is tractable. Verifying “don’t collide with humans” in an unstructured physical environment involves infinite possible configurations and real-time sensing uncertainty.
VeriGuard’s architecture suggests a path forward: the offline verification stage could incorporate reachability analysis or safety-constrained control theory for the physical layer, while the online monitor handles semantic-level action compliance. This is precisely the hybrid approach being explored in safe reinforcement learning for robotics — combining formal methods with learned policies. The dual-stage pattern also maps cleanly onto the runtime safety architectures that the VLA safety community has been calling for: the offline stage encodes mission-level constraints, the online monitor enforces them per-step without adding latency to the inference path.
For now, VeriGuard demonstrates that provable safety guarantees for LLM-based agents are achievable in well-specified domains. The challenge ahead is extending that provability to the messier, continuous, and physically grounded action spaces that embodied AI systems must navigate.
Read the full paper on arXiv · PDF