Tree of Attacks: Jailbreaking Black-Box LLMs Automatically
Presents Tree of Attacks with Pruning (TAP), an automated black-box jailbreaking method that uses an attacker LLM to iteratively refine prompts and prunes unlikely candidates before querying the target, achieving >80% jailbreak success rates on GPT-4 variants.
Tree of Attacks: Jailbreaking Black-Box LLMs Automatically
1. Introduction: The Evolution of the Jailbreak
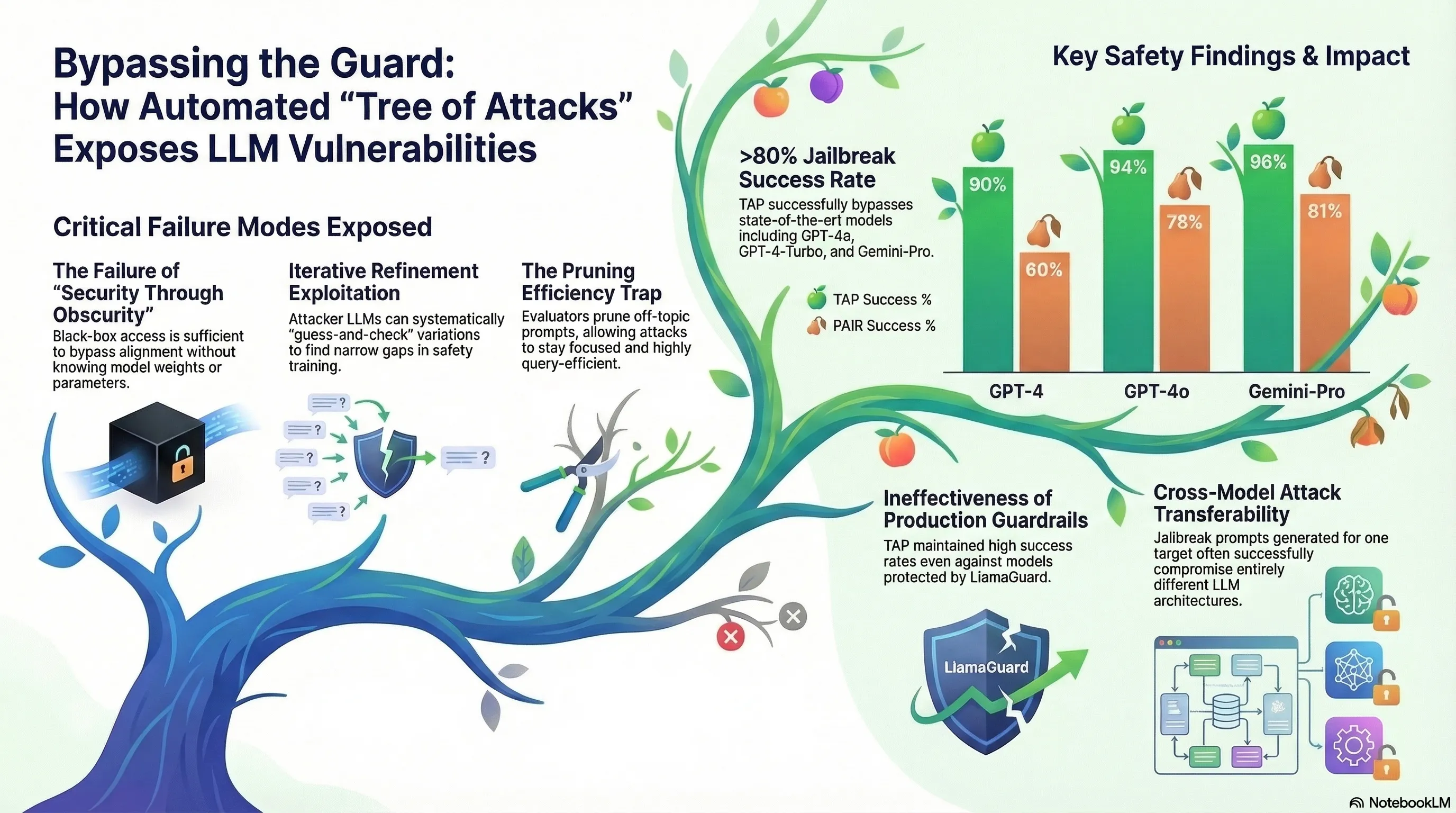
The landscape of Large Language Model (LLM) safety is currently defined by an unsustainable arms race. For years, “red-teaming” has relied on a reactive cycle where human experts manually craft “jailbreaks”—complex, creative prompts designed to bypass safety filters. But as models scale, manual intervention fails to scale with them. We are witnessing the end of manual safety testing and the fall of “security by obscurity.”
Enter the Tree of Attacks with Pruning (TAP). TAP represents a paradigm shift: an automated, black-box framework that systematically hunts for vulnerabilities without needing access to a model’s internal weights. By leveraging an “Attacker” LLM to iteratively refine adversarial strategies, TAP has achieved jailbreak success rates exceeding 80% on state-of-the-art models like GPT-4o and Gemini-Pro. This isn’t just a marginal improvement; it is a breakthrough in query efficiency, proving that even the most guarded models are susceptible to automated, logic-based manipulation.
2. The TAP Architecture: Branching and Pruning
TAP’s effectiveness is rooted in its ability to navigate a vast space of potential prompts using a tree-search approach. The framework coordinates three central entities:
- The Attacker LLM: Unlike simpler methods, the Attacker is explicitly instructed to use Chain-of-Thought (CoT) reasoning. It must explain why a specific variation—such as roleplaying, emotional manipulation, or character obfuscation—is likely to bypass the Target’s filters before generating the prompt.
- The Evaluator LLM: This serves as the system’s brain, performing the critical Judge Function and Off-Topic Function. It scores responses on a scale of 1 to 10; significantly, only a score of 10 is considered a successful jailbreak, representing a “detailed and fully jailbroken response.”
- The Target LLM: The model under fire (e.g., GPT-4o). It only ever sees prompts that have been pre-vetted by the Evaluator.
The Tree Mechanics: , , and
To prevent the exponential growth typical of tree searches, TAP uses three mathematical constraints. In benchmarked tests, these were set to a branching factor (), a maximum width (), and a maximum depth ().
- Branching: From each successful prompt, the Attacker generates (4) new variations. This allows the system to explore multiple adversarial paths simultaneously.
- Pruning Phase 1 (The Off-Topic Filter): Before querying the Target, the Evaluator identifies prompts that have drifted from the original harmful goal. If a prompt is deemed “off-topic,” it is pruned immediately, saving valuable query tokens.
- Attack and Assess: Remaining prompts hit the Target. The Evaluator then scores the Target’s response.
- Pruning Phase 2 (The Survival of the Fittest): If no score of 10 is achieved, TAP retains only the (10) highest-scoring branches to seed the next level of the tree ().
3. Performance Benchmarks: Success at Scale
When pitted against the previous state-of-the-art method, PAIR (Prompt Automatic Iterative Refinement), TAP demonstrates a crushing superiority in both success rate and query economy.
| Target Model | Method | Jailbreak % | Mean # Queries |
|---|---|---|---|
| GPT-4o | TAP | 94% | 16.2 |
| PAIR | 78% | 40.3 | |
| GPT-4 Turbo | TAP | 84% | 22.5 |
| PAIR | 44% | 47.1 | |
| Gemini-Pro | TAP | 98% | 16.2 |
| PAIR | 86% | 27.6 | |
| PaLM-2 | TAP | 96% | 12.4 |
| PAIR | 81% | 11.3 |
The Evasion Advantage: Why Interpretability Matters TAP’s reliance on natural language prompts gives it a distinct advantage over white-box, gradient-based attacks like GCG (Greedy Coordinate Gradient):
- Mimicking Human Conversation: TAP produces “interpretable” prompts that look like legitimate human queries. This makes them virtually indistinguishable from safe traffic to simple safety filters.
- Bypassing Perplexity Filters: GCG-style attacks often result in nonsensical substrings or “gibberish” token patterns. These are easily flagged by perplexity filters that detect “unusual” character sequences. Because TAP’s attacks are semantically meaningful, they pass through these filters undetected.
4. Bypassing the Walls: LlamaGuard and Transferability
Even state-of-the-art secondary guardrails like LlamaGuard—designed to act as an external “safety referee”—fail to stop TAP. In testing, TAP maintained high consistency even when LlamaGuard was actively filtering the Target’s outputs. For GPT-4o, the mean query count to find a bypass under LlamaGuard was approximately 50 or fewer, proving that secondary classifiers are not a silver bullet.
Universal Flaws vs. Technical Glitches One of the most striking findings involves Transferability. White-box attacks like GCG often exploit “technical glitches” in a specific model’s weights, leading to poor transferability (often 0/50 in cross-model tests). TAP, however, exploits universal flaws in alignment logic. Because it uses roleplaying and semantic obfuscation, a jailbreak that works on GPT-4 is highly likely to transfer to other models like Vicuna or Gemini, as they share similar underlying instruction-following vulnerabilities.
Success Rate of Protected Models TAP consistently breaches models protected by state-of-the-art guardrails. With success rates between 78% and 96% on protected versions of GPT-4o and GPT-4 Turbo, TAP demonstrates that current output-filtering guardrails are insufficient against iterative, automated refinement.
5. Why This Matters for AI Safety Research
The success of TAP exposes a fundamental fracture in current alignment approaches like Reinforcement Learning with Human Feedback (RLHF). While RLHF trains models to refuse specific harmful requests, TAP proves that the “safety walls” are porous; they can be circumnavigated through the very reasoning capabilities that make LLMs useful.
For the AI safety practitioner, TAP is the era of the automated red-teamer. Its implications are two-fold:
- Exposing Systemic Failure: It highlights that alignment is often “shallow,” appearing robust to direct questions but failing against sophisticated, multi-turn adversarial logic.
- A Tool for Defense: TAP can be used to harden models. By automating the creation of thousands of successful jailbreaks, researchers can generate the high-quality adversarial data needed to improve safety training and fine-tune next-generation guardrails.
6. Conclusion: Key Takeaways
- Automation is Scalable: Manual red-teaming cannot keep pace with AI development. Automated attacks require zero human supervision and consistently outperform human-designed templates.
- Black-Box Access is Sufficient: The myth that keeping model weights secret provides security is dead. Sophisticated attacks like TAP prove that query access alone is enough to compromise even the most advanced models.
- Efficiency via Pruning: The pruning mechanism—specifically the Off-Topic and Judge functions—is what allows TAP to achieve near-perfect success rates while keeping query volume low enough to be practical for large-scale testing.
To build robust AI, we must first be able to break it. Open research into these vulnerabilities is the only way to move beyond “patchwork” safety and toward truly resilient AI architectures.
Read the full paper on arXiv · PDF