Towards Intelligible Human-Robot Interaction: An Active Inference Approach to Occluded Pedestrian Scenarios
Proposes an Active Inference framework with RBPF state estimation and CEM-enhanced MPPI planning to safely handle occluded pedestrian scenarios in autonomous driving, validated through simulation experiments against multiple baselines.
Towards Intelligible Human-Robot Interaction: An Active Inference Approach to Occluded Pedestrian Scenarios
1. Introduction: The Ghost in the Blind Spot
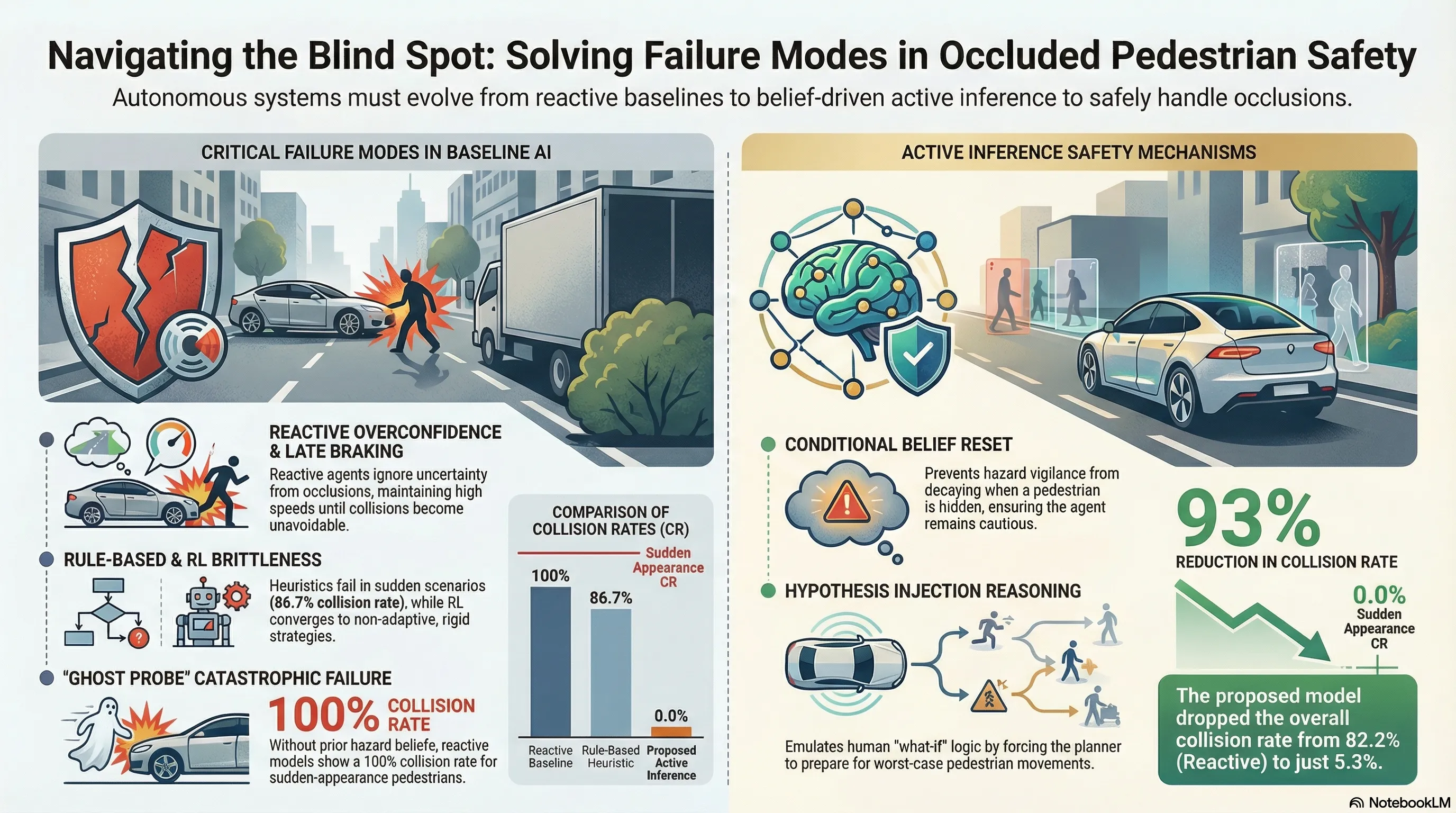
In the domain of autonomous driving, the “occluded pedestrian” represents one of the most persistent and lethal failure modes. A classic example is a bus stopped at a crosswalk: it creates a sensory blind spot where a pedestrian may suddenly emerge. Conventional architectures often fail in these “long-tail” scenarios—rare, safety-critical events that lie outside the dense regions of training distributions.
Rule-based systems are historically too rigid to adapt, while data-driven models like Deep Reinforcement Learning often act as “black boxes” that fail catastrophically under distribution shifts. Active Inference offers a biologically inspired, mechanism-driven alternative. By moving away from purely reactive driving, this framework enables proactive reasoning about latent hazards, allowing an agent to maintain a persistent belief in a pedestrian’s existence even when they are entirely occluded.
2. The Architecture of Belief: How Active Inference Works
Active Inference treats navigation as a continuous perception-action loop governed by the minimization of “free energy.” This framework aligns the vehicle’s internal generative model with environmental reality through two distinct processes:
- Perception (Minimizing Variational Free Energy): The agent aligns its internal belief with sensory observations. This is implemented via a Rao-Blackwellized Particle Filter (RBPF), which efficiently estimates the pedestrian’s hybrid state (discrete existence vs. continuous kinematics ). Crucially, a Kalman Filter is responsible for managing the continuous kinematic sub-states within each particle of the filter.
- Action (Minimizing Expected Free Energy): The planner selects a policy that balances:
- Pragmatic Value: Goal-seeking behavior, such as progress toward a destination and collision avoidance.
- Epistemic Value: Information-seeking behavior. The agent actively resolves epistemic uncertainty through visibility entropy, maneuvering to “peek” around occlusions to confirm or refute the presence of a hazard.
3. Safety Mechanisms: Mimicking Human Vigilance
To address the inherent uncertainty of occlusions, the framework introduces two novel mechanisms designed to emulate human-like cognitive resilience.
Conditional Belief Reset Standard filters often suffer from “belief decay”—if an object is not seen for several frames, the system’s probability of its existence drops toward zero. To maintain vigilance, the agent employs a Conditional Belief Reset. Following the logic of Equation 3, the kinematic state of a particle is reset to its initial hypothesis () if the pedestrian is unobserved () and the hypothesized occlusion zone remains unresolved (). This prevents the agent from “forgetting” a hazard simply because it is currently hidden.
Hypothesis Injection This mechanism facilitates counterfactual reasoning. The planner is forced to consider “what-if” scenarios by assigning a small fraction of particles () to represent worst-case latent intentions: Surge, Reverse, or Freeze. By evaluating trajectories against these injected hypotheses, the agent proactively adopts a defensive posture (such as swerving or early braking) before a threat is even visible.
4. Performance Breakdown: Active Inference vs. The Baselines
Empirical testing against three standard paradigms demonstrates that belief-driven planning provides a superior balance of safety and robustness.
| Method | Core Strategy | Safety Outcome (Avg. Collision Rate) | Adaptability (Static vs. Dynamic) |
|---|---|---|---|
| Reactive | Only reacts to visible threats. | 82.2% | Non-adaptive; ignores latent hazards. |
| Rule-based | Fixed deceleration near occlusions. | 41.3% | Static; fails in “Sudden Appearance.” |
| PPO-LSTM | Model-free Reinforcement Learning. | 27.5% | Brittle; converges to generic policies. |
| Active Inference | Belief-driven proactive planning. | 5.3% | Highly dynamic and adaptive. |
Synthesis of Failures: The PPO-LSTM agent exhibits a significant speed-safety trade-off; it is the “fastest” method with a Pass Time of 4.188s, yet its 27.5% collision rate proves it prioritizes efficiency at the cost of safety under distribution shifts. The Rule-based approach fails catastrophically in “Sudden Appearance” scenarios (86.7% Collision Rate). Because its deceleration rule is static, it cannot adapt to the high initial velocity of a pedestrian rushing from behind an obstacle, proving that “fixed rules” are no substitute for adaptive belief.
5. Tuning Cautiousness: The Role of Prior Beliefs
Safety designers can utilize the Initial Presence Belief () and the Hypothesis Injection Ratio () as “safety dials” to modulate system risk. These parameters allow for precise calibration of the vehicle’s “defensive intuition.”
According to the data in Table 1, increasing is the primary mechanism for mitigating risk in high-suddenness scenarios:
- Aggregate Performance: Increasing from 0.0 to 0.8 reduces the average Collision Rate across all five test scenarios from 75.0% to 5.3%.
- Corner Case Success: In the specific “Sudden Appearance” scenario, an initial belief of results in a 100% collision rate, which plummets to 0% when is tuned to 0.8.
6. The Path to Real-World Deployment
A modular deployment architecture is proposed to integrate this framework into existing autonomous stacks:
- Upstream (Scene Understanding): Vision-Language Models (VLMs) analyze the semantic context (e.g., “bus stopped at a crosswalk”).
- Midstream (Active Inference Planner): The VLM output initializes the Bayesian prior (), which the planner uses to calculate a kinematically feasible, safety-optimized trajectory.
- Downstream (Execution): Low-level controllers translate the trajectory into steering and throttle commands.
7. Conclusion & Critical Takeaways
Belief-driven planning moves autonomous systems away from brittle, reactive paradigms and toward an “intelligent intuition” capable of navigating high-uncertainty, long-tail scenarios. For AI safety researchers, the primary value lies in the framework’s inherent intelligibility and robustness.
Key Takeaways:
- Interpretability: Actions are not black-box outputs; they are direct, mathematical reflections of internal belief states regarding latent intentions and risks.
- Robustness: The system demonstrates graceful degradation under uncertainty, adopting a defensive posture rather than suffering the “overconfidence” failures typical of model-free RL.
- Real-Time Feasibility: Implemented in JAX on an NVIDIA RTX 3090, the framework achieved an average computation time of 17.69ms, fitting comfortably within standard 10Hz control loops required for real-world deployment.
Read the full paper on arXiv · PDF