ThermoAct:Thermal-Aware Vision-Language-Action Models for Robotic Perception and Decision-Making
Integrates thermal sensor data into Vision-Language-Action models to enhance robot perception, safety, and task execution in human-robot collaboration scenarios.
ThermoAct:Thermal-Aware Vision-Language-Action Models for Robotic Perception and Decision-Making
1. Introduction: The Critical Blind Spot in Robotic Perception
Imagine a robot tasked with tidying a home workspace. Its high-resolution RGB camera identifies a hair straightener on the counter with perfect precision. However, it lacks the “knowledge” that the device was recently used and is currently idling at 200°C. To a vision-only system, the device looks identical whether it is ice-cold or dangerously hot. Without thermal awareness, the robot attempts a standard grasp, leading to a systematic failure—not of identification, but of state perception—that could damage the end-effector or ignite a fire.
This represents the primary blind spot in modern embodied AI. While Vision-Language-Action (VLA) models have revolutionized natural language grounding, they remain “temperature-blind.” Relying solely on 2D/3D visual data is insufficient for real-world safety and nuanced reasoning, such as identifying a “cold Coke” (typically 15–18°C) among identical-looking room-temperature cans. ThermoAct solves this by introducing a hierarchical framework that integrates thermal sensing directly into the VLA pipeline, transforming robots from machines that merely “see” into assistants that truly “perceive.”
2. The Architecture of Thermal Intelligence
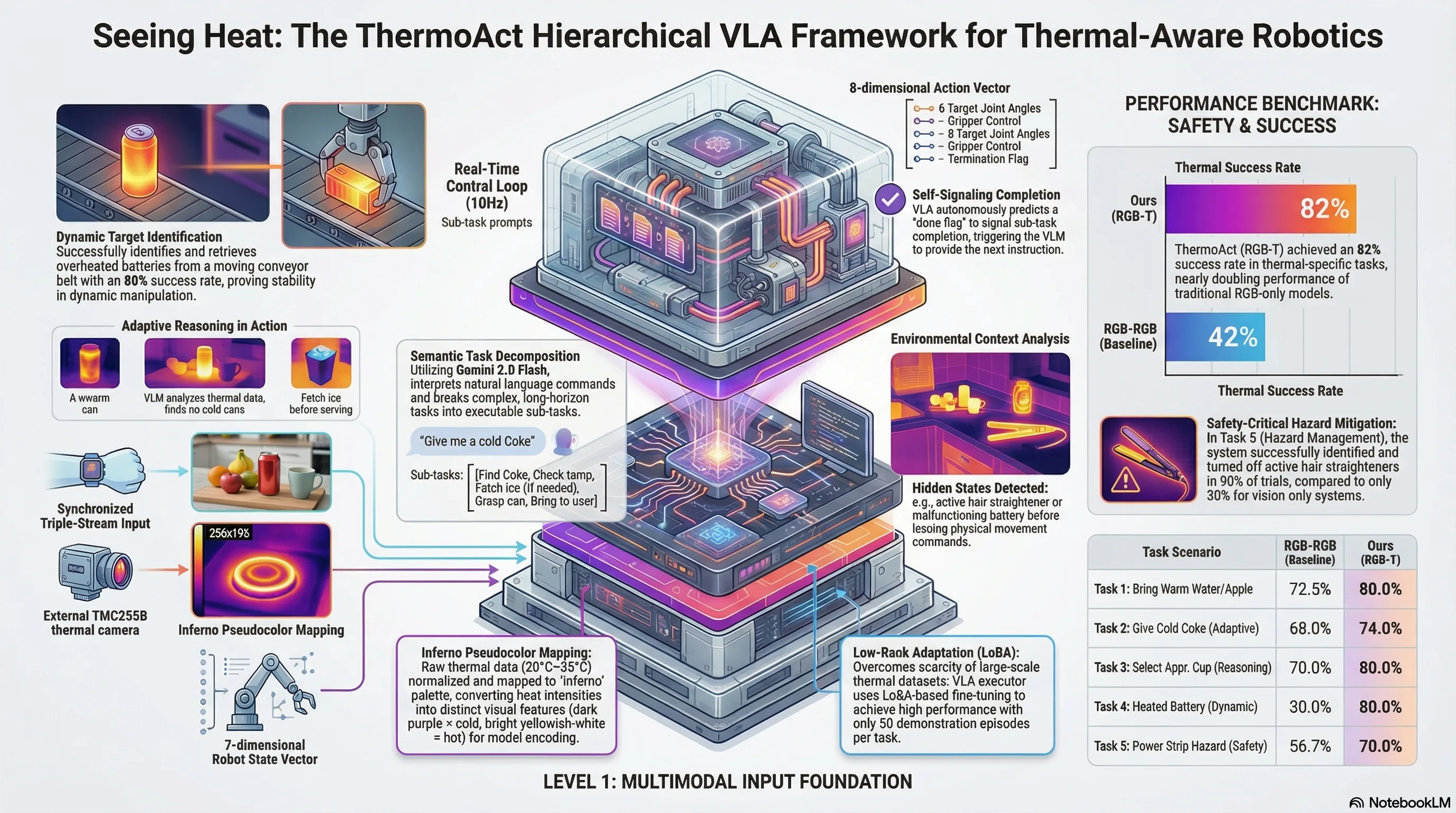
The ThermoAct framework is built on a two-part hierarchical structure. This design choice is a strategic response to a fundamental challenge in robotics: large-scale thermal datasets are remarkably scarce compared to RGB data. By splitting the architecture, we can offload complex reasoning to models with massive pre-existing knowledge while specializing the motor control.
- The VLM Planner (Reasoning): We utilize Gemini 2.0 Flash as a high-level reasoning engine. To ensure robust task decomposition, the Planner uses a structured guideline prompt consisting of Role (e.g., “You are a planning assistant…”), Environment Instructions, and Output Formats with specific examples. This allows the Planner to “think” through thermal hazards and decompose high-level commands into actionable sub-tasks based on fused RGB and thermal inputs.
- The VLA Executor (Action): For low-level control, we employ a fine-tuned vision-language-action flow model. This executor operates at 10Hz, predicting high-frequency actions by incorporating a 7-dimensional robot state (joint angles and gripper values) alongside multimodal imagery.
By using the VLM for “reasoning” and the flow model for “reaction,” ThermoAct overcomes the data-scarcity hurdle. We leverage the VLM’s vast general intelligence to handle thermal logic, leaving the VLA to master the specific physical motor skills required for the task.
3. From Raw Heat to Actionable Data: The Processing Pipeline
To integrate thermal signals into a VLA, we must present the data in a way the model’s vision encoder can digest. Our pipeline “tricks” the vision-based transformer into seeing heat as a visual texture it already knows how to process.
- Linear Normalization: Raw thermal data is normalized within a target indoor range of 20°C to 35°C.
- 8-bit Grayscale Quantization: The normalized values are converted into 8-bit intensities.
- INFERNO Pseudocolor Mapping: We map these intensities to the INFERNO palette, which assigns dark purple to lower temperatures and bright yellowish-white to higher temperatures.
This specific mapping is critical. By converting thermal data into distinct visual features, we allow the VLA to encode heat as a “learned texture.” This enables the model to prioritize thermal cues with the same weight it gives to RGB edges and colors.
4. Real-World Validation: Five Scenarios for Thermal Awareness
We validated ThermoAct using a 7-DoF Kinova Gen3 Lite robot across five scenarios. The following results, recorded at the 50-episode fine-tuning mark, demonstrate that adding a thermal modality (RGB-T) significantly stabilizes performance compared to RGB-only baselines.
ThermoAct Task Performance (Mean Sub-task Success Rates)
| Task Scenario | Success Rate (RGB-RGB Baseline) | Success Rate (ThermoAct RGB-T) |
|---|---|---|
| 1. Bringing Warm Water/Apple | 72.5% ± 25.0 | 80.0% ± 11.5 |
| 2. The “Cold Coke” Problem | 68.0% ± 13.0 | 74.0% ± 13.4 |
| 3. Contextual Cup Selection | 70.0% ± 42.4 | 80.0% ± 28.3 |
| 4. Conveyor Belt Safety (Dynamic) | 30.0% ± 0.0 | 80.0% ± 0.0 |
| 5. Hazard Mitigation (Power Strip) | 56.7% ± 23.1 | 70.0% ± 17.3 |
Scenario Highlights:
- The “Cold Coke” Adaptive Plan: This task showcased the VLM’s reasoning. If the Planner identifies a can within the 15–18°C range, it proceeds to pick. If no cold can is detected, the VLM autonomously generates a fallback plan: “Press the button on the ice maker” and “Pick up ice cup.”
- Conveyor Belt Safety: In this dynamic environment, the robot identified a single overheated battery among three moving units. While the RGB baseline failed nearly every attempt (30%), ThermoAct maintained an 80% success rate, proving that thermal identification remains robust even during motion.
- Hazard Mitigation: The system successfully identified an active hair straightener and executed a “Turn Off” action—a task that is visually indistinguishable from moving a cold straightener but carries vastly different safety implications.
5. Why This Matters for AI Safety and Red-Teaming
For AI safety researchers, ThermoAct represents a shift toward “failure-first” design. We are targeting systematic, covert errors that evade standard RGB-based evaluation.
- Proactive Failure Prevention: ThermoAct detects hazards invisible to RGB cameras, such as malfunctioning lithium batteries or active induction cooktops.
- Robustness to Visual Ambiguity: Thermal sensing remains functional in low-light or smoke-filled environments where traditional vision fails.
- Physical-Property Awareness: By integrating temperature, we move beyond simple image-to-action mapping toward a model that understands the state of the world, leading to safer human-robot collaboration.
6. Current Limitations and the Road Ahead
Our analysis reveals three primary hurdles for the next generation of thermal-aware robots:
- The “Hovering” Problem: A slight performance degradation was observed in tasks requiring high-precision depth. Without integrated depth sensors, the robot occasionally “hovers” over objects or requires multiple grasp attempts.
- Field-of-View (FoV) Constraints: Wrist-mounted cameras often lose sight of the thermal profile during the final “picking” phase. Future iterations will require better fusion between external and egocentric sensors.
- Dataset Scaling: Current success relies on small, task-specific datasets. To achieve open-world generalization, we need to scale multimodal datasets to include a wider variety of objects and extreme temperature ranges.
7. Conclusion: A New Standard for Multimodal Robots
The integration of thermal sensing via ThermoAct moves us closer to a new standard in human-centric robotics. By bridging the gap between visual identification and physical-property awareness, we transform robots into assistants that can navigate the hidden risks of our world.
For the AI safety community, the takeaway is clear: Safety benchmarks for embodied AI must move beyond vision. Incorporating thermal modalities in red-teaming and safety benchmarks is not just a performance boost—it is a prerequisite for preventing the “invisible” failures that occur when a robot is blind to the heat of its environment. It is time we give our robots the “sense of touch” they need to work safely alongside us.
Read the full paper on arXiv · PDF