There Will Be a Scientific Theory of Deep Learning
Fourteen DL-theory researchers argue that an empirical mechanics of training dynamics is emerging, and that quantitative theory is the only reliable path to distinguishing structurally expected failures from contingent optimization accidents.
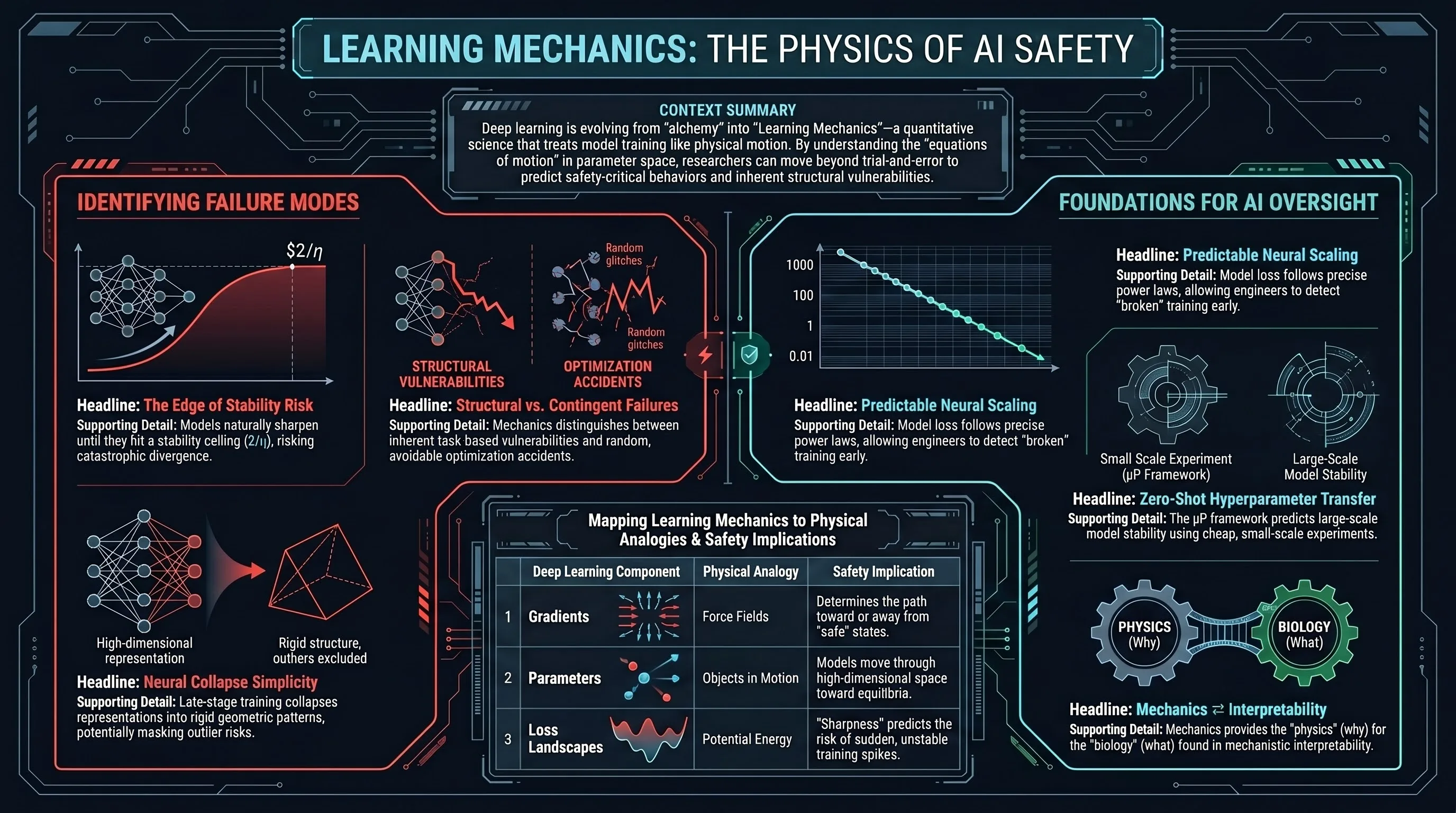
There Will Be a Scientific Theory of Deep Learning
1. Introduction: Beyond the Black Box
Deep learning is currently the most technologically significant yet scientifically inscrutable member of the machine learning pantheon. While our models achieve superhuman performance across diverse modalities, they are largely treated as “black boxes.” Our engineering capacity to scale these systems has far outpaced our theoretical grasp of why they work; today’s models are often trained via trial and error—a form of modern alchemy—rather than first principles.
However, the evidence is now undeniable: a unified scientific framework is emerging to resolve this tension. This field seeks to characterize training dynamics, hidden representations, and performance with the same rigor found in the physical sciences. We are moving toward a framework I call Learning Mechanics. This transition represents the shift from observing mysterious “emergent” phenomena to predicting them through the “equations of motion” of the learning process itself.
“This paper makes the case that, yes, there will be a scientific theory of deep learning; that we can see pieces of this theory starting to emerge; and that this theory will take the form of a mechanics of the learning process.”
2. The Five Pillars of a New Science
The emergence of Learning Mechanics is driven by five distinct, growing bodies of work that move the field toward a predictive science:
- Solvable Settings: We utilize “hydrogen atoms” for AI—pared-down models like Deep Linear Networks (to study nonlinear parameter dynamics) and Kernel Regression (to study nonlinear function learning).
- Tractable Limits: By treating networks as “infinite” via Mean-Field limits, we simplify the chaotic interactions of billions of neurons into manageable mathematical structures.
- Macroscopic Laws: We have identified simple patterns like Neural Scaling Laws and the Edge of Stability. Crucially, we now recognize that gradient flow obeys Noether’s Principle, where symmetries in architecture (like rotation or rescaling) lead to specific conservation laws in weight dynamics.
- Hyperparameter Theory: We are disentangling the “knobs”—learning rate, batch size, and initialization—to reveal simpler effective dynamical systems.
- Universal Behaviors: We are witnessing the emergence of “Platonic” representation universality, where different architectures and datasets often converge on similar internal solutions, suggesting that the structure of the data itself dictates the optimal representation.
Mapping Deep Learning to Physics
| Research Pillar | Deep Learning Approach | Physics Analog |
|---|---|---|
| Solvable Settings | Deep linear networks, NTK | Harmonic oscillator, hydrogen atom |
| Tractable Limits | Infinite width () | Thermodynamic limit () |
| Macroscopic Laws | Scaling Laws, Noether’s Principle | Kepler’s laws, Conservation laws |
| Hyperparameter Theory | and width-scaling | Nondimensionalization, Reynolds number |
| Universal Phenomena | Platonic representation convergence | Critical phenomena, renormalization group |
3. Defining the “Mechanics” of Learning
The “mechanics” framing is a precise analogy to the branch of physics studying how forces determine the movement of objects. In deep learning, a model is an object moving through a high-dimensional parameter space.
- Movement: Just as an object follows a trajectory in physical space, a model’s weights evolve during training.
- Forces: In our system, the “forces” driving the model are mediated by Gradients of the loss function.
- Equilibrium: Systems reach “rest” when they settle into local minima of the loss landscape, representing the “Equations of Motion” for intelligence.
The Seven Desiderata of Learning Mechanics
To achieve maturity, this theory must be:
- Fundamental: Proceeding logically from first-principles calculations.
- Mathematical: Making unambiguous quantitative statements, not just qualitative descriptions.
- Predictive: Supported by repeatable, empirical measurements across scales.
- Comprehensive: Describing training, representations, and weights in a unified picture.
- Intuitive: Striving for simple insight that demystifies complexity.
- Useful: Reducing the need for trial-and-error engineering via predictable principles.
- Humble: Explicitly defining its own boundaries and regimes of applicability.
4. The Lazy vs. Rich Dichotomy
A central discovery in modern theory is the “phase” transition between two training regimes, controlled by the initialization scale and the output multiplier ():
- The Lazy Regime: Occurs when the network changes only negligibly from its initialization. While mathematically tractable (modeled by the Neural Tangent Kernel), these models treat features as “frozen” and fail to learn new representations from data.
- The Rich Regime: Occurs when hidden representations adapt significantly to the data’s internal geometry. This “feature learning” phase is essential for the superhuman performance of modern AI.
The Discretization Hypothesis
The Discretization Hypothesis posits that finite neural networks are essentially discretized versions of infinite continuum systems. In this view, increasing model width and depth acts like increasing the resolution of a simulation—it reduces the “numerical error” of the underlying continuum process of learning.
Key Takeaway: The Role of Initialization The scale of initialization—specifically the Maximal Update Parameterization ()—is the “knob” that prevents models from remaining “lazy” as they scale. ensures that features evolve optimally regardless of width, enabling : the ability to tune hyperparameters on tiny models and transfer them zero-shot to massive production systems.
5. Why This Matters: Science, Engineering, and Safety
The shift to Learning Mechanics has profound implications for how we treat artificial intelligence:
- Scientific Discovery: Much as the steam engine motivated thermodynamics, studying artificial neural networks reveals universal principles of learning. This may provide the ultimate mathematical language for understanding biological neuroscience and the nature of cognition.
- Practical Engineering: We must replace “alchemy” with predictable scaling. Using , we can design architectures with mathematical precision, treating hyperparameters not as guesses, but as system constants that follow known laws.
- AI Safety & Governance: For a “failure-first” safety audience, this theory is a prerequisite for control. Learning Mechanics allows us to distinguish between “structurally expected failures” (inherent to the scaling laws or the feature-learning regime) and “contingent optimization accidents” (random noise or initialization luck). Quantitative theory provides the “white-box” clarity needed for reliability, oversight, and the rigorous auditing of powerful systems.
6. The Symbiosis: Physics vs. Biology
Learning Mechanics acts as the “Physics” (low-level/quantitative) while Mechanistic Interpretability acts as the “Biology” (high-level/circuit-based) of AI.
| Perspective | Analogy | Focus |
|---|---|---|
| Learning Mechanics | Physics | Low-level laws, dynamics, , and first principles. |
| Mechanistic Interpretability | Biology | Reverse-engineering circuits and individual features. |
Mechanics formalizes the implicit assumptions used by interpretability researchers. For instance, we can now provide mathematical foundations for Linear Representability (the idea that features are directions in space) and Sparsity (why certain circuits only activate on specific inputs), deriving them from the dynamics of the training process itself.
7. Conclusion: The Road Ahead
The field of Learning Mechanics is in its infancy. The “Holy Grail” for the next decade is the ability to predict scaling law exponents a priori—deriving the performance of a model from the first-principles statistics of the data and architecture before a single watt of compute is spent.
This scientific project requires cross-pollination from Singular Learning Theory, Tensor Programs, and Mean-Field analysis. We invite researchers to prioritize simplicity and insight over technical complexity.
Final Takeaways
- Deep Learning is a Science: We are graduating from heuristic engineering to a predictive “mechanics” of learning.
- Scale is Lawful: The behavior of the largest models is governed by predictable macroscopic laws and symmetry-specific statistics.
- Theory is the Path to Safety: A mathematical understanding of learning mechanics is the only reliable way to ensure the oversight, reliability, and ultimate control of powerful intelligence.
Read the full paper on arXiv · PDF