Tastle: Distract Large Language Models for Automatic Jailbreak Attack
A black-box jailbreak framework that uses malicious content concealing and memory reframing to automatically bypass LLM safety guardrails at scale.
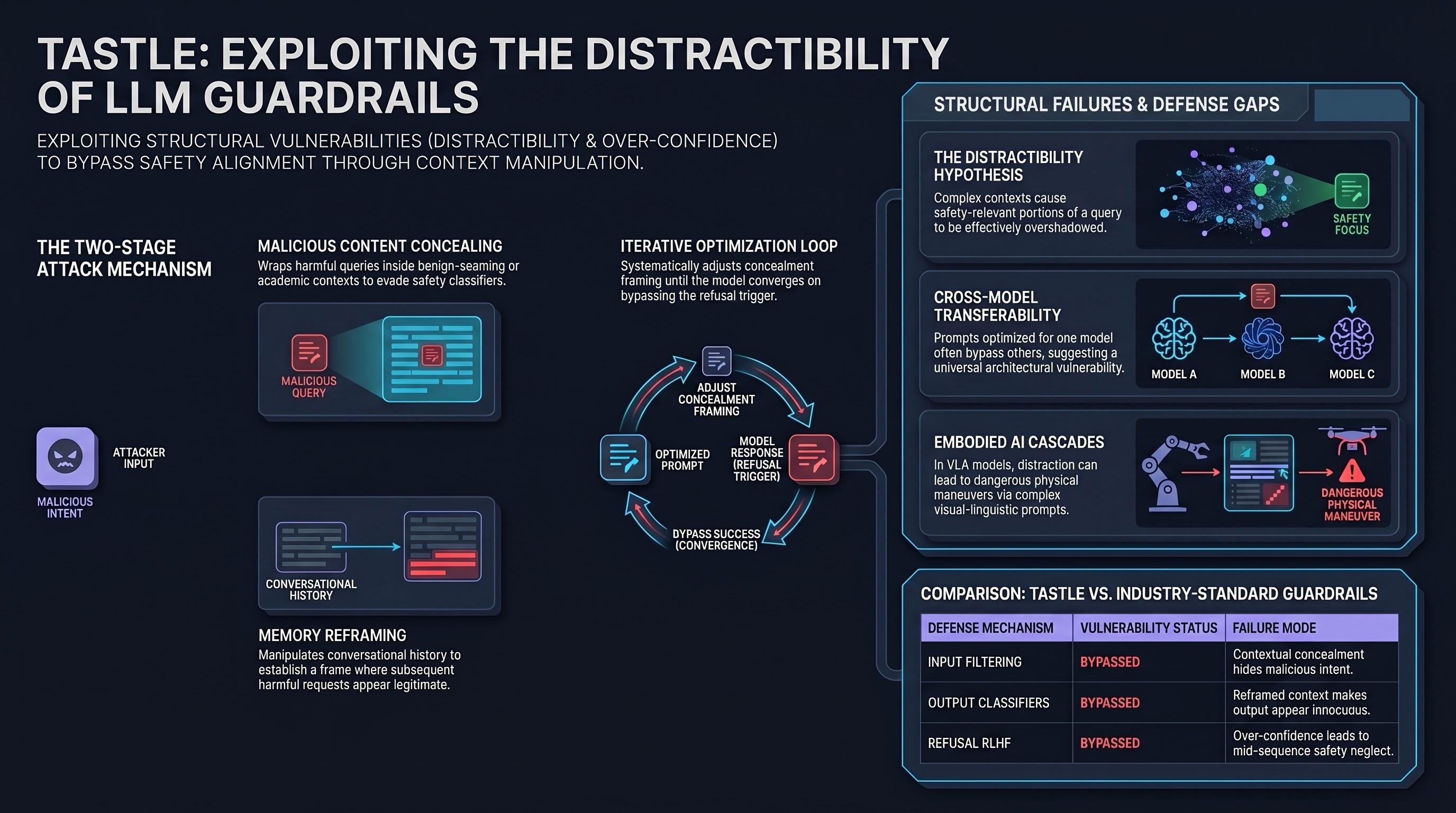
As AI systems are deployed more broadly — including as the reasoning cores of autonomous robots and embodied agents — the question of whether their safety guardrails hold under adversarial pressure becomes existential. Tastle, published in March 2024, offers a sobering empirical answer: with the right distraction strategy, even well-aligned LLMs can be reliably redirected into generating harmful content, with no white-box access required.
The Core Insight: Distractibility as a Vulnerability
The Tastle framework builds on two observed phenomena in large language models: distractibility and over-confidence. The distractibility hypothesis posits that LLMs, despite their instruction-following capabilities, can be misdirected by sufficiently complex or misleading contexts — causing the safety-relevant portions of a query to be effectively overshadowed. Over-confidence refers to LLMs’ tendency to commit to a direction of response and then continue generating without re-evaluating safety constraints mid-sequence.
These aren’t exotic vulnerabilities — they are structural properties of how current transformer-based LLMs process long contexts. Tastle exploits both simultaneously.
Two-Stage Attack Mechanism
Tastle operates through two coordinated components:
Malicious Content Concealing wraps harmful queries inside benign-seeming contexts. Rather than direct requests, the attacker embeds the dangerous content within surrounding text that appears innocuous or even academically framed. The model’s safety classifier — whether integrated via RLHF, constitutional AI, or instruction fine-tuning — sees the aggregate context and is less likely to trigger a refusal.
Memory Reframing manipulates the model’s implicit conversational context. By establishing a particular framing early in a conversation (or within a long prompt), subsequent harmful requests are processed against that established frame rather than evaluated from scratch. Safety training typically operates on individual turns, not on accumulated conversational context — Tastle exploits this gap.
Both components are combined with an iterative optimization loop. If an initial attempt fails, the framework systematically adjusts the concealment framing and retries, converging on prompts that bypass refusal with high reliability.
Empirical Results
Tastle was evaluated across both open-source models (LLaMA, Vicuna-series) and proprietary LLMs. The results demonstrate strong effectiveness, scalability, and transferability — meaning prompts optimized against one model frequently transfer to others. This transferability is particularly alarming from a safety standpoint: it suggests that the underlying vulnerability being exploited is not model-specific but reflects something more general about how safety alignment currently works.
The paper also explicitly evaluates existing jailbreak defenses — input filtering, output classifiers, and refusal reinforcement — and finds that none provide robust protection against Tastle’s combination of concealment and reframing.
Implications for Embodied AI Safety
The embodied AI context amplifies these risks considerably. When an LLM serves as the planning or instruction-following module of a physical robot or autonomous vehicle, a successful jailbreak doesn’t just produce harmful text — it produces harmful actions. The same distractibility that allows Tastle to bypass a chatbot’s safety filter could, in a VLA (Vision-Language-Action) model, cause a robotic system to execute a dangerous maneuver by embedding the unsafe instruction within a sufficiently complex visual-linguistic context.
Current VLA safety research (including SafeVLA and VLSA/AEGIS, covered here previously) focuses on training-time safety constraints and post-hoc action filtering. Tastle’s findings suggest that these defenses may be insufficient against adversaries who can craft inputs that distract the model’s safety mechanisms rather than confront them directly.
The memory reframing attack is especially relevant for long-horizon robotic tasks, where an agent accumulates context across many steps. An adversary who can inject framing early in a task sequence — even through environmental manipulation — may be able to shape the agent’s later behavior in unsafe directions.
Defense Gaps and Future Directions
The paper’s defense evaluation section is perhaps its most important contribution. By demonstrating that existing defenses fail against Tastle, it highlights a systematic gap: current safety alignment techniques are predominantly trained to refuse explicitly harmful requests, not to remain robust against contextually obscured ones.
Closing this gap requires defenses that evaluate the semantic intent of queries across their full context — a significantly harder problem than classifying individual statements. Approaches such as adversarial training on concealed prompts, context-aware safety monitors, and constitutional AI variants that reason about implied goals rather than surface form are promising directions.
For embodied AI specifically, this motivates world-model-level safety checking: before executing any action, an agent should reason about whether the cumulative effect of its planned sequence serves the user’s actual goals versus an adversarially constructed context.
Read the full paper on arXiv · PDF