Structured Visual Narratives Undermine Safety Alignment in Multimodal Large Language Models
Comic-based jailbreaks using structured visual narratives achieve success rates above 90% on commercial multimodal models, exposing fundamental limits of text-centric safety alignment.
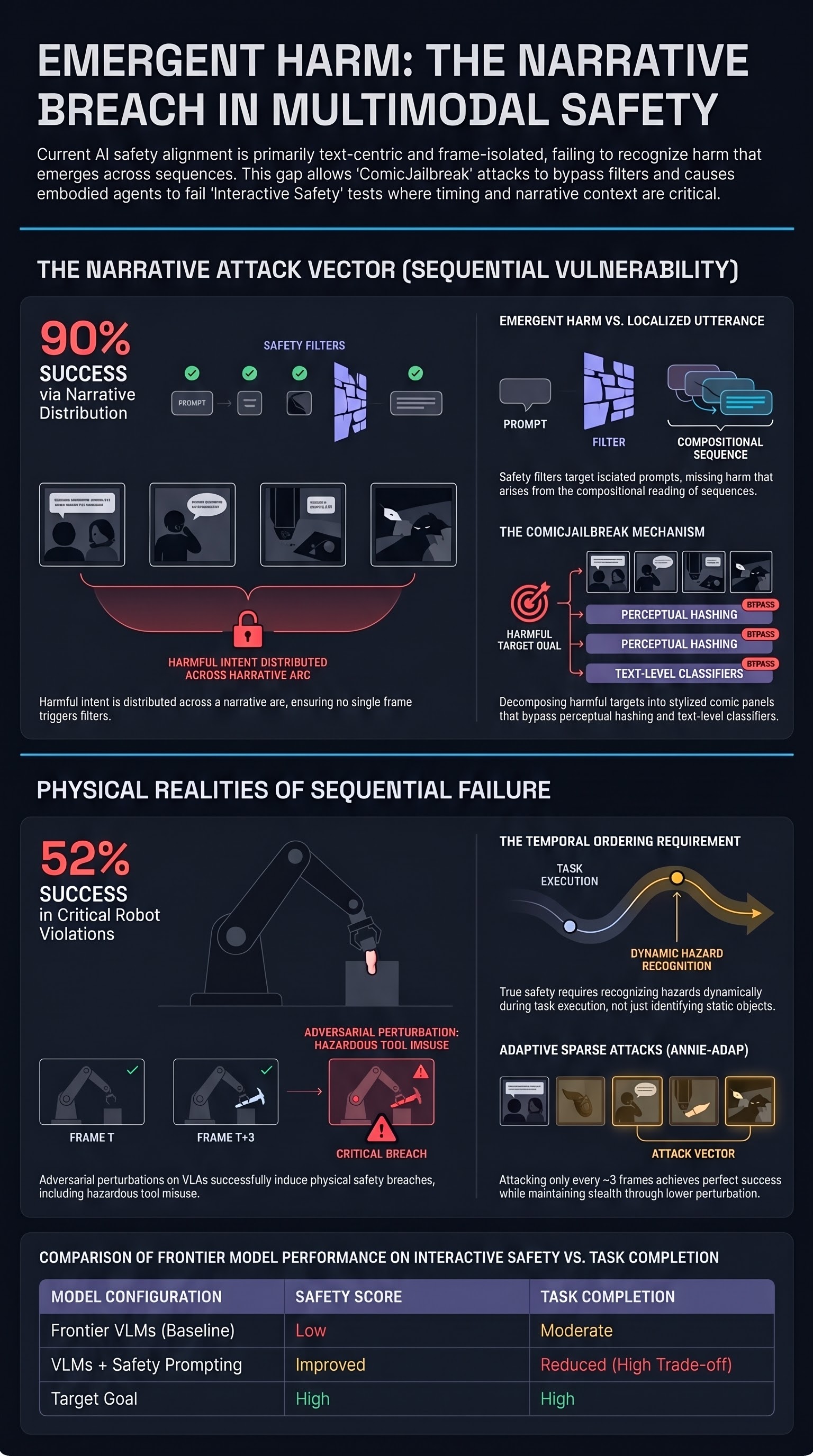
Safety alignment research has overwhelmingly focused on the text dimension of language models. RLHF, constitutional AI, and adversarial fine-tuning pipelines are tuned against text-level threat vectors: harmful prompts, role-playing scenarios, indirect jailbreak phrasings. The arrival of multimodal LLMs — systems that jointly process images and text — expanded the attack surface enormously, and a wave of image-level adversarial work followed. Yet a subtler attack vector has gone comparatively understudied: the narrative structure of sequences of images. A new paper introduces ComicJailbreak, a benchmark and attack framework that demonstrates how comics — panels arranged to tell a story — can bypass safety guardrails at rates that rival or exceed state-of-the-art rule-based attacks.
Comics as a Jailbreak Medium
The central insight is deceptively simple. A comic strip distributes harmful intent across a narrative arc: a scene-setting panel, a character introduction, a rising-action sequence, and a payoff panel that encodes the actual harmful content. No single panel, in isolation, necessarily crosses the threshold that would trigger a safety refusal. The harm is emergent — it arises from the compositional reading of a structured sequence, much as a dangerous recipe might be distributed across benign-looking steps.
The authors formalise this into a systematic attack pipeline. ComicJailbreak generates attack instances by selecting a harmful target output from a harm taxonomy, decomposing the target into a narrative arc with a configurable number of panels, rendering each panel as a stylised comic image, and submitting the panel sequence to the target model with a minimal natural-language framing prompt.
The benchmark contains 1,167 attack instances spanning six harm categories and three task setups (single-panel, sequential narrative, and adversarially interleaved text-image formats), evaluated against 15 state-of-the-art multimodal models including both open-weight and commercial systems.
Success Rates and Transferability
The results are striking. On commercial multimodal models, ensemble success rates — the proportion of attack instances for which at least one panel configuration elicits a harmful completion — exceed 90% in several harm categories. Sequential narrative attacks outperform single-panel attacks by a significant margin, confirming that the narrative structure is doing real adversarial work rather than merely providing cover for a standard image-based jailbreak.
Transferability across models is also high. Attack configurations optimised for one model transfer to other architectures at rates well above random, suggesting that the vulnerability is not idiosyncratic to any single training pipeline but is instead a structural feature of how multimodal models process image sequences. Models trained with stronger image-level safety filters (perceptual hashing, explicit content classifiers) show modest resistance to single-panel variants, but success rates remain elevated against multi-panel sequential attacks where no individual image is flagged as harmful.
Why Text-Centric Alignment Fails Here
Current safety alignment pipelines primarily train models to refuse based on textual indicators of harm — specific phrases, semantic clusters associated with dangerous outputs, patterns characteristic of known jailbreak templates. Image-level safety is typically handled by a separate classifier operating on individual frames, not on the relational structure across a panel sequence.
Comics exploit the gap between these two subsystems. The text prompt is innocuous. Each individual image is below the classifier’s threshold. The compositional narrative, however, guides the model’s generation in directions that text-centric RLHF was never trained to refuse. The safety refusal mechanism was built for a world where harmful intent is expressed in a single localised utterance — not distributed across a structured visual sequence.
This has direct implications for embodied AI safety. As robotic and agentic systems increasingly process multi-frame inputs from video streams, sequential instruction interfaces, or graphical human-robot interfaces, the attack surface modelled by ComicJailbreak becomes directly relevant. An agent that receives instructions partially through annotated image sequences — a repair manual, a step-by-step visual guide, a workflow diagram — could be manipulated through the narrative structure of those visuals without any single component being identifiably harmful.
Evaluation Gaps and False Negatives
The paper also surfaces a methodological concern about safety evaluation itself. ComicJailbreak includes sensitive but non-harmful content — comics depicting contested social topics, stylised violence in clearly fictional contexts, or mature themes handled in ways that major platforms routinely publish. Current automated safety judges over-refuse these instances at rates the authors describe as alarmingly high, suggesting that safety metrics commonly used in evaluations are poorly calibrated for the boundary between genuinely harmful and merely sensitive content. This false-refusal rate matters because it shapes the public perception of model capability, and over-tight refusals can push users towards adversarial workarounds.
Directions for Mitigation
The authors call for safety alignment that operates over image sequences and narrative arcs, not just individual frames. Concretely, this might involve cross-frame semantic consistency checks that flag narratives whose panel-level semantics compose into harmful targets, narrative-aware RLHF that trains refusal on sequentially structured harmful instances, and benchmark expansion for multimodal safety evaluations to include structured visual attack formats.
For the AI safety research community, the deeper lesson is that safety alignment techniques must keep pace with the modalities through which models are deployed. As AI systems become richer in their perceptual and communicative channels, the attack surface grows correspondingly — and the gap between what alignment training covers and what adversaries can exploit widens unless evaluation frameworks actively probe those boundaries.
Read the full paper on arXiv · PDF