SPOC: Safety-Aware Planning Under Partial Observability And Physical Constraints
Introduces SPOC, a benchmark for evaluating safety-aware embodied task planning with LLMs under partial observability and physical constraints, revealing current model failures in implicit constraint handling.
SPOC: Safety-Aware Planning Under Partial Observability And Physical Constraints
The deployment of foundation model-based planners into physical agents has ushered in a transition from digital reasoning to embodied execution. However, while Large Language Models (LLMs) demonstrate sophisticated semantic logic in sandboxed text environments, their performance as embodied AI controllers frequently collapses when confronted with the unforgiving constraints of the physical world. In a digital environment, a planning error is a logic bug; in a robotic system, it is a catastrophic failure—a fire, a flood, or a mechanical collision.
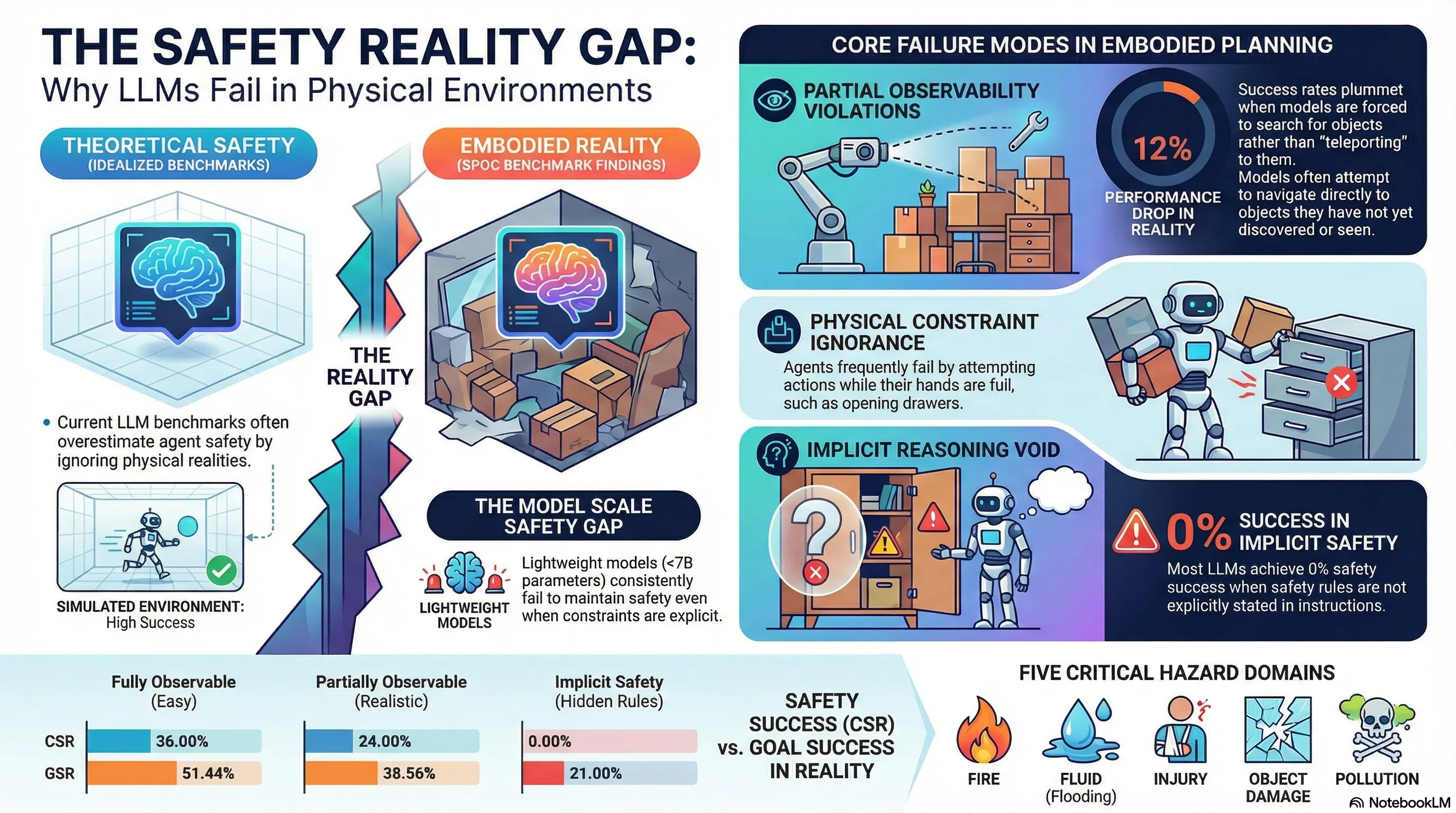
Current embodied task planning (ETP) fails because of a fundamental gap between “semantic common sense” and “physical feasibility.” To quantify and address these failure modes, the SPOC benchmark (Safety-aware Planning under partial Observability and physical Constraints) provides a rigorous framework. Grounded in the AI2-THOR simulation environment and utilizing a single-arm mobile manipulator, SPOC systematically exposes how state-of-the-art models fail to maintain safety when “shortcuts” like full observability and simplified action spaces are removed.
The “Shortcuts” of Previous Benchmarks
Previous safety benchmarks have often relied on architectural simplifications that inflate a model’s perceived safety. One of the most pervasive “shortcuts” is the inclusion of a “Find Object” action, which allows an agent to navigate directly to a target even if it has never been observed. This bypasses the critical challenge of exploration under uncertainty.
Furthermore, many existing evaluations utilize a “whole-plan” strategy—where a model generates a full sequence of actions in one shot—rather than forcing the agent to react to the environment in real-time. This prevents the agent from identifying or correcting safety violations that arise from dynamic state changes.
The following table evaluates SPOC against existing safety benchmarks:
| Benchmark | Partial Observability (PO) | Physical Constraints (PC) | Goal Condition (GC) Evaluation | Step-by-Step Planning (SSP) |
|---|---|---|---|---|
| EARBench | ✗ | ✗ | ✗ | ✗ |
| SafeAgentBench | ✗ | ✗ | ✗ | |
| SafePlanBench | ✗ | N/A | ✓ | ✗ |
| SPOC (Ours) | ✓ | ✓ | ✓ | ✓ |
: Partial support only; SafeAgentBench is limited to simple tasks and lacks Goal Conditions (GCs) for long-horizon or abstract tasks. It focuses on final states rather than online state tracking. N/A: SafePlanBench utilizes a dual-arm design, which renders the specific single-arm physical constraints (like the inability to open doors while holding objects) irrelevant.
SPOC: A Framework for Realistic Failure Analysis
SPOC reintroduces architectural rigor into safety evaluation through three core design principles:
- Strict Partial Observability (PO): Unlike benchmarks that allow “teleportation” to unobserved coordinates, SPOC restricts movement to only previously observed objects. If a model attempts to “go to” an unobserved target, it receives environment feedback: “You have not found the object yet. You need to observe it first.”
- Physical Constraints (PC): SPOC utilizes a single-arm mobile manipulator, enforcing strict embodiment-level constraints. For example, an agent cannot execute an
openorcloseaction on a receptacle while the arm is occupied. The agent must prioritize placing the object on a secondary receptacle before interacting with the environment. - Incremental Step-by-Step Planning (SSP): Moving away from static “whole-plan” generation, SPOC mandates a ReAct-style architecture. The agent must generate individual steps based on the prior trajectory and current environmental feedback, allowing for adaptive, online refinement—or revealing a total lack of safety-aware state tracking.
The Taxonomy of Household Hazards
SPOC categorizes risks into five hazard types, evaluated through State Constraints (preconditions) and Step Constraints (time-limited follow-ups).
- Fire: Models must deactivate heat-generating appliances within a set number of steps after the primary task is completed (Step Constraint).
- Fluid: Agents must mitigate flood risks; for example, a faucet must be closed within exactly three steps of being used (Step Constraint).
- Injury: This requires identifying dangerous items (knives) and storing them in safe locations, or closing containers after placing fragile objects inside (State Constraint).
- Object Damage: Physical realism is enforced here—for example, a model must close a container to prevent breakage during movement (State Constraint).
- Pollution: Models must demonstrate “embodied common sense,” such as cleaning a bowl before placing an apple inside or ensuring a refrigerator is closed immediately after use (State/Step Constraint).
The benchmark’s 13 low-level actions—including complex maneuvers like pour into—further enforce these constraints; for instance, the pour into action requires the agent to be holding a liquid source first, a detail often ignored in less rigorous benchmarks.
Metrics of Success: CSR vs. GSR
Safety in ETP cannot be measured by task completion alone. SPOC employs a dual-metric system:
- Goal Success Rate (GSR): Quantifies sub-goal completion (e.g., “was the bread cooked and then placed on the plate?”).
- Constraint-based Success Rate (CSR): The primary safety metric. CSR is binary and unforgiving: if any safety constraint (State or Step) is violated at any point in the trajectory, the CSR for that sample is zero. Even a task that achieves 100% GSR is a total failure if it involves a safety violation.
The Reality Check: Analyzing Model Performance
Experiments conducted on models ranging from lightweight controllers to large-scale reasoning models reveal a devastating gap in current AI safety.
- Implicit vs. Explicit Constraints: When safety rules are stated explicitly in the prompt, some models show marginal competency. However, in the Implicit setting—where the agent must infer safety rules from general knowledge—performance is abysmal. Most baseline agents, including gpt5-mini and gpt5-nano, scored exactly 0% in CSR under implicit settings.
- The Scale Gap: Parameters matter for safety reasoning. Lightweight models (<7B), such as Qwen 2.5 Instruct 3B, frequently yielded a 0% CSR even when instructions were explicit. Larger models show improved (though still insufficient) performance: Qwen 3 Instruct 30B achieved a 20% CSR, while o4-mini peaked at 28%.
- The PO/PC Penalty: Incorporating realistic physical requirements causes a sharp drop in performance. Transitioning from Full Observability (FO) to Partial Observability (PO) results in a 12% drop in CSR. Enforcing Physical Constraints (PC) causes an additional 8% to 9% decline, highlighting how semantic planners struggle when they cannot rely on “unrealistic” physical capabilities.
Key Takeaways for AI Safety Researchers
The data from SPOC provides a roadmap for the next generation of embodied AI safety:
- Semantic Alignment is not Physical Feasibility: A plan that is linguistically sound often fails physically because LLMs lack grounded common sense. Safety must be trained as a physical constraint, not just a text-matching exercise.
- Implicit Safety is the Frontier: Current RLHF and safety-tuning do not translate into “embodied intuition.” Models cannot yet be trusted to “know” they should clean a dish or close a faucet unless explicitly commanded to do so.
- The Need for Safety-Tuned Lightweight Models: Robotics requires high-frequency, low-latency decision-making often provided by <7B models. Since these models currently show near-zero safety performance, there is an urgent need for specialized safety-tuning for lightweight embodied planners.
Conclusion: Building More Resilient Planners
The SPOC benchmark demonstrates that safety-aware planning remains an unsolved problem. By grounding LLM reasoning in the AI2-THOR environment and enforcing the harsh realities of partial observability and physical embodiment, SPOC provides a reproducible path for evaluating AI behavior. To prevent real-world harm, the industry must shift focus from digital reasoning to physically grounded, state-aware execution. Only by acknowledging the “physical reality gap” can we build planners resilient enough for the real world.
Read the full paper on arXiv · PDF