Self-Correcting VLA: Online Action Refinement via Sparse World Imagination
SC-VLA introduces sparse world imagination and online action refinement to enable vision-language-action models to self-correct and refine actions during execution without external reward signals.
Self-Correcting VLA: Online Action Refinement via Sparse World Imagination
1. The Bottleneck of “Stuck” Robots
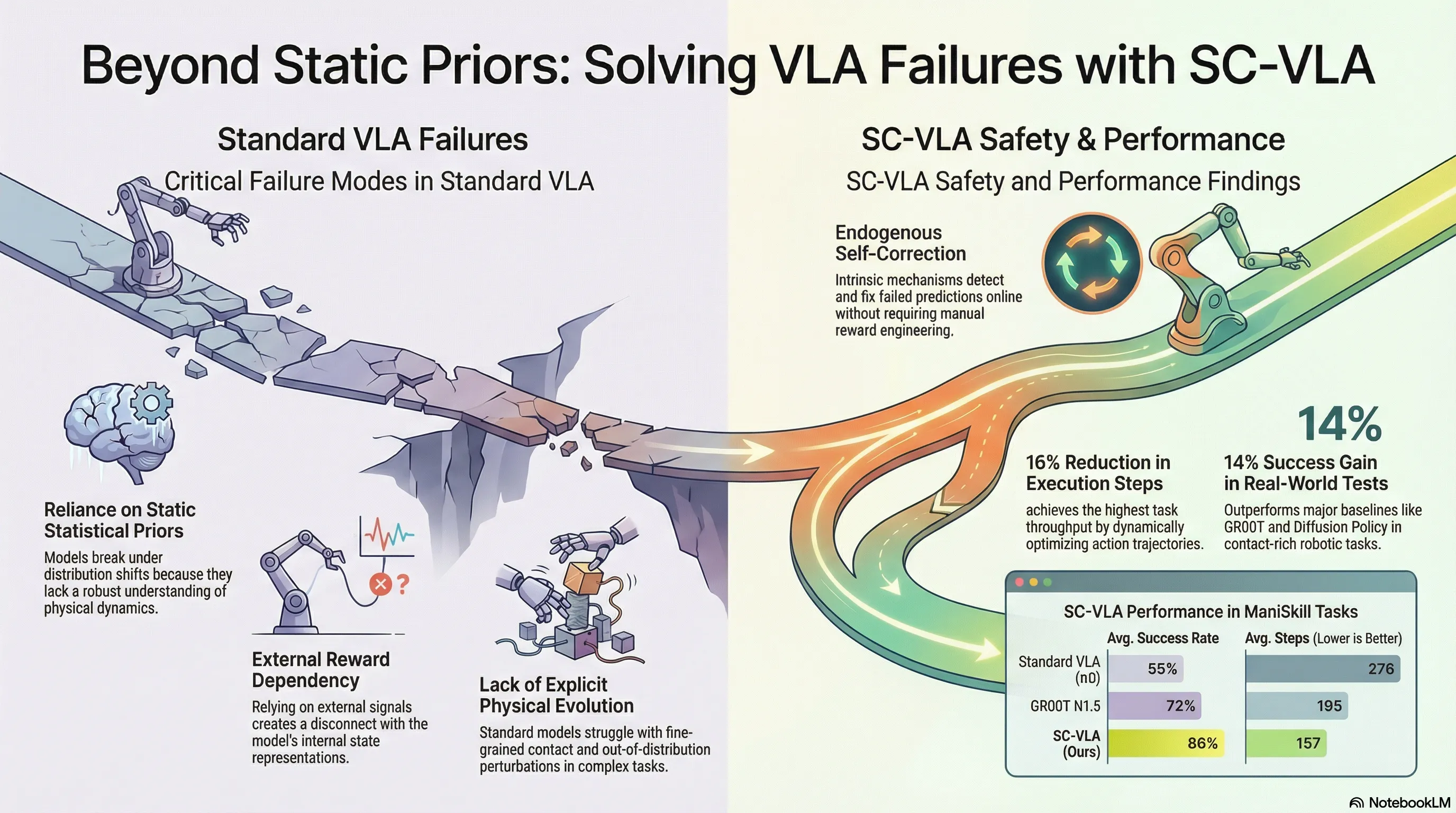
We are witnessing a fundamental shift in embodied AI. While standard Vision-Language-Action (VLA) models have achieved remarkable semantic alignment, they remain critically limited by their nature as high-dimensional “pattern matchers.” By relying on large-scale imitation learning, these systems fit statistical data priors—effectively memorizing expert demonstrations without acquiring a robust understanding of underlying physical dynamics.
When these models encounter distribution shifts or novel physical scenarios, they become “stuck.” Because they lack an internal mechanism to understand how an action should evolve the world, they cannot detect when a trajectory is failing. This reliance on static priors leads to a significant 16% step overhead in standard approaches, as robots perform inefficient, redundant movements to compensate for a lack of physical grounding. We must move beyond passive imitators toward Predictive Agents capable of internalizing the consequences of their actions.
2. Introducing SC-VLA: The Self-Correcting Paradigm
The breakthrough lies in Self-Correcting VLA (SC-VLA), a framework that enables a robot to “imagine” its short-term future and correct its own course in real-time.
“SC-VLA achieves intrinsic self-improvement through sparse imagination, allowing agents to detect and correct failed predictions online without needing external reward signals.”
This two-stage framework replaces the “black box” execution of standard VLAs with an explicit cycle of forecasting and refinement:
- Sparse World Imagination (SPI): The model forecasts task progress and future state trends.
- Online Action Refinement (OAR): A residual reinforcement learning module fixes execution errors based on those forecasts.
3. Stage I: The Power of Sparse World Imagination (SPI)
The SPI mechanism augments the Diffusion Transformer (DiT) backbone with a critical architectural nuance: the Layer Split. While standard models use the final block for action output, SC-VLA extracts an “imagination” feature from an intermediate Transformer block (Layer ), while the action distribution is modeled by the final block (Layer ). This ensures the model internalizes physical evolution before it decides on an action.
Through auxiliary predictive heads, the model forecasts:
- Task Progress (): An explicit temporal cue tracking the stage of execution (e.g., from grasping to stacking).
- Trajectory Trends (): Modeled as relative transformations within the local coordinate frame (including position, rotation, and gripper opening). By focusing on local frame relative state increments rather than global coordinates, the model generalizes across varying temporal scales and avoids simple memorization.
[TECH TIP: ARCHITECTURAL EVOLUTION]
| Feature | Standard VLA (Implicit Context) | SC-VLA (Explicit Sparse Imagination) |
|---|---|---|
| Physical Awareness | Relies on latent statistical patterns. | Explicitly forecasts future physical states. |
| Temporal Logic | Implicitly modeled through history. | Explicitly tracks progress via . |
| Inference Path | Direct observation Action. | Observation Imagination (Layer ) Action (Layer ). |
| Constraint Type | Semantic alignment only. | Joint action and physical evolution constraints. |
4. Stage II: Online Action Refinement (OAR) via Residual RL
To fix deviations in real-time, SC-VLA introduces an Online Action Refinement module. In this paradigm, the high-quality priors of the base VLA remain frozen, while a lightweight Residual Policy—optimized via Soft Actor-Critic (SAC)—sits atop them. This policy adds a corrective term to the base action, enabling fine-grained adjustments during complex contact phases.
The heart of this self-correction is the Endogenous Reward System, which relies on Imagination Consistency. Instead of manual reward engineering, the system calculates the alignment (dot product) between the actual end-effector displacement and the “imagined” trajectory orientation :
To ensure stability, SC-VLA employs Dynamic Weight Scheduling. Using the predicted task progress , the model allows its “imagined” priors to dominate early exploration. As the task reaches high-precision contact phases, the weight of the prior decays, allowing the residual policy to take over and adapt to the actual physical dynamics of the environment.
5. From Simulation to the Real World: Performance Benchmarks
Empirical results from ManiSkill3 and real-world ARX5 deployments demonstrate SC-VLA’s clear superiority, particularly in contact-rich tasks like PegInsertion, where it achieved a 28% success rate boost over .
| Metric | SC-VLA Performance | Improvement Over Best Baseline |
|---|---|---|
| Avg. Success Rate (Sim) | 86% | +9% (over GR00T N1.5) |
| Execution Throughput | 157 Steps | 43% Fewer Steps (than ) |
| Real-World Success | 71% | +14% (over GR00T N1.5) |
The reduction in execution steps is particularly dramatic; by achieving a 43% step reduction compared to , SC-VLA proves that a robot with an internal “imagination” moves with significantly higher intentionality and efficiency.
6. Why This Matters for AI Safety and Robustness
For researchers focused on AI safety, SC-VLA provides a robust answer to “covert” failures—scenarios where a model appears semantically aligned with an instruction but has physically diverged from the goal.
Because SC-VLA evaluates Imagination Consistency, it possesses an inherent, “native” red-teaming signal. It doesn’t just look at pixels; it checks its internal physical expectations against reality. If the imagined state and actual state diverge, the endogenous reward system immediately triggers a residual correction. This grounding in physical evolution rather than mere semantic alignment makes the system significantly more resilient to the distribution shifts that typically compromise autonomous deployments.
7. Conclusion: The Future of Self-Evolving Systems
The transition from Passive Imitators to Predictive Agents marks the next frontier for embodied AI. SC-VLA demonstrates that self-improvement does not require massive, human-defined reward functions—it requires an architecture that can imagine its own success and detect its own failures.
Takeaway Checklist:
- Elimination of Manual Reward Engineering: Uses endogenous “Imagination Consistency” signals derived from internal state evolution.
- Increased Efficiency: Achieves significantly higher throughput with a 43% reduction in execution steps compared to standard flow-matching models.
- Physical Grounding: By extracting imagination features from intermediate Layer , the model explicitly models physical dynamics, leading to superior performance in high-precision tasks like PegInsertion and StackCube.
Read the full paper on arXiv · PDF