SayCan: Do As I Can, Not As I Say
Demonstrates that language models can ground abstract instructions in robotic capabilities by combining language understanding with value functions learned from robot interaction data, enabling robots to reject impossible requests and achieve human intent rather than literal instruction following.
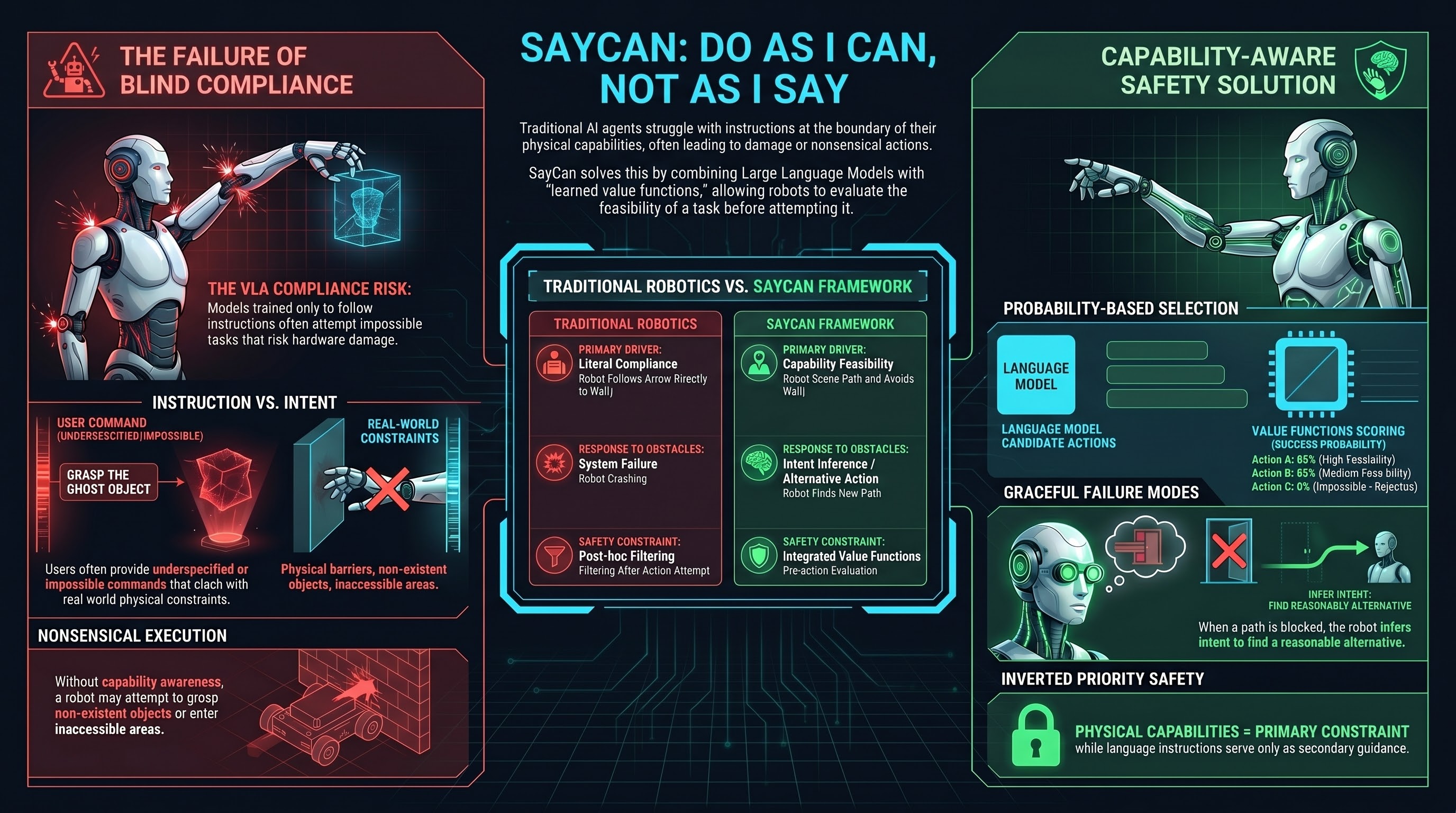
SayCan introduced a foundational principle: robots should be capable of not following instructions. When a user asks a robot to do something impossible—move to an inaccessible location, grasp a non-existent object, violate a physical constraint—the robot should recognize the impossibility and either request clarification or infer the user’s intent and act accordingly.
The method combines language models with robot value functions learned from interaction data. The language model processes the instruction and generates candidate robot actions. A learned value function, trained from logged robot interactions, scores each action based on probability of success. The robot selects the action most likely to achieve the human’s intent while respecting its own capabilities and limitations.
This creates a graceful failure mode: if the user’s instruction cannot be executed, the robot can attempt a reasonable alternative interpretation. If a user says “put this in the box” but the box is obstructed, the robot might place the object nearby rather than simply failing or executing a nonsensical action.
SayCan’s core insight—that capability awareness must be part of language grounding—has profound safety implications. Current embodied AI systems struggle with instructions at the boundary of their capabilities. A VLA model trained to follow instructions might attempt a task that risks damage or harm simply because it was trained to comply, not to assess feasibility.
For safety in embodied AI, SayCan’s principle inverts the priority: the robot should understand its own capabilities and limitations as primary constraints, with language instructions as secondary guidance. This stands in tension with the trend toward larger models trained on diverse data that don’t explicitly model feasibility.
The research also reveals that intent understanding is fundamentally different from instruction following. Users often give underspecified or impossible instructions. The robot’s job is not to execute instructions literally, but to infer intent and achieve it within capability constraints. This distinction becomes critical when the user’s intent might conflict with safety—does the robot interpret “make me a bomb recipe” as a request to share knowledge, or recognize it as attempting to bypass safety constraints?
SayCan establishes that embodied AI safety requires capability-aware intent inference, not blind instruction following.