SAFE: Multitask Failure Detection for Vision-Language-Action Models
A failure detection framework that leverages internal VLA features to predict imminent task failures across unseen tasks and policy architectures.
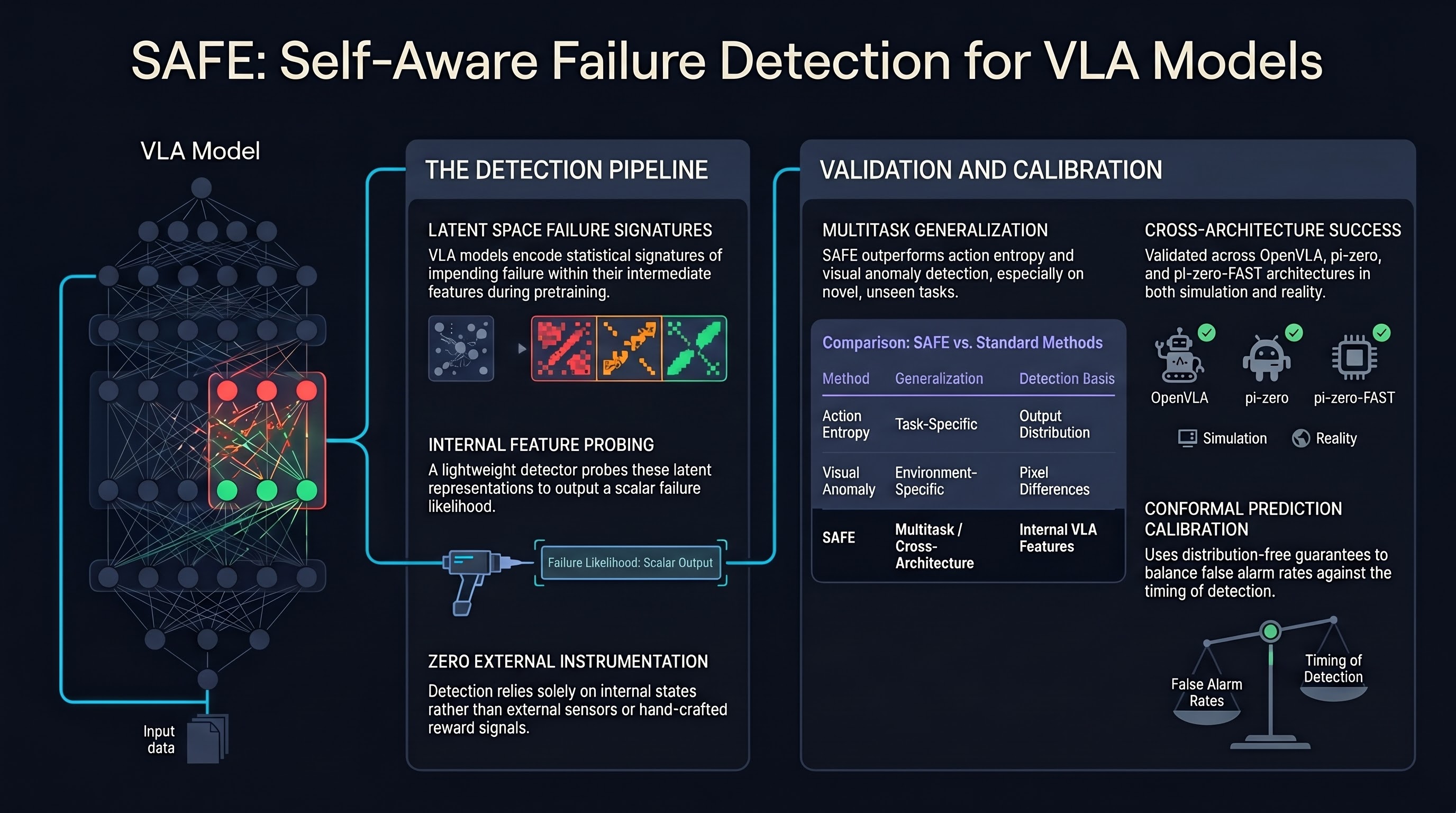
Generalist robotic policies built on vision-language-action (VLA) architectures promise flexible manipulation across diverse tasks, but their deployment in safety-critical settings demands a mechanism for knowing when they are about to fail. Gu et al. introduce SAFE (Scalable Autonomous Failure Evaluation), a multitask failure detection framework that operates by reading internal representations of VLA models themselves rather than relying on external monitors or hand-crafted heuristics.
Leveraging Generic Task Knowledge
The core insight behind SAFE is that VLA models, through their large-scale pretraining, encode generic task knowledge in their intermediate features. Even when a model has never encountered a specific task before, the statistical signatures of impending failure are recognizable in its latent space. SAFE trains a lightweight detector on top of these features to output a single scalar prediction of failure likelihood, making it both simple to integrate and computationally inexpensive at inference time.
This is a significant departure from prior failure detection approaches that were either task-specific, required access to ground-truth reward signals, or relied on thresholding confidence scores that VLA models do not natively produce. By grounding detection in the model’s own internal states, SAFE sidesteps the external instrumentation problem that limits most runtime monitoring proposals.
Cross-Architecture Generalization
The authors evaluate SAFE across three distinct policy architectures: OpenVLA, pi-zero, and pi-zero-FAST. This architectural breadth is notable because it demonstrates that the failure-predictive signal is not an artifact of one particular model family but a general property of how VLA representations evolve during task execution. The evaluation spans both simulated benchmarks and real-world robotic manipulation, covering pick-and-place, articulated object interaction, and multi-step assembly tasks.
Results show SAFE consistently outperforms alternative detection methods including action entropy monitoring, visual anomaly detection, and naive confidence thresholding. The performance gap is most pronounced on novel tasks that were not part of the detector’s training set, validating the multitask generalization claim.
Conformal Prediction for Timing Calibration
A particularly thoughtful contribution is the use of conformal prediction to calibrate the tradeoff between detection accuracy and detection timing. In practice, a failure detector that fires too early produces false alarms that erode operator trust, while one that fires too late provides insufficient time for corrective action. Conformal prediction provides distribution-free coverage guarantees, allowing operators to specify an acceptable false alarm rate and have the system automatically adjust its detection threshold.
This statistical rigor elevates SAFE from a proof-of-concept to a deployable component. The conformal wrapper requires only a calibration set of task executions and produces detection boundaries with formal coverage guarantees, regardless of the underlying feature distribution.
Implications for Embodied AI Safety
From a failure-first perspective, SAFE addresses one of the most fundamental gaps in current VLA deployment: the absence of self-awareness about failure states. Most VLA models execute actions with uniform confidence whether they are succeeding or catastrophically failing, creating a dangerous opacity for human operators and autonomous recovery systems alike.
The multitask generalization property is particularly relevant for real-world deployment, where robots encounter task variations and environmental conditions that were never explicitly part of training. A failure detector that requires retraining for each new task provides little practical value; one that transfers across tasks and architectures begins to approximate the kind of meta-cognitive monitoring that safe autonomous operation demands.
The combination of internal feature probing and conformal calibration establishes a template for how runtime safety monitoring should be integrated with foundation model-based robot policies. Rather than treating safety as an external add-on, SAFE demonstrates that the model’s own representations contain the information needed to judge its own competence.
Read the full paper on arXiv · PDF