RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Demonstrates that vision-language models trained on web text and images can directly control robots by treating robotic control as a language modeling problem, achieving generalization to new tasks without task-specific training.
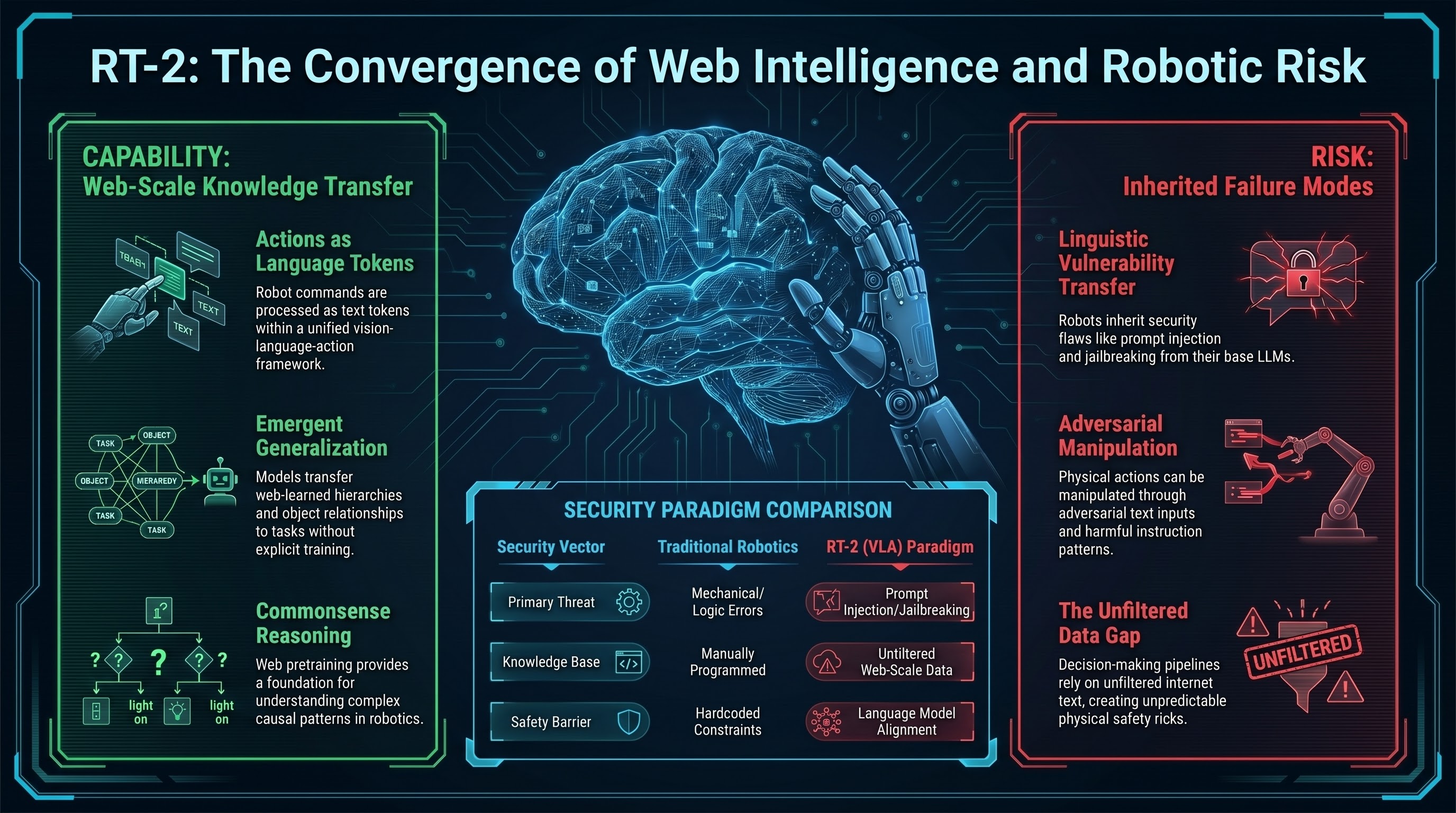
RT-2 (Robotic Transformer 2) introduced a pivotal insight: instead of training separate models for vision understanding and robotic control, a single vision-language model pretrained on web data can be finetuned to directly output robot actions. The robot becomes a client of a language model trained on the entire internet.
The method works by treating robot actions as tokens in a language modeling framework. An image is processed through a vision encoder, the model predicts the next “action token” (e.g., “move right”, “grasp object”), and the action is executed. This formulation allows the model to leverage billions of parameters worth of commonsense knowledge about the world learned from web training.
Remarkably, RT-2 generalizes to tasks it was never explicitly trained on. A model trained on grasping and pushing can transfer knowledge to tasks like arrangement and stacking without additional training. The web pretraining acts as a foundation—the model has learned hierarchies of goals, object relationships, and causal patterns that transfer to new robotic tasks.
But this capability comes with hidden risks. By grounding robotic control in a language model with web-scale knowledge, RT-2 also inherits vulnerabilities from language models. A robot controlled by RT-2 could potentially be manipulated through adversarial text inputs or harmful instruction-following patterns learned from web data.
RT-2 marks the birth of embodied AI as a language modeling problem—a shift with profound safety implications. If robots are controlled by the same models that power chatbots, and those models can be jailbroken through prompt injection, then embodied safety becomes inseparable from language model safety.
RT-2’s design forced the field to confront a central question: what does safety mean when a robot’s decision-making pipeline includes a layer trained on unfiltered internet text? This question continues to shape embodied AI research.