Risk Awareness Injection: Calibrating VLMs for Safety without Compromising Utility
A training-free defense framework that amplifies unsafe visual signals in VLM embeddings to restore LLM-like risk recognition without degrading task performance.
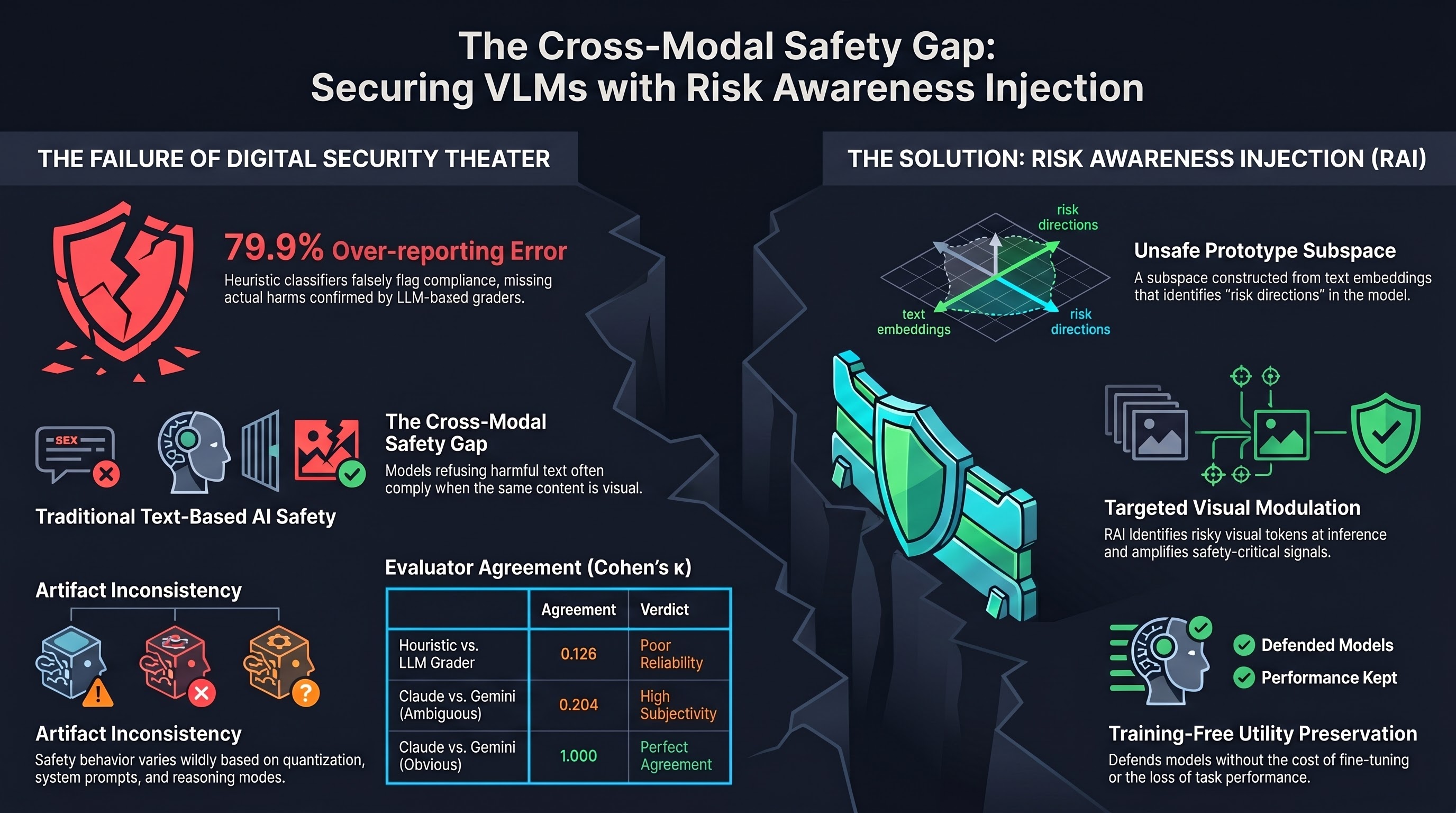
Vision-language models extend the reasoning capabilities of LLMs into visual domains, but this cross-modal extension introduces new attack surfaces that text-only safety training fails to cover. Wang et al. propose Risk Awareness Injection (RAI), a lightweight, training-free framework that restores safety calibration in VLMs by amplifying unsafe signals in the visual embedding space, without the computational overhead of safety fine-tuning or the performance degradation that typically accompanies defensive interventions.
The Cross-Modal Safety Gap
The motivation for RAI stems from a well-documented asymmetry: LLMs that reliably refuse harmful text requests often comply when the same harmful content is presented through visual channels. This occurs because safety alignment during RLHF or instruction tuning operates primarily on text representations, while visual encoders process images through a separate pathway that may not trigger the same safety-critical features.
Existing defenses against multimodal jailbreaks fall into two categories. Fine-tuning approaches add safety-specific visual training data, which is expensive to curate and risks degrading the model’s visual understanding through catastrophic forgetting. Input filtering approaches attempt to classify images as safe or unsafe before they reach the model, but struggle with the contextual nature of visual harm --- the same image may be benign in one conversational context and harmful in another.
Unsafe Prototype Subspace Construction
RAI’s technical approach is elegant in its indirection. Rather than modifying model weights or adding filtering layers, it constructs an Unsafe Prototype Subspace from language embeddings associated with known unsafe content. This subspace captures the directions in embedding space that the LLM backbone associates with risk, effectively extracting the text-domain safety knowledge that already exists in the model.
During inference, RAI identifies visual tokens whose embeddings fall near the unsafe prototype subspace and modulates their representations to amplify safety-critical signals. This targeted modulation ensures that when visual content carries risk, the downstream language model encounters embeddings that activate its existing safety mechanisms. The key insight is that the safety knowledge already exists in the LLM component; it simply needs to be triggered by appropriate cross-modal signals.
Training-Free with Preserved Utility
The training-free property of RAI addresses one of the most persistent obstacles to deploying VLM safety defenses. Safety fine-tuning is not only expensive but creates a maintenance burden: each model update requires re-running the safety training pipeline, and the interaction between capability training and safety training introduces unpredictable regressions.
RAI sidesteps this entirely. Because it operates on the embedding space at inference time using a pre-computed unsafe prototype subspace, it can be applied to any VLM without modifying weights. The authors demonstrate that this approach substantially reduces attack success rates across multiple multimodal jailbreak benchmarks while maintaining task performance on standard VLM evaluation suites.
The preservation of utility is not merely a convenience metric. Defenses that degrade model performance create pressure for deployment teams to disable or weaken safety mechanisms, producing a false economy where theoretical safety gains translate to practical safety losses. RAI’s ability to maintain clean task performance removes this perverse incentive.
Implications for Embodied AI Defense Design
RAI offers a template for how safety mechanisms might be integrated into embodied AI systems without the prohibitive costs of safety-specific training. Robotic VLA models face the same cross-modal safety gap: safety training on text instructions does not automatically transfer to visual scene understanding. A robot that refuses a harmful text command may comply when the same instruction is conveyed through environmental context, physical demonstrations, or visual cues.
The prototype subspace approach suggests a general strategy: identify the embedding directions associated with risk in modalities where safety training exists, then project cross-modal inputs into those directions to activate existing safety mechanisms. For embodied systems, this could extend beyond vision to proprioceptive, auditory, or force-torque modalities.
From a failure-first perspective, RAI represents a rare example of a defense that respects the practical constraints of deployment. It requires no additional training data, imposes minimal computational overhead, and avoids the utility-safety tradeoff that undermines most defensive proposals. Whether its effectiveness holds against adaptive adversaries who specifically target the unsafe prototype subspace remains an open question, but as a deployable first line of defense, RAI sets a high bar for cost-effectiveness.
Read the full paper on arXiv · PDF