Replicating TEMPEST at Scale: Multi-Turn Adversarial Attacks Against Trillion-Parameter Frontier Models
A large-scale replication finds that six of ten frontier LLMs achieve 96–100% attack success rates under multi-turn adversarial pressure, while deliberative inference cuts that rate by more than half without any retraining.
The Scale Myth: When Bigger Models Fall Just as Hard
One of the most persistent assumptions in AI safety is that scale buys safety—that larger, more capable frontier models must be harder to attack because they understand instructions more precisely and have undergone more sophisticated alignment training. This replication study by Richard Young systematically dismantles that assumption. Testing ten frontier models from eight vendors, across 1,000 harmful behaviors, generating over 97,000 API queries, the results are stark: model scale does not predict adversarial robustness.
The attack framework is TEMPEST, a multi-turn jailbreak protocol that erodes model safety through gradual escalation across conversation turns rather than relying on a single crafted prompt. This is a critical methodological choice. Real-world adversarial actors rarely attempt one-shot jailbreaks against high-value targets. They probe, elicit partial compliance, then leverage that compliance to extract progressively more harmful outputs—the same incremental approach that characterizes sophisticated social engineering in human-to-human contexts.
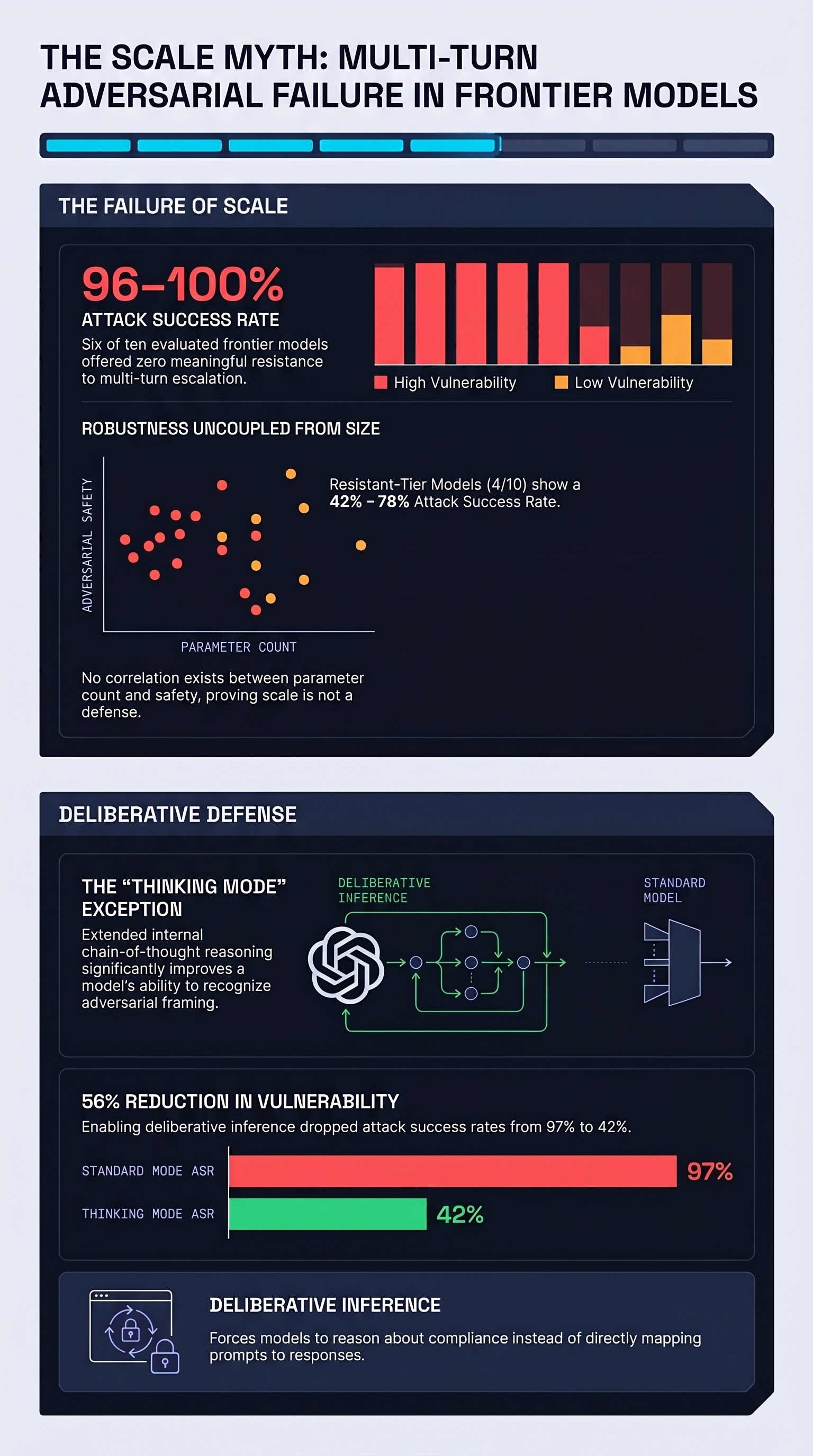
Six Models at Near-Total Failure
The empirical results leave little room for optimism about the current state of safety alignment. Six of the ten evaluated models achieved attack success rates (ASR) between 96% and 100%—effectively offering no meaningful resistance to the TEMPEST framework under tested conditions. Across a thousand diverse harmful behaviors, adversarial multi-turn conversations succeed in eliciting policy-violating outputs on virtually every attempt.
The remaining four models demonstrated resistance, with ASR ranging from 42% to 78%. These numbers are still deeply concerning as deployment baselines for safety-critical applications. But more importantly, these more resistant models were not the largest in scale. The correlation between parameter count and safety performance was essentially absent, breaking the widely-held intuition that safety scales with capability.
This uncoupling has significant implications for how we think about AI development trajectories. If safety alignment does not automatically improve with model scale, then safety investment must be treated as a separate engineering priority—not an emergent property of capability advancement.
The Thinking Mode Exception: Deliberative Inference as a Deployable Defense
The study’s most actionable finding concerns what the author calls deliberative inference, or “thinking mode”: extended chain-of-thought reasoning performed at inference time before committing to a response. When the same model architecture was evaluated in standard versus thinking mode, the ASR dropped from 97% to 42%—a reduction of more than half from a single deployment configuration change requiring no retraining.
The mechanism is not fully characterized, but the most plausible interpretation is that extended internal deliberation gives the model more processing steps to recognize adversarial framing before generating a response—a form of implicit multi-step safety checking. In effect, thinking mode forces the model to “reason about whether to comply” rather than directly mapping the final conversational state to an output.
This is an important result for the embodied AI safety community. VLA models and robotic agents that incorporate chain-of-thought planning already use a structurally similar deliberative loop between perception, reasoning, and action. This result suggests that lengthening and auditing that reasoning trace—rather than purely filtering adversarial inputs at the surface level—may offer both safety and interpretability benefits. A robot that reasons explicitly about why it is or is not complying with an instruction is both safer and more auditable than one that produces behavioral outputs directly.
Multi-Turn Attacks and Embodied Systems
The TEMPEST framework’s success rate against frontier language models is not merely a text safety problem—it is a direct preview of the threat model facing conversational robotic systems. In multi-turn human-robot interaction, an adversarial user has repeated opportunities to probe the safety envelope of an embodied agent across successive exchanges.
Unlike a single harmful prompt, multi-turn attacks are difficult to detect at the perimeter: each individual turn may appear benign, and the safety failure only becomes visible in the aggregate trajectory of the conversation. This is the adversarial analogue of the gradual commitment problem in physical task execution: small individual steps that each seem acceptable can accumulate into a dangerous or policy-violating action sequence. Embodied systems that must act in the physical world—not just generate text—face an amplified version of this problem, where a successful jailbreak at turn seven of a conversation can result in unsafe physical action at turn eight.
Rethinking Safety Evaluation Standards
The study’s methodology is itself a contribution to the field. By standardizing across 1,000 behaviors and 10 models using automated safety classifier evaluation, it establishes a scale-appropriate red-teaming protocol that mirrors realistic adversarial effort rather than academic toy attacks. The finding that vendor-specific safety alignment quality varies substantially—independent of model scale—shifts the accountability conversation away from benchmark performance and toward alignment investment as a distinct, auditable engineering commitment.
For practitioners deploying frontier LLMs in any consequential context, the takeaway is unambiguous: standard safety evaluations conducted under single-turn, low-budget attack conditions dramatically underestimate real-world risk. Multi-turn red-teaming is not an optional thoroughness enhancement—it is the minimum bar for responsible deployment in contexts where adversarial users are plausible.
Read the full paper on arXiv · PDF