RECAP: A Resource-Efficient Method for Adversarial Prompting in Large Language Models
RECAP retrieves semantically similar pre-trained adversarial prompts to attack new targets, achieving competitive jailbreak success rates at a fraction of the computational cost of optimization-based methods.
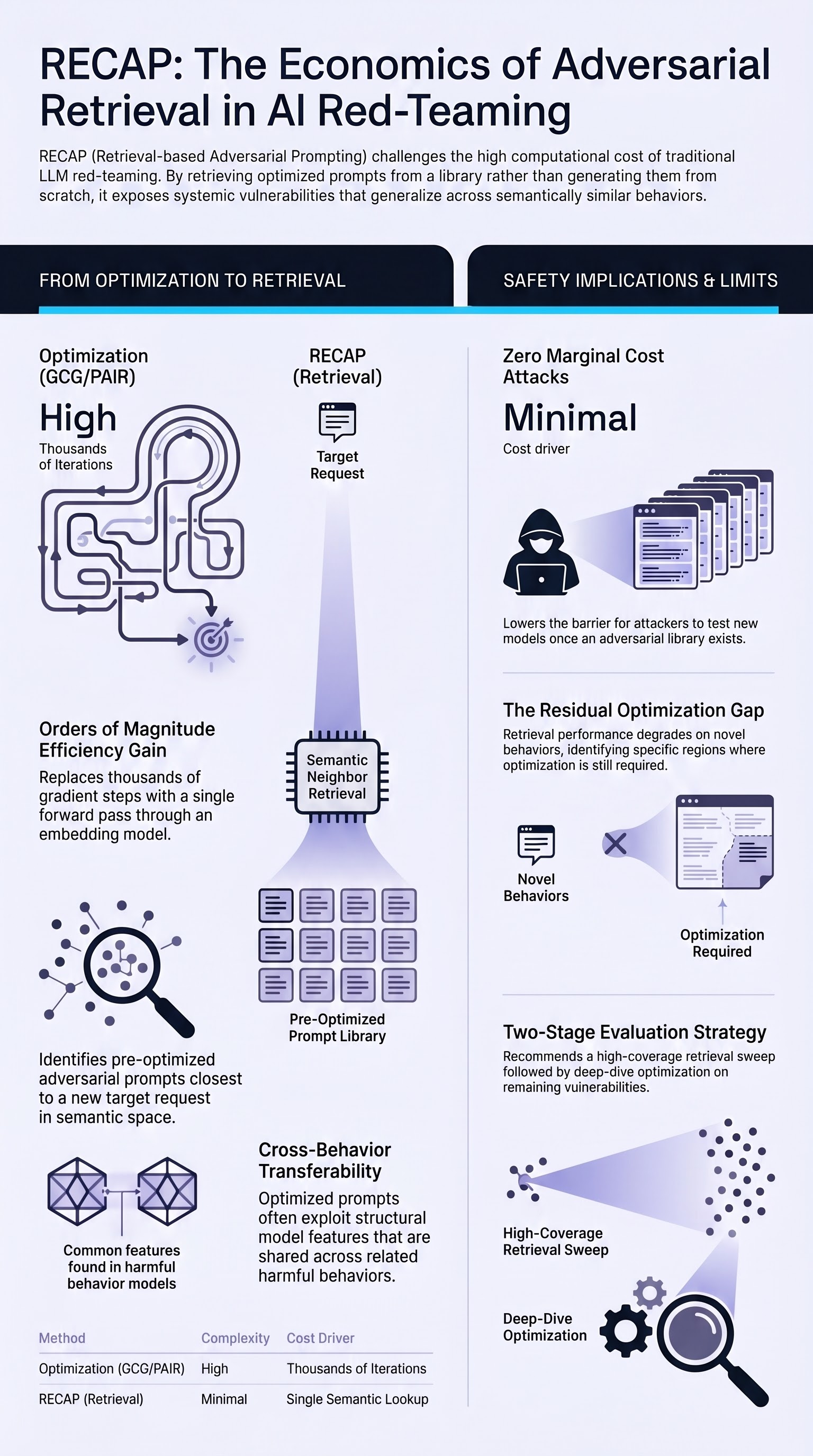
The prevailing assumption in LLM red-teaming research is that effective adversarial prompting requires substantial computation: gradient-based methods like GCG (Greedy Coordinate Gradient) iterate over thousands of token substitutions; evolutionary methods like PAIR run multi-turn attacker-judge loops; optimization-based approaches like PEZ and GBDA minimize differentiable loss functions over continuous token embeddings. This computational overhead creates a significant barrier — rigorous red-teaming of production systems is expensive, and the expense tends to concentrate evaluation resources on a small number of high-profile models while leaving the broader ecosystem undertested.
RECAP (Retrieval-based Adversarial Prompting) challenges this assumption. Chugh’s approach asks a simple question: given a library of pre-trained adversarial prompts that have already been optimized, can we find a good attack for a new target request by retrieving the most semantically similar prompt from the library rather than optimizing from scratch? The answer, the paper demonstrates, is largely yes — with meaningful implications for both the efficiency of safety evaluation and the nature of adversarial generalization in LLMs.
The Retrieval Mechanism
RECAP’s architecture is straightforward. An offline phase assembles a library of adversarial prompts — drawn from prior work (GCG outputs, PAIR-generated prompts, AdvBench suffixes) or generated using any optimization method — and encodes each prompt-behavior pair using a semantic embedding model. At inference time, when a red-teamer wants to test a new target behavior, RECAP encodes the target request, performs nearest-neighbor retrieval over the library, and returns the top-k most semantically similar adversarial prompts for transfer testing.
The key insight is that adversarial prompts carry structure that generalizes across semantically related behaviors. A prompt optimized to elicit instructions for one type of harmful content tends to transfer, with minimal modification, to semantically adjacent behaviors. This is not surprising in retrospect — gradient-based optimizers find token sequences that exploit structural features of the model’s safety training, and those structural features are not behavior-specific. But RECAP operationalizes this intuition into a practical retrieval system that removes the per-target optimization cost entirely.
The paper evaluates RECAP against GCG, PEZ, and GBDA on standard jailbreak benchmarks. RECAP achieves attack success rates competitive with full optimization in a large fraction of evaluated behaviors, while running orders of magnitude faster — retrieval is a single forward pass through an embedding model, compared to thousands of gradient steps for optimization-based baselines.
What This Means for the Safety Evaluation Landscape
The efficiency argument has a double edge that the safety community should internalize carefully.
On the defensive side, RECAP dramatically lowers the cost of comprehensive red-teaming. A safety team that previously could afford to run GCG on a representative sample of high-risk behaviors can now use RECAP to sweep a much larger behavior space in the same time budget, identifying coverage gaps and long-tail failure modes that optimization-based evaluations would miss. This is a genuine improvement: the attack surface of a production LLM is not the 50 behaviors in AdvBench, and evaluation methodologies that treat it as such systematically underestimate deployment risk.
On the threat side, RECAP illustrates that the computational barrier to adversarial prompting is lower than the field has assumed. If a pre-trained prompt library can be constructed once and then applied cheaply to new targets, the marginal cost of attacking a new model or behavior approaches zero for anyone with access to the library. This shifts the economics of adversarial prompting in ways that current safety frameworks have not fully absorbed. Models that are “sufficiently robust” against expensive optimization-based attacks may not be robust against retrieval-based transfer, because the retrieved prompts can be drawn from a library optimized against a different model architecture and then transferred via semantic similarity.
Connections to Adversarial Transferability
RECAP’s implicit claim — that adversarial prompts transfer across semantically similar behaviors — connects to one of the most important empirical findings in the adversarial ML literature: that adversarial examples transfer across models. The text analogue of cross-model transferability is cross-behavior transferability: prompts that break one behavior’s safety guardrail tend to break structurally similar behaviors, suggesting that safety training creates correlated vulnerabilities rather than independent defenses for each behavior category.
This has direct implications for how safety alignment should be evaluated and benchmarked. If adversarial prompts cluster in semantic space and transfer within clusters, then a benchmark that samples behaviors from the same semantic cluster is implicitly testing the same vulnerability multiple times while missing entire adjacent regions of the attack surface. The diversity of a red-teaming evaluation is at least as important as its depth, and RECAP provides a practical tool for assessing and improving that diversity.
Limitations and the Residual Optimization Gap
RECAP does not eliminate the need for optimization-based methods. The paper’s results show that retrieval achieves competitive performance on behaviors with good coverage in the existing library — that is, behaviors semantically close to prompts that have already been optimized. For novel behaviors at the periphery of the training distribution, where no close neighbor exists, retrieval degrades and optimization retains its advantage. This residual gap is informative: it identifies the boundary between well-covered and poorly-covered regions of the behavior space, which is itself a useful signal for prioritizing where optimization-based red-teaming resources should be directed.
The practical recommendation that emerges from RECAP is a two-stage red-teaming pipeline: retrieval-based sweep for broad coverage at low cost, followed by optimization-based deep-dive on behaviors where retrieval fails or where coverage is sparse. This mirrors mature practices in software security testing — automated fuzzing for broad coverage, followed by targeted exploit development where the fuzzer flags potential vulnerabilities.
For the embodied AI safety community, the analogy extends naturally. Adversarial patch libraries for VLA models — if assembled systematically — could support the same retrieval-based transfer evaluation that RECAP demonstrates for text. The computational overhead of generating VLA adversarial patches from scratch is substantial; a retrieval system that amortizes that cost across evaluation targets would meaningfully expand the tractable scope of embodied AI red-teaming.
Read the full paper on arXiv · PDF