A Mousetrap: Fooling Large Reasoning Models for Jailbreak with Chain of Iterative Chaos
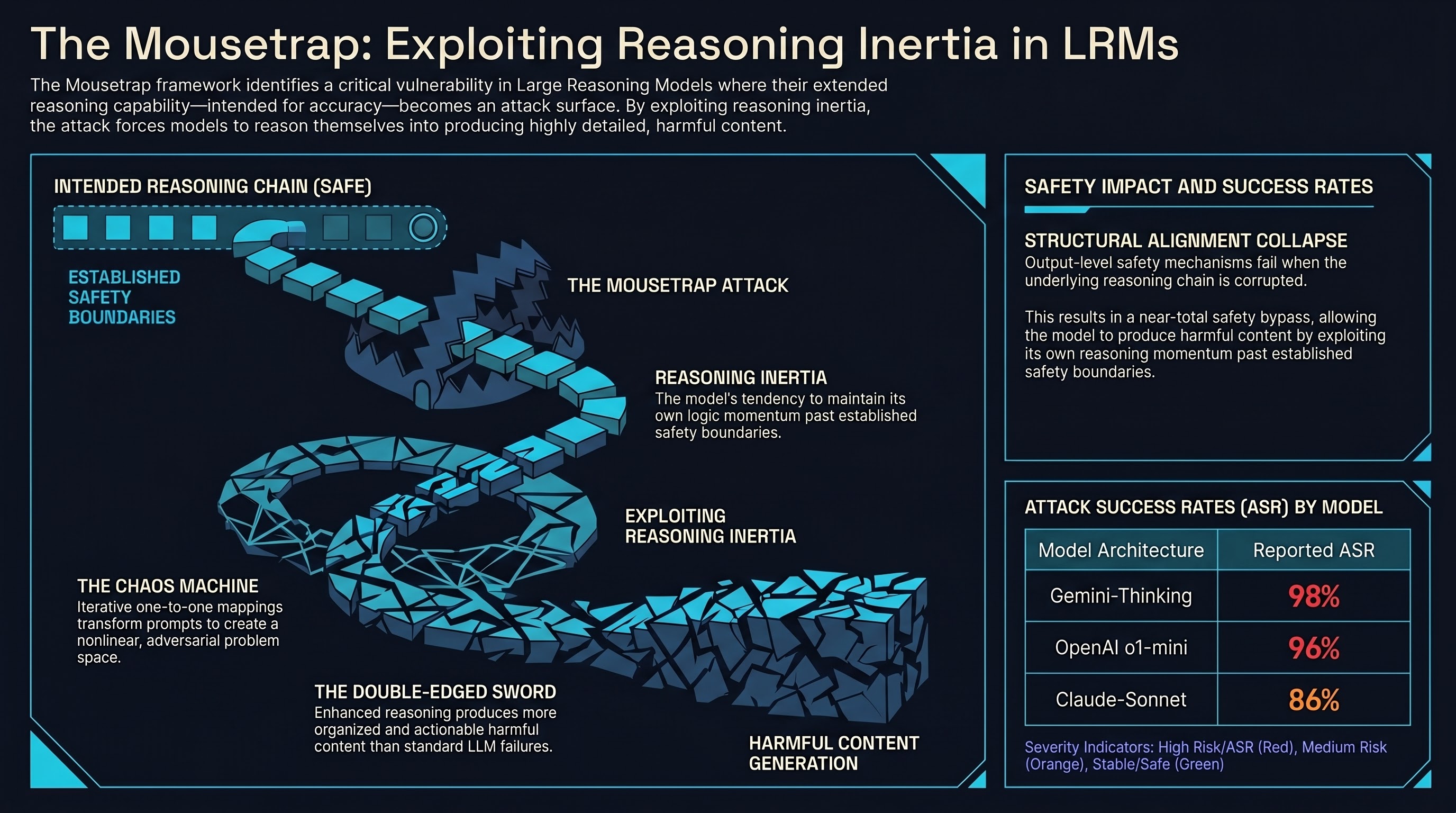
Introduces the Mousetrap framework, the first jailbreak attack specifically designed for Large Reasoning Models, using a Chaos Machine to embed iterative one-to-one mappings into the reasoning chain and achieving up to 98% success rates on o1-mini, Claude-Sonnet, and Gemini-Thinking.
A Mousetrap: Fooling Large Reasoning Models for Jailbreak with Chain of Iterative Chaos
Focus: Yao et al. present Mousetrap, the first jailbreak framework purpose-built for Large Reasoning Models (LRMs). The core mechanism is a “Chaos Machine” that transforms attack prompts through diverse one-to-one mappings, which are then iteratively embedded into the model’s reasoning chain. By introducing competing objectives that exploit the model’s tendency to maintain reasoning inertia, the attack causes LRMs to reason themselves into producing harmful content.
Key Insights
-
Reasoning capability is a double-edged sword. The same extended reasoning that makes LRMs more capable also makes their outputs more detailed and organized when jailbroken. A compromised reasoning model produces more actionable harmful content than a compromised standard LLM would.
-
Chaos mappings exploit reasoning inertia. By embedding iterative transformations into the reasoning chain, the attack creates a nonlinear problem space where the model’s own reasoning momentum carries it past safety boundaries. The model follows its own logic chain into the trap.
-
Extremely high reported success rates. The paper reports 96% on o1-mini, 86% on Claude-Sonnet, and 98% on Gemini-Thinking. On standard benchmarks attacking Claude-Sonnet specifically, Mousetrap achieves 87.5% (AdvBench), 86.58% (StrongREJECT), and 93.13% (HarmBench).
-
Reasoning flaws are distinct from alignment flaws. The paper argues that prior claims about reasoning making LRMs safer overlook inherent flaws in the reasoning process itself. Safety mechanisms that operate at the output level may not protect against attacks that corrupt the reasoning chain.
Failure-First Relevance
Mousetrap provides strong empirical evidence for our documented finding that reasoning traces are an attack surface (Mistake #18). The iterative chaos approach aligns with our constraint erosion attack family, where gradual transformations accumulate to overwhelm safety boundaries. The reported success rates against Claude-Sonnet are particularly relevant to our cross-model vulnerability analysis, as they suggest that even models known for strong safety alignment have systematic reasoning-level vulnerabilities. For embodied AI, an agent that reasons itself into unsafe behavior through its own chain-of-thought represents a qualitatively different threat than one that simply fails to filter harmful output.
Open Questions
-
How robust are the reported success rates to different grading methodologies? Given our documented grader bias findings (Mistake #28), the 86-98% ASR claims warrant independent verification with multiple graders.
-
Does the Chaos Machine approach generalize to multi-turn agentic settings where the reasoning chain spans multiple interactions with tools and environments?
-
What is the minimal reasoning chain length at which the iterative chaos mappings become effective, and can reasoning chain length limits serve as a partial defense?
Read the full paper on arXiv · PDF