LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies
LiLo-VLA proposes a modular framework that decouples reaching and interaction for long-horizon robotic manipulation, achieving 69% success on simulation benchmarks and 85% on real-world tasks through object-centric VLA policies and dynamic replanning.
LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies
1. The “Fragility” Problem in Modern Robotics
Long-horizon manipulation—tasks requiring multiple kinematic structure changes such as picking, placing, and pouring over extended sequences—represents the frontier of general-purpose robotics. While modern Vision-Language-Action (VLA) models excel at single-stage atomic skills, they suffer from combinatorial complexity when sequencing behaviors in unstructured environments.
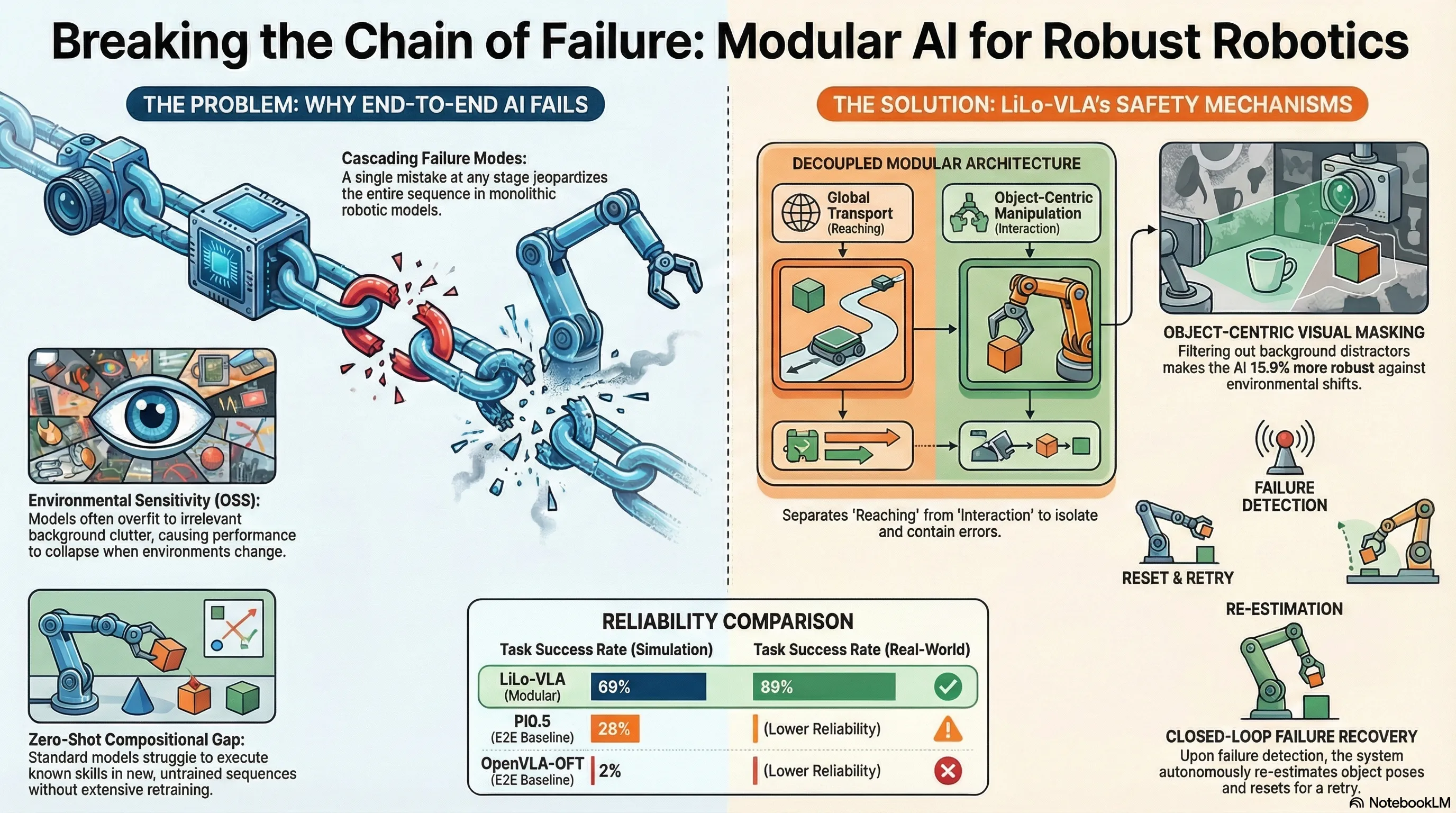
In standard end-to-end VLA paradigms, robots are plagued by cascading failures. Because these models often couple global transport with fine-grained interaction, a minor error in one stage propagates through the entire sequence. This fragility is exacerbated by a lack of compositional generalization; monolithic models struggle to recombine skills for novel task permutations without extensive, task-specific demonstrations.
Problem: End-to-end VLA models are sensitive to environmental shifts and suffer from cascading errors, making them data-inefficient and brittle for long-sequence tasks.
Solution: LiLo-VLA (Linked Local VLA). A modular framework that decouples global motion from local interaction, utilizing object-centric policies and dynamic replanning to achieve robust, zero-shot generalization.
2. The Architecture of Modularity: Reaching vs. Interaction
To mitigate cascading failures, LiLo-VLA decouples robotic execution into two distinct phases. By separating the “where” (geometry) from the “how” (manipulation), the framework ensures learning capacity is focused purely on task dynamics.
| Module Name | Primary Function | Mechanism Used |
|---|---|---|
| Reaching Module | Global transport; navigating the end-effector to the target vicinity. | Classical motion planning (MPLib) for collision-free trajectories. |
| Interaction Module | Fine-grained, contact-rich manipulation and atomic skill execution. | Object-centric VLA policy using egocentric vision and masking. |
Bridging the Gap: Approach Pose and SE(3) Perturbation
The system links these modules via a deterministic Approach Pose (), defined relative to the target object: . This target enforces a fixed face-down orientation and specific vertical clearance () to ensure a consistent handover to the Interaction Module.
To ensure the VLA policy can handle real-world inaccuracies in perception or planning, we utilize an Initial State Perturbation strategy during training. Rather than initializing from a perfect pose, training trajectories are randomized: , where and defines a zero-mean perturbation in . This injects noise in both translation and rotation, teaching the policy to compensate for local pose errors during deployment.
3. The Object-Centric Secret Sauce
A primary cause of failure in VLAs is Observation Space Shift (OSS), where irrelevant visual changes distract the model. LiLo-VLA prioritizes an “object-centric” inductive bias through three pillars:
- Wrist-Only Perspective: The system relies exclusively on egocentric views. Experiments on the BOSS-C1 benchmark confirm that wrist-only configurations are more robust to OSS (15.9% performance delta) than third-person views (29.8%), as the target object maintains a consistent perspective relative to the workspace.
- Visual Masking: To eliminate distractors, LiLo-VLA employs a heuristic strategy where non-target objects are covered with black rectangles based on their bounding boxes.
- Mask-Aware Augmentation: To prevent out-of-distribution (OOD) failures caused by these artificial masks, the model is trained with random erasing. By overlaying black rectangles onto background regions during training, the policy learns to focus strictly on foreground features (gripper and target object).
Furthermore, the Interaction Module transforms standard end-effector poses into a relative frame (), rendering the policy invariant to global workspace shifts.
4. Resilience in Action: The Closed-Loop Recovery Mechanism
LiLo-VLA’s modularity enables a hierarchical recovery mechanism. Following each skill execution, a geometric verification function () evaluates the spatial configuration of the target object. If the effect is not satisfied, the system triggers one of two logic paths derived from Algorithm 1:
- Scenario A (Pick Failure): For failures not involving object retention, the system triggers a local retry. It re-estimates the object’s 6D pose and uses the Reaching Module to reset the arm to the approach pose, re-conditioning the VLA on the latest state.
- Scenario B (Place/Transport Failure): If an object is dropped during a transport step, the system backtracks to the most recent “Pick” index. The robot re-acquires the lost object before re-attempting the subsequent sequence.
5. Stress-Testing the Limits: Simulation and Real-World Results
LiLo-VLA was evaluated on a 21-task benchmark, including LIBERO-Long++ (visual clutter) and Ultra-Long (temporal scalability at 9, 10, and 16 steps).
Performance Gap (Simulation):
- LiLo-VLA Average Success Rate: 69%
- Pi0.5 Success Rate: 28%
- OpenVLA-OFT Success Rate: 2%
While Pi0.5 achieved 83% on “Original” sequences, it collapsed to 0% on “Variant” sequences (permuted skill orders). This confirms that monolithic models overfit to demonstrated trajectories rather than grounding the language command. LiLo-VLA maintained 85% on these variants by isolating atomic skills.
Real-World Validation: Deployed on a Franka Emika Panda robot across tasks like “Cooking Preparation,” LiLo-VLA achieved an 85% average success rate. Notably, the framework used a Pi0.5 backbone in the real world despite using OpenVLA in simulation, empirically proving that the architecture is model-agnostic.
6. Conclusion and Strategic Takeaways
The data efficiency of LiLo-VLA is rooted in reducing the complexity of long-horizon tasks. An end-to-end policy must internalize all valid linearizations of a task—a combinatorial explosion of for objects. By decoupling into atomic units, LiLo-VLA’s data requirement scales linearly, , independent of total horizon length.
Key Takeaways for Practitioners:
- Modularity is a prerequisite: To reach 16-step horizons, robots must decouple transport from interaction to avoid trajectory memorization.
- Relative Coordinates + Masking: Transforming poses to and using egocentric masking are essential for surviving unstructured environments.
- Classical Planners for Geometry: Offloading collision-free transport to motion planners allows VLAs to focus exclusively on interaction dynamics.
Future work will address current limitations in the perception stack—specifically the detection of transparent or severely occluded objects—through active perception strategies that autonomously navigate to favorable viewpoints.
Read the full paper on arXiv · PDF