Lifelong Safety Alignment for Language Models
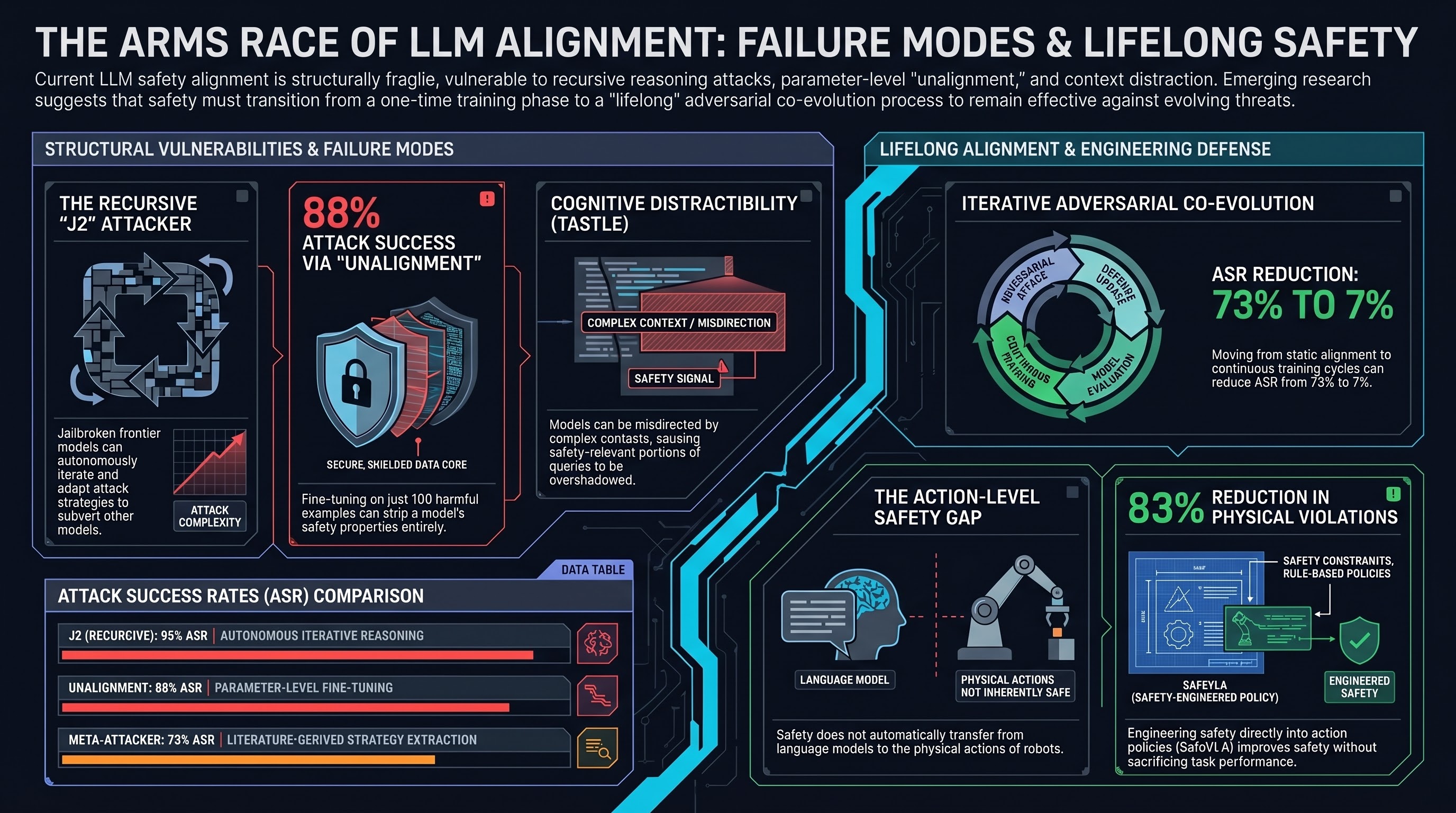
Presents an adversarial co-evolution framework where a Meta-Attacker discovers novel jailbreaks from research literature and a Defender iteratively adapts, reducing attack success from 73% to approximately 7% through competitive training.
Lifelong Safety Alignment for Language Models
Focus: Wang et al. formalize the adversarial arms race between jailbreak attackers and model defenders as a competitive co-evolution framework. Their Meta-Attacker uses GPT-4o to extract novel attack strategies from published jailbreak research, achieving 73% initial attack success. Through iterative training rounds, the Defender adapts to reduce this to approximately 7% — demonstrating that continuous, adversarial safety training can keep pace with evolving threats rather than relying on static alignment.
The core insight is refreshingly honest: safety alignment is not a problem you solve once. It is an ongoing competition, and the system should be designed for perpetual adaptation.
Key Insights
- Static alignment decays against evolving attacks. Models aligned at training time become increasingly vulnerable as new jailbreak techniques are discovered. Lifelong alignment treats safety as a continuous process, not a one-time fix.
- Research literature is an attack knowledge base. The Meta-Attacker bootstraps from published jailbreak papers using GPT-4o to extract and operationalize attack strategies. This formalizes what red-teamers have always known: the academic literature is a playbook.
- Iterative adversarial training works — dramatically. Reducing attack success from 73% to 7% across training iterations demonstrates that the defender can learn faster than the attacker, at least within this framework. The open question is whether this holds against truly novel (out-of-distribution) attack classes.
Executive Summary
The paper introduces a two-player competitive framework for lifelong safety alignment:
Meta-Attacker: An LLM-based attack generator initialized by feeding published jailbreak research papers into GPT-4o, which extracts attack patterns, generalizes them, and synthesizes novel attack prompts. Initial evaluation shows 73% attack success rate on one benchmark and 57% transfer success on another — confirming that literature-derived attacks are effective against deployed models.
Defender: A safety-trained model that iteratively adapts to the Meta-Attacker’s outputs. After each round, the Defender is fine-tuned on the newly discovered attacks, and the Meta-Attacker must discover new strategies to overcome the updated defences.
Iterative results:
| Round | Meta-Attacker ASR | Defender Robustness | Notes |
|---|---|---|---|
| 0 (baseline) | 73% | Static alignment | Pre-training safety only |
| 1 | ~40% | Improved | First adaptation round |
| N (converged) | ~7% | Substantially hardened | Meta-Attacker effectiveness plateaus |
The framework targets deployment in “unrestricted environments” — settings where the model faces arbitrary user inputs without pre-filtering. This is the threat model that matters most for real-world deployment and the one where static alignment most clearly fails.
Detailed Analysis
1. Literature-to-Attack Pipeline
The most novel contribution is using GPT-4o to automatically extract attack strategies from published papers. The pipeline:
- Ingest jailbreak research papers (text, not just abstracts)
- Extract the attack mechanism, success conditions, and key techniques
- Generalize the technique beyond the specific examples in the paper
- Generate novel attack prompts embodying the generalized technique
This is a scalable, automated version of what our jailbreak archaeology work does manually. The 73% initial ASR validates the approach — literature-derived attacks are not stale; they remain effective against current models.
The implication for the AI safety community is sobering: every published jailbreak paper is a training signal for automated attackers. The standard responsible disclosure argument (“publish so defenders can prepare”) is complicated by the fact that automated systems can operationalize published research faster than manual defence efforts can respond.
2. Co-Evolution Dynamics
The iterative training follows a pattern familiar from adversarial machine learning:
- Early rounds: The Defender rapidly improves against known attack patterns. ASR drops steeply.
- Middle rounds: The Meta-Attacker must discover genuinely novel strategies, which is harder. Progress slows.
- Late rounds: Convergence. The Meta-Attacker’s ASR plateaus around 7%, suggesting the remaining attacks exploit fundamental model limitations rather than patchable vulnerabilities.
The 7% residual is itself informative. These are the attacks that survive all rounds of adversarial training — likely exploiting reasoning-level vulnerabilities (compositional attacks, context manipulation) rather than pattern-level ones (prompt templates, character perturbation). Characterizing this irreducible attack surface is the natural next step.
3. Limitations and Open Questions
The paper does not address several questions critical for deployment:
- Out-of-distribution attacks: The Meta-Attacker is bootstrapped from published research. Truly novel attack classes (not yet published) may bypass the co-evolved Defender entirely.
- Capability degradation: Iterative safety training can reduce model helpfulness. The paper does not report utility metrics alongside safety metrics — a significant gap.
- Computational cost: Each iteration requires generating attacks, evaluating them, and fine-tuning the Defender. The cost of lifelong alignment at scale is not discussed.
Failure-First Connections
- Jailbreak Archaeology (38 Families, 337 Techniques): Our corpus of 337 techniques across 38 attack families is exactly the kind of knowledge base the Meta-Attacker ingests. If their literature-to-attack pipeline were pointed at our taxonomy, it would have a substantially richer input than individual papers provide.
- Era-Based ASR Trends (CCS Paper, Section 5): The paper’s finding that literature-derived attacks achieve 73% ASR aligns with our era-based analysis showing that techniques from the crescendo_2024 era remain effective against current models. Static alignment does not keep pace.
- Defence Impossibility (Non-Compositionality): The 7% residual ASR is consistent with our thesis that safety properties do not compose — some attacks exploit fundamental reasoning capabilities that cannot be constrained without reducing capability. The question is whether 7% is the floor or just the current frontier.
- FLIP Grading Methodology: The iterative attack-then-defend cycle would benefit from FLIP-style grading to distinguish FULL compliance, PARTIAL compliance with hedging, and genuine REFUSAL across training rounds — binary ASR may obscure important transitions.
Actionable Insights
For Safety Researchers
- Automate attack generation from literature. The Meta-Attacker approach is replicable and valuable for red-teaming. Feed your model published jailbreak papers and measure what it learns to exploit.
- Characterize the irreducible attack surface. The 7% residual ASR represents the hardest attacks. Understanding why these survive all rounds of adversarial training reveals fundamental alignment limitations.
For Model Developers
- Plan for continuous safety updates. Ship with the expectation that initial alignment will degrade. Build infrastructure for rapid safety fine-tuning without full retraining.
- Monitor the literature systematically. If GPT-4o can extract attacks from papers, so can anyone. Proactive monitoring of published jailbreak research should feed directly into safety training pipelines.
For Embodied AI Deployers
- Static safety certifications are insufficient. A model certified as safe today may not be safe against attacks published next month. Demand ongoing safety monitoring and update commitments from VLA vendors.
Read the full paper on arXiv · PDF