Jailbreak Foundry: From Papers to Runnable Attacks for Reproducible Benchmarking
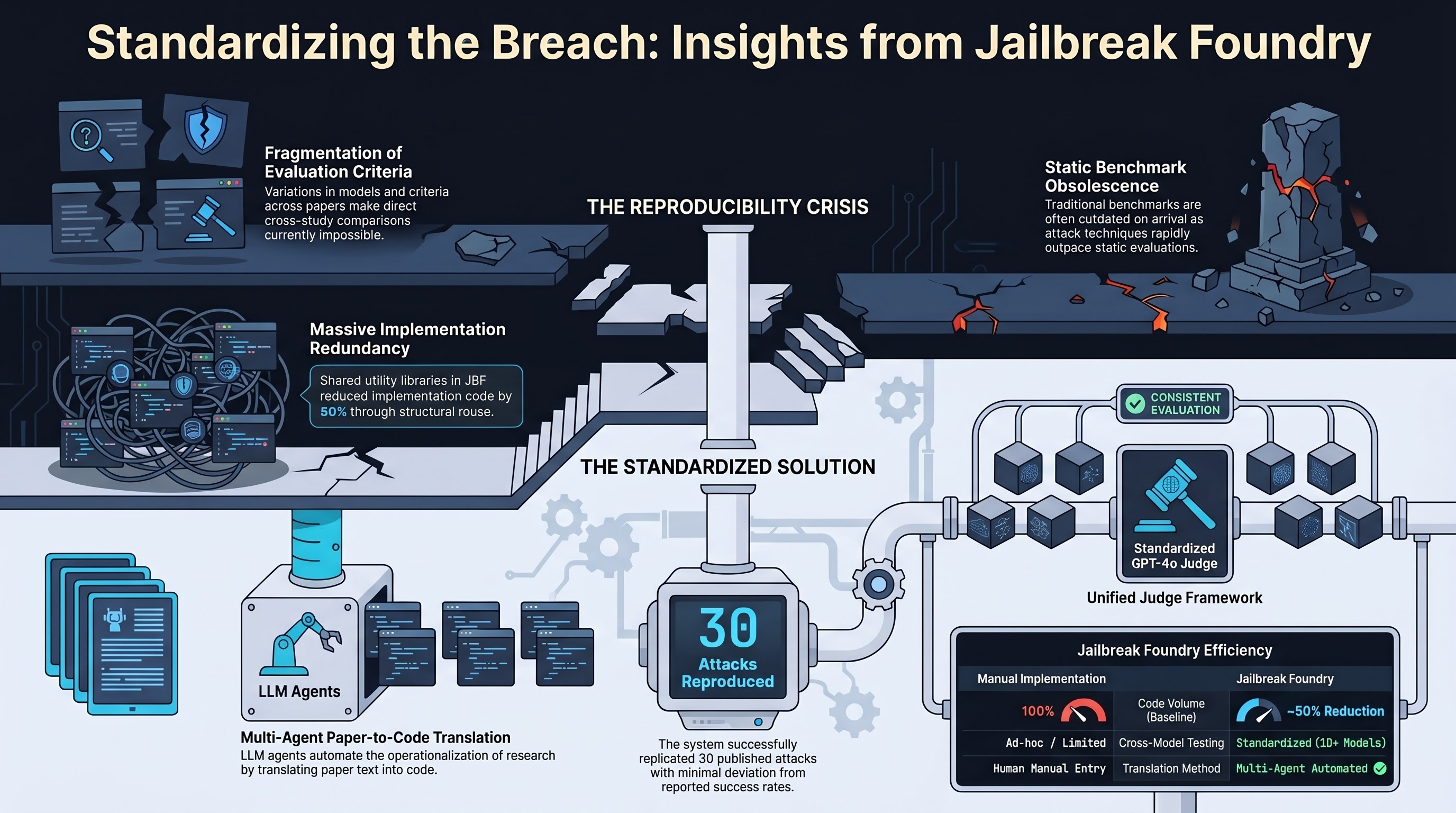
Presents JBF, a system that translates jailbreak attack papers into executable modules via multi-agent workflows, reproducing 30 attacks with minimal deviation from reported success rates and enabling standardized cross-model evaluation.
Jailbreak Foundry: From Papers to Runnable Attacks for Reproducible Benchmarking
Focus: Fang et al. address a fundamental infrastructure problem in jailbreak research: attack techniques advance faster than evaluation benchmarks, making cross-study comparisons unreliable. Jailbreak Foundry (JBF) provides three components — a shared utility library, a multi-agent workflow that translates attack papers into executable code modules, and a standardized evaluation framework. The system reproduced 30 published attacks with minimal deviation from reported success rates while reducing implementation code by approximately 50% through reuse, and evaluates all attacks consistently across 10 victim models using GPT-4o as judge.
Key Insights
-
Reproducibility crisis in jailbreak research. Different papers test different attacks on different models with different evaluation criteria, making it impossible to compare results. JBF provides the standardized infrastructure that the field has been missing.
-
Multi-agent paper-to-code translation. The system uses an agent workflow to read attack papers and generate executable implementations, demonstrating that LLMs can automate the operationalization of research — a capability with dual-use implications.
-
Code reuse reduces implementation burden. The shared utility library cut implementation code by roughly half, suggesting that many jailbreak techniques share common structural components that can be factored out and standardized.
-
Living benchmark concept. Rather than static benchmark snapshots, JBF aims to create continuously updated evaluations that keep pace with the attack landscape, a significant improvement over periodic benchmark releases that are outdated on arrival.
Failure-First Relevance
JBF addresses a problem we encounter directly in our benchmarking work: the difficulty of reproducing published attack results and comparing across studies. Our jailbreak corpus database and benchmark runner infrastructure solve related problems from a different angle — we unify prompts and results into a queryable store while JBF unifies attack implementations into executable modules. The multi-agent paper-to-code workflow raises important questions about automated capability amplification that connect to our research on agentic AI safety. The finding that attack techniques share reusable components aligns with our technique taxonomy, which identifies common structural patterns across attack families.
Open Questions
-
Does the multi-agent paper-to-code pipeline introduce systematic biases — for example, do the translating agents interpret ambiguous implementation details in ways that consistently favor higher or lower attack success rates?
-
How should the AI safety community balance the value of reproducible attack benchmarks against the risk of lowering the barrier to operationalizing new attacks?
-
Can the shared utility library’s common components inform defensive strategies — if attacks share structure, can defenses target those shared elements?
Read the full paper on arXiv · PDF