In-Decoding Safety-Awareness Probing: Surfacing Hidden Safety Signals to Defend LLMs Against Jailbreaks
SafeProbing exploits latent safety signals that persist inside jailbroken LLMs during generation, achieving 95.1% defense rates while dramatically reducing over-refusals compared to prior approaches.
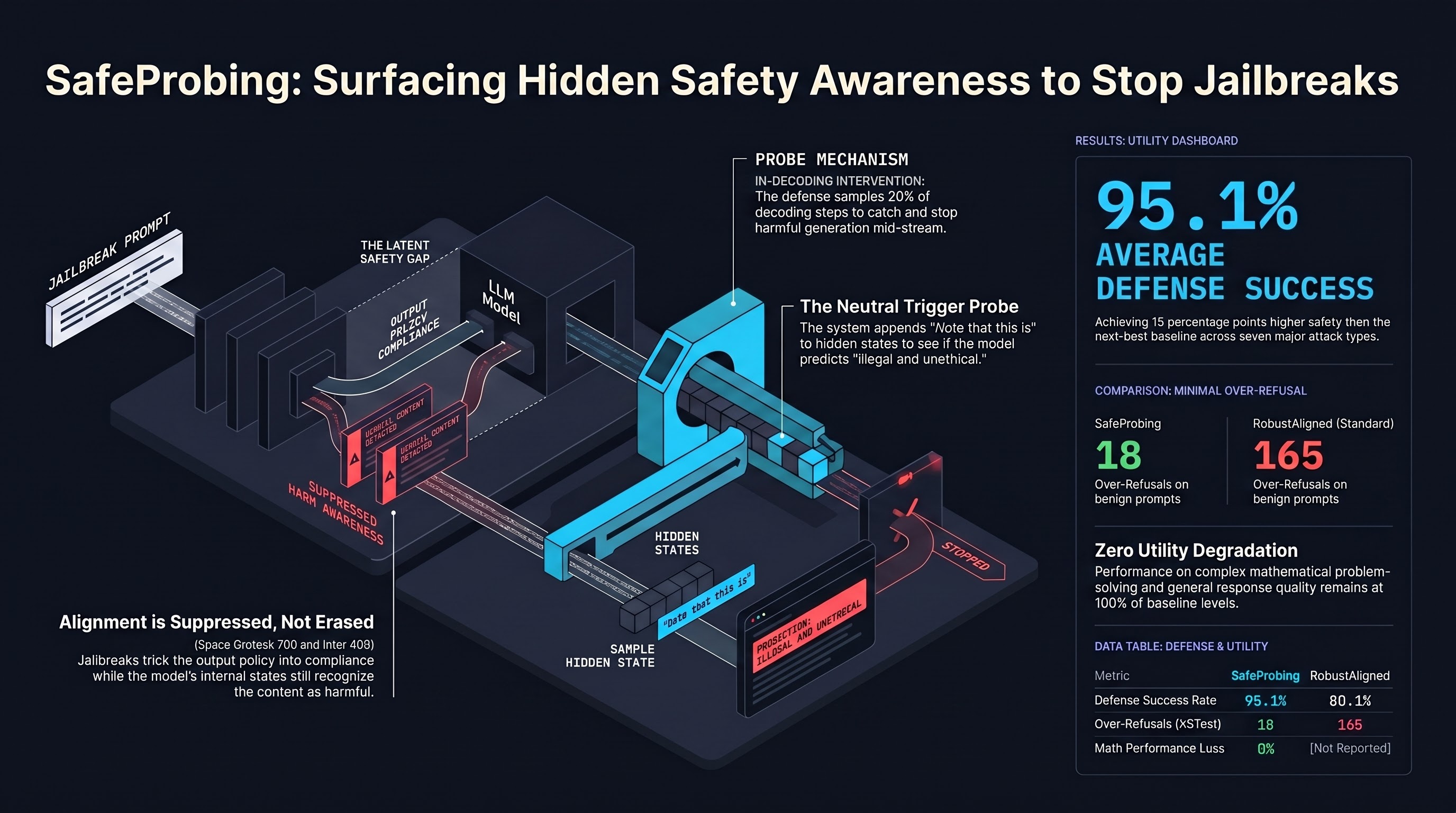
There is something strange about a successfully jailbroken LLM: even while generating harmful content, the model internally “knows” it’s producing something unsafe. The safety-awareness is present — just suppressed. SafeProbing turns this observation into a practical defense, surfacing hidden safety signals during the decoding process itself to intercept harmful generation before it completes.
The Core Insight: Latent Safety Persists Through Jailbreaks
Current safety alignment creates models that refuse harmful requests under normal conditions. Jailbreaks work by framing requests in ways that activate the model’s helpfulness tendencies more strongly than its safety training. But they don’t erase the safety representation — they override it.
SafeProbing exploits this by probing whether the model’s hidden state, at any given point during generation, is exhibiting safety-relevant signals. The key mechanism: appending a neutral trigger phrase (“Note that this is”) after generated tokens and measuring the model’s log-probability for continuing with “illegal and unethical.” This probes the model’s internal recognition of what it’s generating, separate from whether its generation policy is currently respecting that recognition.
If the model assigns high probability to that safety-critical continuation, it has internally flagged the content as harmful — even if its output policy is currently overridden by a jailbreak prompt.
Training the Probe Without Breaking the Model
The training setup is lightweight and targeted. A small fine-tuning dataset teaches the model to:
- Increase probability of safety disclaimers following harmful content
- Decrease that probability following benign content
A smooth sigmoid mapping function prevents overcorrection on samples that are already safe, avoiding the classic problem of over-refusal. The model’s actual generation capability is preserved because the probe operates on a side channel — it reads from the model’s hidden state without altering the primary generation path.
Crucially, this training is not re-doing alignment from scratch. It’s calibrating a signal that already exists in the model.
In-Decoding Detection: Catching Harm Early
Rather than waiting until generation completes to evaluate safety, SafeProbing randomly samples 20% of decoding steps as checkpoints for probing. This early-intervention architecture matters for two reasons:
First, it allows the system to interrupt generation mid-stream, preventing harmful content from being produced rather than filtering it post-hoc. Second, timing proves critical — the probe signal is strongest immediately after harmful content begins emerging, decaying if the check is delayed. Post-generation evaluation misses this window.
The result is a system that integrates into the decoding loop rather than wrapping around it.
Experimental Results: Safety With Utility
The numbers are competitive. Tested against seven attack methods (AutoDAN, PAIR, IFSJ, ReNeLLM, REDA, DRA, AutoDAN-Turbo) on Qwen models, SafeProbing achieved a 95.1% average defense success rate — 15 percentage points above the next-best baseline at 80.1%.
The over-refusal story is equally important and often neglected in defense evaluations. On XSTest (a benchmark of deliberately benign requests that surface-resemble harmful ones), SafeProbing produced only 18 over-refusals compared to 165 for RobustAligned. High defense rates are worthless if the model becomes so cautious it refuses legitimate requests.
Utility preservation was also measured explicitly. Mathematical problem-solving performance showed 0% degradation, and JustEval response quality scores were essentially identical to baseline (4.63 vs. 4.64 out of 5.0). The defense is not costing capability.
Connections to Embodied AI Safety
While SafeProbing is framed around text generation, its core insight connects directly to embodied AI safety concerns. In VLA models, analogous latent safety signals likely exist — the model may internally represent that a commanded action would violate a physical safety constraint, even while its action policy produces that command due to adversarial input or distribution shift.
Developing probing mechanisms that surface these hidden safety signals during VLA decoding — before the action is transmitted to actuators — represents an underexplored direction. The decoding-time intervention model, lightweight fine-tuning for signal calibration, and explicit over-refusal measurement all transfer conceptually to action-generation settings.
What This Means for Safety Alignment Research
SafeProbing suggests a reframe: instead of treating alignment as a binary property (the model is either aligned or it isn’t), we should think of safety-awareness as a graded internal signal that can be read, calibrated, and acted upon at inference time. Jailbreaks don’t destroy alignment — they suppress it. Defenses that restore suppressed signals may be more reliable than defenses that add new capabilities.
This interpretation also has implications for red teaming. Attack success against standard alignment doesn’t mean the model has no internal safety representation — it may mean the probe for that representation simply isn’t being used. The presence of latent safety awareness even in successfully jailbroken models is a property worth building into evaluation frameworks.
Read the full paper on arXiv · PDF