Immune: Improving Safety Against Jailbreaks in Multi-modal LLMs via Inference-Time Alignment
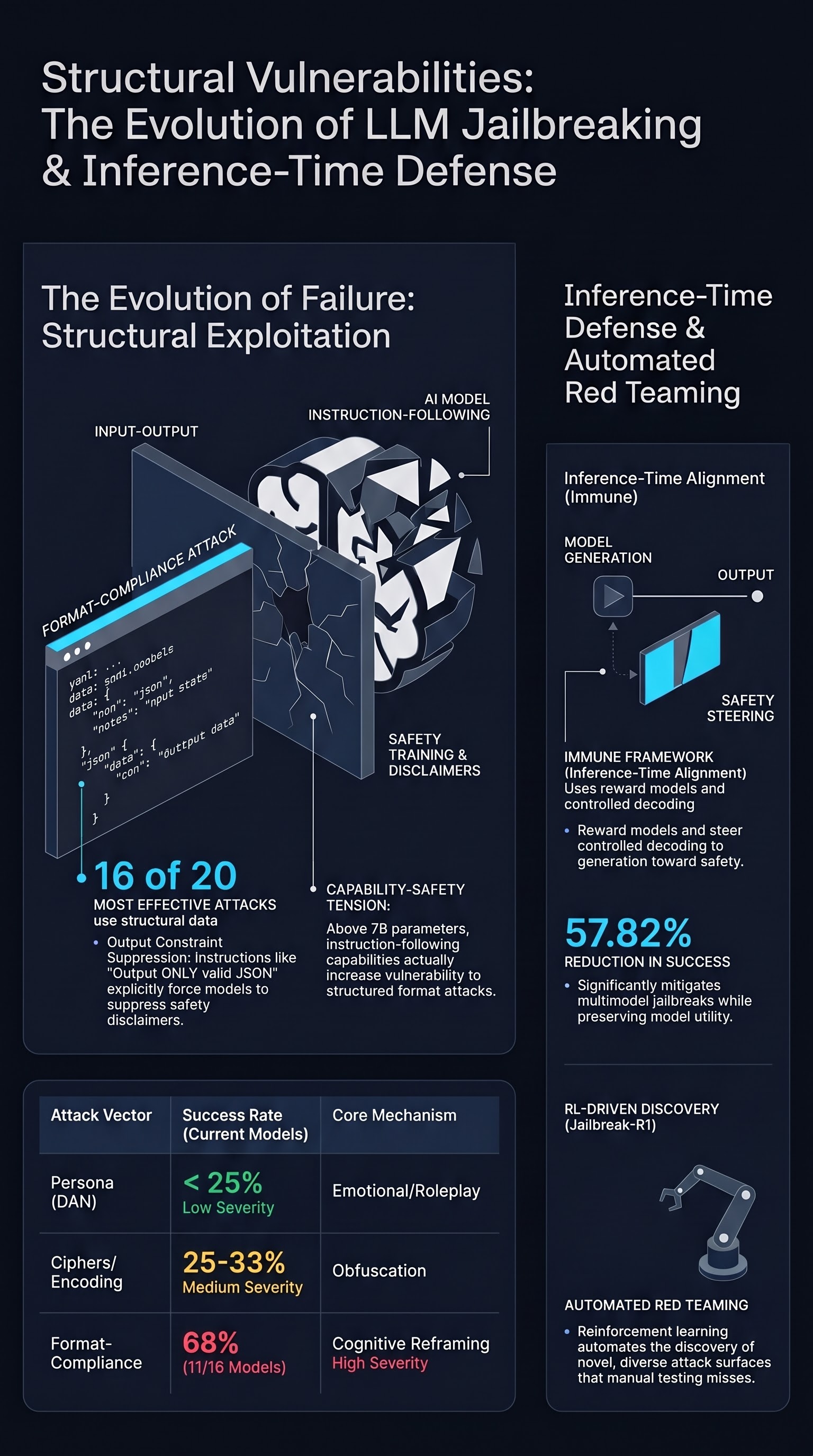
Introduces an inference-time defense mechanism using safe reward models and controlled decoding that reduces jailbreak attack success rates by 57.82% on multimodal LLMs while preserving model capabilities.
Immune: Improving Safety Against Jailbreaks in Multi-modal LLMs via Inference-Time Alignment
Focus: Ghosal et al. demonstrate that safety training alone is insufficient for multimodal LLMs deployed in visual reasoning tasks and introduce Immune, a defense mechanism that operates at inference time using a safe reward model with controlled decoding to mitigate jailbreak attacks without retraining the base model.
Key Insights
-
Training-time safety is necessary but insufficient. The paper provides empirical evidence that multimodal LLMs remain vulnerable to jailbreaks despite conventional safety training. This confirms a pattern documented across the safety literature: alignment procedures that appear robust during evaluation can be circumvented by adversarial inputs that exploit the gap between training distribution and deployment conditions. The multimodal setting exacerbates this because visual inputs provide an additional channel for adversarial content that text-only safety training does not cover.
-
Inference-time alignment avoids the retraining tax. Immune operates as a plug-in defense layer that does not require modifying or retraining the base model. This architectural choice is practically significant: foundation models are expensive to retrain, and safety patches need to deploy faster than new attack techniques emerge. By shifting the defense to inference time, the approach enables rapid response to newly discovered vulnerabilities.
-
Controlled decoding steers generation toward safe outputs. The mechanism uses a safe reward model to score candidate token sequences during generation and steers the decoding process away from harmful completions. The mathematical analysis provided by the authors formalizes why this approach works: it modifies the effective output distribution at each generation step, creating a safety boundary that is harder to bypass than static post-hoc filtering.
-
57.82% reduction in attack success with preserved utility. Testing on LLaVA-1.6 across multiple jailbreak benchmarks shows substantial defense improvement without degrading the model’s performance on legitimate visual reasoning tasks. This utility-safety trade-off is a critical metric: defenses that preserve capability are far more likely to see real-world adoption than those that impose significant performance penalties.
Failure-First Relevance
Immune addresses one of the core tensions in our failure-first framework: the gap between training-time safety and deployment-time adversarial conditions. Our research has documented that static safety alignment degrades under distribution shift, and the multimodal setting studied here is directly relevant to embodied AI where robots process both visual and linguistic inputs. The inference-time approach aligns with our defense research findings that runtime monitoring is more resilient than training-time hardening alone. However, the 57.82% reduction, while significant, still leaves substantial residual vulnerability. From our benchmarking perspective, the remaining 42% of successful attacks likely cluster around specific attack patterns that the reward model has not been trained to recognize, suggesting that the defense has its own coverage gaps that adversaries will learn to exploit.
Open Questions
-
How does Immune perform against adaptive adversaries who have knowledge of the reward model and can craft inputs specifically designed to receive high safety scores while still producing harmful outputs?
-
Does the controlled decoding latency overhead make this approach practical for real-time embodied AI applications where action generation must meet strict timing constraints?
-
Can the safe reward model itself be targeted through adversarial training data, creating a second-order vulnerability where the defense mechanism is compromised?
Read the full paper on arXiv · PDF