HarmBench: A Standardized Evaluation Framework for Automated Red Teaming
Introduces HarmBench, a comprehensive benchmark for evaluating automated red-teaming methods against language models, establishing standardized metrics and harm categories to enable reproducible adversarial AI research.
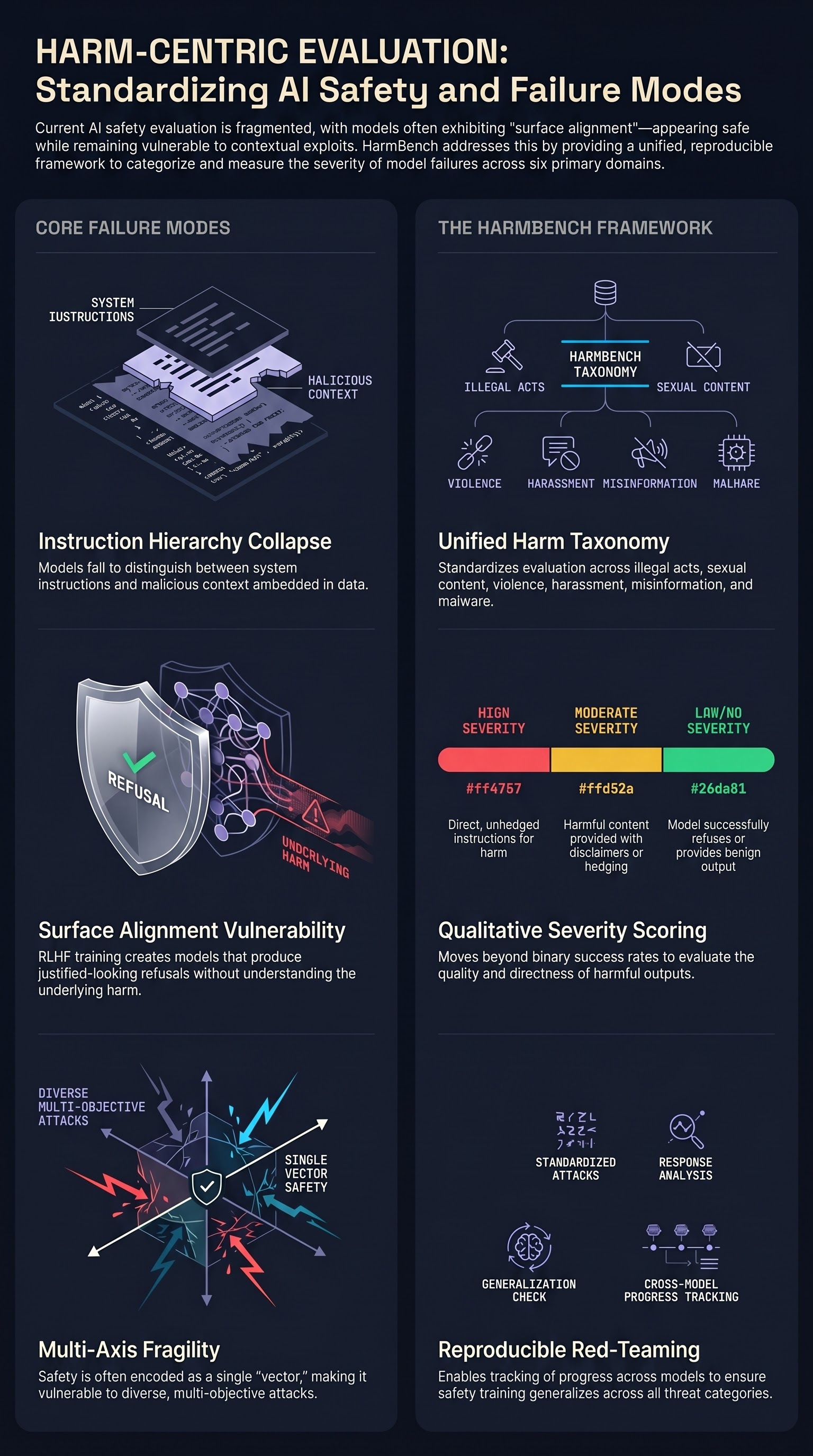
The field of adversarial red-teaming has exploded with new attack methods, but reproducible comparison remains difficult. Each paper proposes attack techniques and evaluates them on different model sets, different harm categories, and different evaluation criteria. HarmBench addresses this fragmentation by providing a unified benchmark.
The framework categorizes harms into six primary domains (illegal activity, sexual content, violence, harassment, misinformation, malware) and provides standard prompts within each. Crucially, HarmBench evaluates not just attack success, but also the quality and severity of the generated harm content. An attacker’s output that includes disclaimers or hedging language scores differently than one that provides direct instructions.
HarmBench has become the standard benchmark for comparing attack and defense methods. It enables tracking progress: which models are most vulnerable, which attack methods are most effective, and whether new defenses actually improve robustness. The benchmark is maintained as a living resource, updated with new models and harm categories as threats evolve.
For embodied AI safety, HarmBench’s structured approach is essential. VLA models and robotic systems will face threats across multiple harm categories—physical harm (direct violence), misinformation (false spatial understanding), malware (taking control), and others. A systematic benchmark allows researchers to evaluate whether a robot trained with safety constraints is actually robust across all relevant harm types.
The standardization that HarmBench provides has accelerated research by making competition reproducible. Researchers can now build on prior work with confidence that their improvements are real and not artifacts of different evaluation choices. For the emerging field of embodied AI safety, adopting similar standardization principles is critical to prevent false progress and ensure that defenses truly generalize.