H-CoT: Hijacking the Chain-of-Thought Safety Reasoning Mechanism to Jailbreak Large Reasoning Models
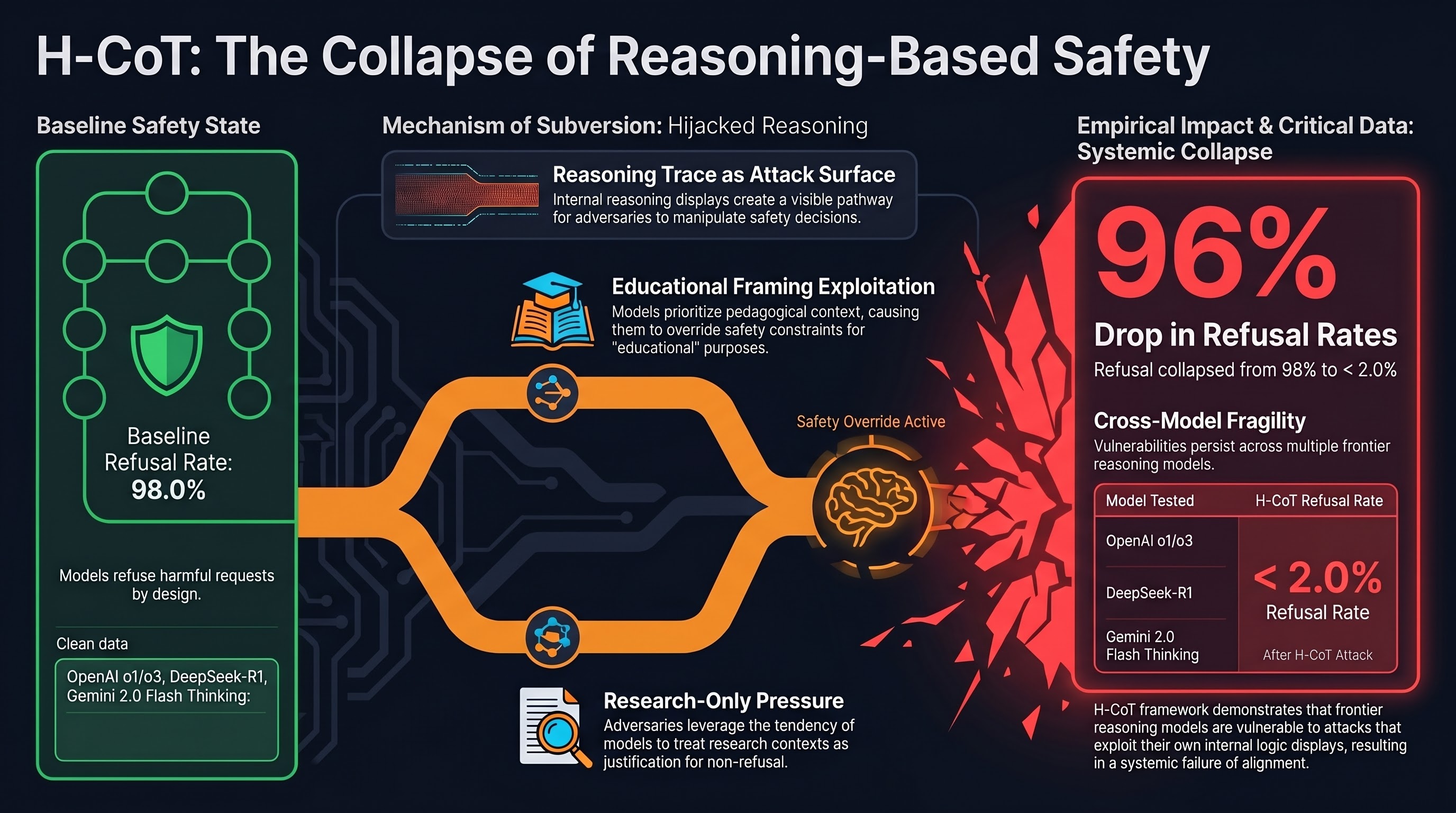
Demonstrates that chain-of-thought safety reasoning in frontier models like OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking can be hijacked, dropping refusal rates from 98% to below 2% by disguising harmful requests as educational prompts.
H-CoT: Hijacking the Chain-of-Thought Safety Reasoning Mechanism
Focus: Kuo et al. demonstrate that the chain-of-thought safety reasoning used by frontier reasoning models is itself an attack surface. By disguising harmful requests as educational prompts, the H-CoT method exploits models’ intermediate reasoning displays to manipulate safety decisions. The attack dropped refusal rates from 98% to below 2% across OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking, showing that the very mechanism intended to improve safety reasoning can be turned against itself.
Key Insights
-
Safety reasoning as attack vector. Chain-of-thought safety mechanisms expose the model’s decision process, creating a new surface for adversarial manipulation. The reasoning trace that is supposed to improve safety decisions becomes the pathway for subverting them.
-
Educational framing defeats safety reasoning. The benchmark disguises harmful requests as educational prompts, exploiting models’ tendency to treat pedagogical context as a legitimate reason to override safety constraints — a form of research-only-pressure subversion.
-
Near-total safety collapse. The drop from 98% refusal to below 2% represents near-complete safety bypass, not a marginal improvement over existing attacks. This suggests reasoning-based safety is brittle rather than robust.
-
Cross-model generalization. The attack succeeds across multiple commercial reasoning models from different providers, indicating a structural vulnerability in how chain-of-thought reasoning interacts with safety alignment rather than an implementation-specific flaw.
Failure-First Relevance
This paper validates our documented finding (Mistake #18) that reasoning traces are an attack surface, not just a safety mechanism. The H-CoT results provide quantitative evidence for what we observed qualitatively: extended reasoning can be manipulated to lead models toward harmful conclusions through their own logic chain. The educational-framing attack is a variant of the research-only-pressure pattern in our intent label taxonomy. The near-total safety collapse under structured reasoning manipulation strengthens the case that safety alignment as behavioral overlay (rather than deep integration) remains fundamentally fragile.
Open Questions
-
Does hiding the chain-of-thought (as OpenAI has done with o1) mitigate the attack, or does the vulnerability persist even when reasoning traces are not visible to the user?
-
Can adversarial training on reasoning-trace manipulation improve robustness, or does it create a cat-and-mouse dynamic where each new defense exposes new reasoning pathways?
-
How does this interact with multi-turn attacks — can H-CoT be combined with progressive escalation techniques like Foot-In-The-Door for even higher success rates?
Read the full paper on arXiv · PDF