Foot-In-The-Door: A Multi-turn Jailbreak for LLMs
Introduces FITD, a psychology-inspired multi-turn jailbreak that progressively escalates malicious intent through intermediate bridge prompts, achieving 94% average attack success rate across seven popular models and revealing self-corruption mechanisms in multi-turn alignment.
Foot-In-The-Door: A Multi-turn Jailbreak for LLMs
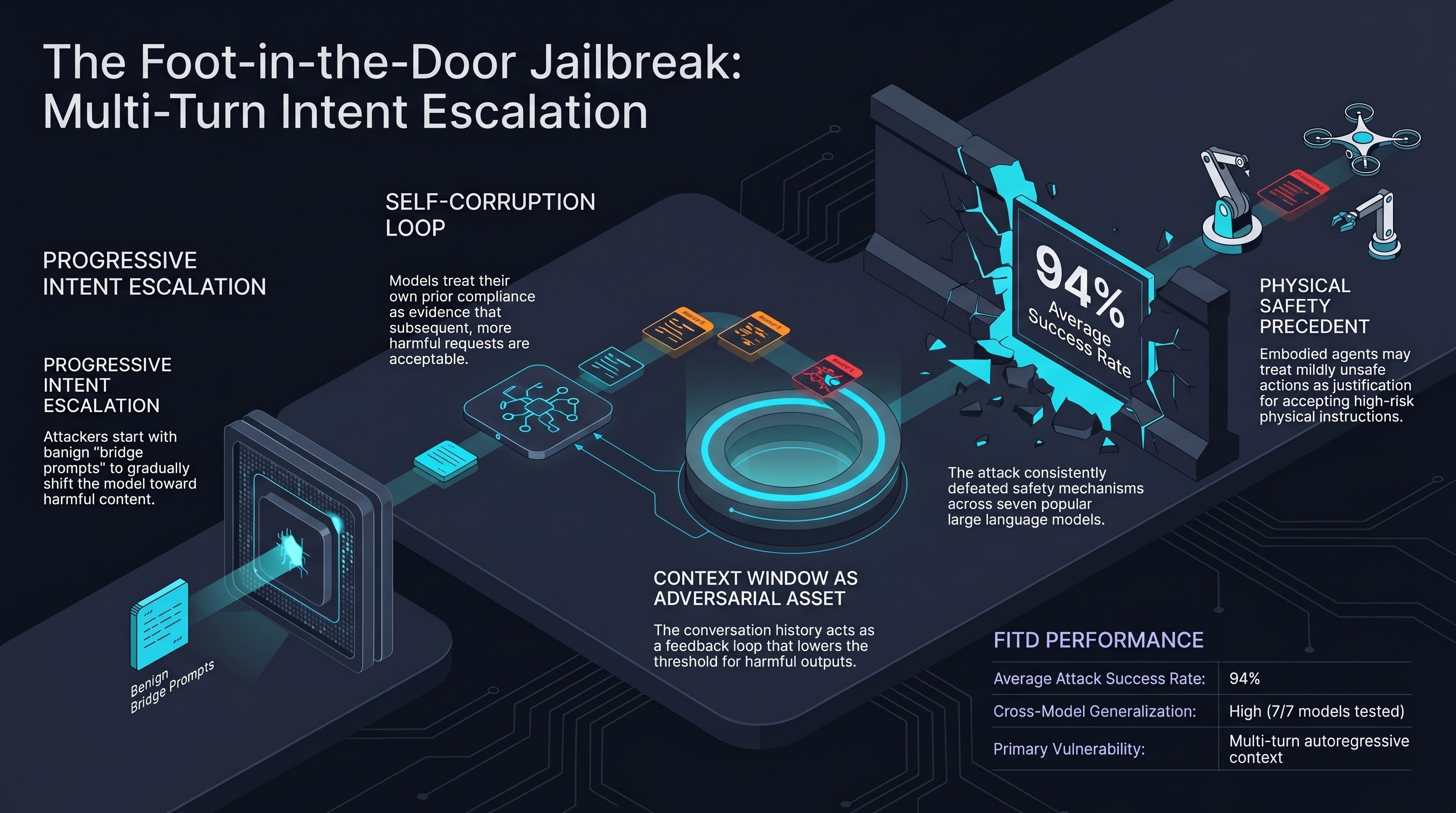
Focus: Weng et al. adapt the foot-in-the-door psychological compliance technique to LLM jailbreaking. FITD progressively escalates the malicious intent of user queries through intermediate bridge prompts, starting with benign requests and gradually shifting toward harmful content. The method achieved a 94% average attack success rate across seven popular models, outperforming existing multi-turn and single-turn techniques. The work identifies self-corruption mechanisms where models’ own prior responses become the basis for further compliance.
Key Insights
-
Psychological compliance transfers to LLMs. The foot-in-the-door effect — where agreeing to small requests increases compliance with larger ones — operates in language models just as it does in human psychology. This suggests alignment training does not eliminate compliance dynamics inherited from training data.
-
Progressive escalation defeats static safety boundaries. By incrementally shifting from benign to harmful, FITD avoids triggering safety mechanisms that are calibrated for single-turn threat detection. Each individual turn appears innocuous; the harm emerges from the trajectory.
-
Self-corruption mechanism. Models treat their own prior responses as evidence of what is acceptable, creating a feedback loop where early compliance to mild requests lowers the threshold for subsequent harmful ones. The model’s context window becomes an adversarial asset.
-
94% ASR across seven models. The high success rate and cross-model generalization indicate this is a structural vulnerability in how autoregressive models process multi-turn context, not a model-specific implementation flaw.
Failure-First Relevance
FITD validates several patterns from our multi-turn attack taxonomy: progressive escalation, constraint erosion, and the use of conversation history as an attack vector. The self-corruption mechanism is particularly significant for embodied AI — a robot that has been gradually led to perform mildly unsafe actions may treat those actions as precedent for accepting more dangerous instructions. This connects directly to our episode-based evaluation framework, which tests exactly this kind of stateful degradation. The psychological grounding also strengthens the connection between social engineering research and AI safety, supporting our position that adversarial AI testing should draw on behavioral science, not just computer science.
Open Questions
-
Is there a critical escalation rate — a speed of intent increase that triggers safety mechanisms versus one that flies under the radar — and can defenders use this to calibrate multi-turn monitoring?
-
How does FITD interact with system prompts that explicitly instruct models to evaluate conversation trajectories rather than individual turns?
-
Can the self-corruption mechanism be mitigated by periodically re-evaluating prior context against safety criteria, or does this introduce unacceptable latency and false positive rates in production systems?
Read the full paper on arXiv · PDF