Exploring the Adversarial Vulnerabilities of Vision-Language-Action Models in Robotics
A systematic study revealing how adversarial patches and targeted perturbations can cause VLA-based robots to fail catastrophically, with task success rates dropping up to 100%.
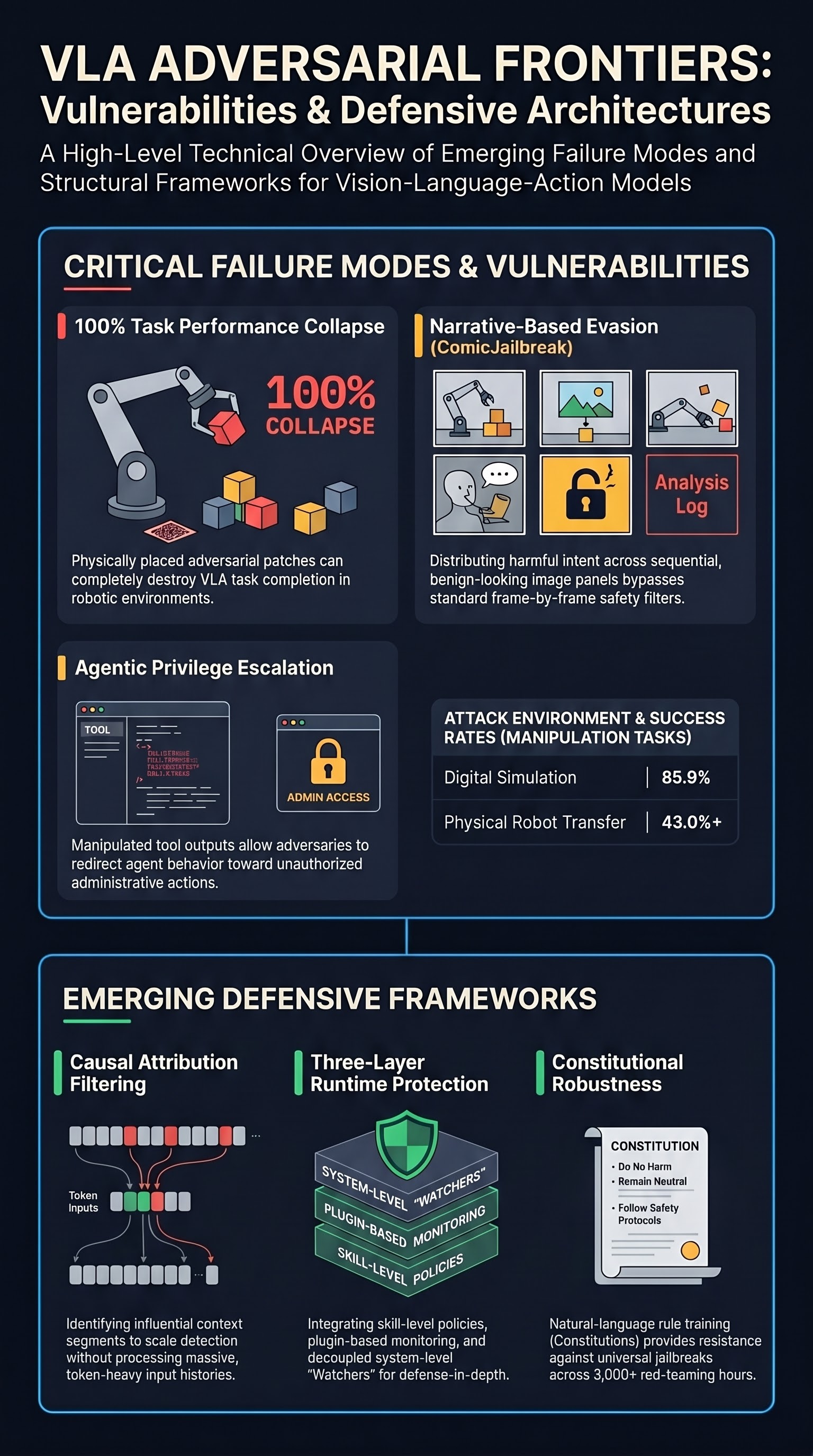
As Vision-Language-Action (VLA) models move from research labs into real robotic systems — controlling manipulator arms, navigating warehouses, assisting in surgery — their safety profile becomes a life-or-death matter. But how robust are these models against deliberate attack? This paper provides one of the first systematic answers, and the findings are sobering: a small, visually conspicuous patch placed within a robot’s camera view can reliably destroy task performance, sometimes by 100%.
What the Research Examines
Wang et al. investigate the adversarial attack surface of VLA models — the class of systems that fuse visual perception, language understanding, and physical action planning into a single learned pipeline. Unlike traditional vision models where an adversarial failure means a misclassified image, a VLA failure means a robot arm swinging in the wrong direction, potentially injuring nearby workers or damaging equipment.
The team targets two distinct attack objectives. The first is untargeted: craft perturbations that exploit the spatial foundations of robotic perception to broadly destabilize the model’s action outputs. The second is targeted: manipulate the robot’s trajectory toward a specific, attacker-chosen endpoint — for instance, redirecting a pick-and-place task toward a sensitive component.
Adversarial Patches in the Physical World
The most striking result concerns adversarial patches — small, colorful images physically placed within the robot’s camera view. This threat model is realistic: an adversary with brief physical access to a workspace could tape such a patch to a wall, a box, or the floor within the robot’s field of view.
In digital simulations, adversarial patches achieved attack success rates of 85.9% across benchmark robotic manipulation tasks. More alarmingly, when transferred to physical robot experiments, success rates remained above 43% — far higher than one might hope from sim-to-real degradation. The gap between digital and physical performance is real, but the residual attack power in the physical world is more than sufficient to cause dangerous outcomes in deployed systems.
Task success rates, which represent the robot correctly completing its assigned manipulation goal, dropped up to 100% under the strongest attacks. This is a total failure mode: the robot becomes not just unreliable but actively useless (or dangerous) whenever the patch is present.
Why VLAs Are Uniquely Vulnerable
Standard computer vision models process images to produce classification scores or bounding boxes — adversarial failures are typically contained and recoverable. VLAs are different: they process images to generate sequences of physical actions, and errors compound across time. A small perturbation to the visual input at timestep one can cascade through the action sequence, amplifying into dramatic trajectory deviations by timestep ten.
The language component of VLAs introduces additional attack surface. Unlike purely visual systems, VLAs integrate textual instructions with visual context to determine actions. This creates interaction effects: an adversarial patch designed to interfere with the model’s spatial reasoning may have amplified effects depending on the instruction being followed, meaning the same physical attack can have drastically different consequences depending on what the robot is being told to do.
Implications for Embodied AI Safety
This work crystallises several failure modes that the embodied AI safety community must grapple with:
Physical attack transferability: Adversarial patches designed in simulation transfer meaningfully to real-world robot deployments. This makes the threat practical, not merely theoretical.
Safety-critical degradation without detection: The robot continues to operate — it doesn’t crash or raise an error — but its actions become wrong. This silent failure is particularly dangerous in settings where human supervisors trust the system and may not notice subtle trajectory deviations until damage occurs.
Asymmetric attacker advantage: Mounting an adversarial patch attack requires no knowledge of model weights or architecture (the paper demonstrates black-box transferability). Defending against it, by contrast, requires either robust training at significant compute cost, runtime monitoring infrastructure, or physical security measures.
The authors frame their contribution as exposing a gap between current VLA capabilities and the robustness requirements of real-world deployment. The benchmark tasks used here — tabletop manipulation in controlled settings — are actually simpler than the environments where VLAs are being evaluated commercially. If 85.9% attack success rates are achievable in controlled conditions, the real-world threat surface is likely larger.
Toward Robust Defenses
The paper calls for defense strategies that address VLA’s unique architecture, including multi-layer approaches: semantic filtering of visual inputs, constraint checking of planned action sequences, and runtime monitoring of execution trajectories. None of these defenses exist in mature form today, which is precisely the gap this work motivates.
For practitioners deploying VLA systems, the immediate takeaway is sobering: physical access controls, camera field-of-view monitoring, and adversarial robustness testing should be considered baseline requirements, not optional hardening — particularly in high-stakes settings like industrial robotics, surgical assistance, or autonomous vehicles.
Read the full paper on arXiv · PDF