DrAttack: Prompt Decomposition and Reconstruction Makes Powerful LLM Jailbreakers
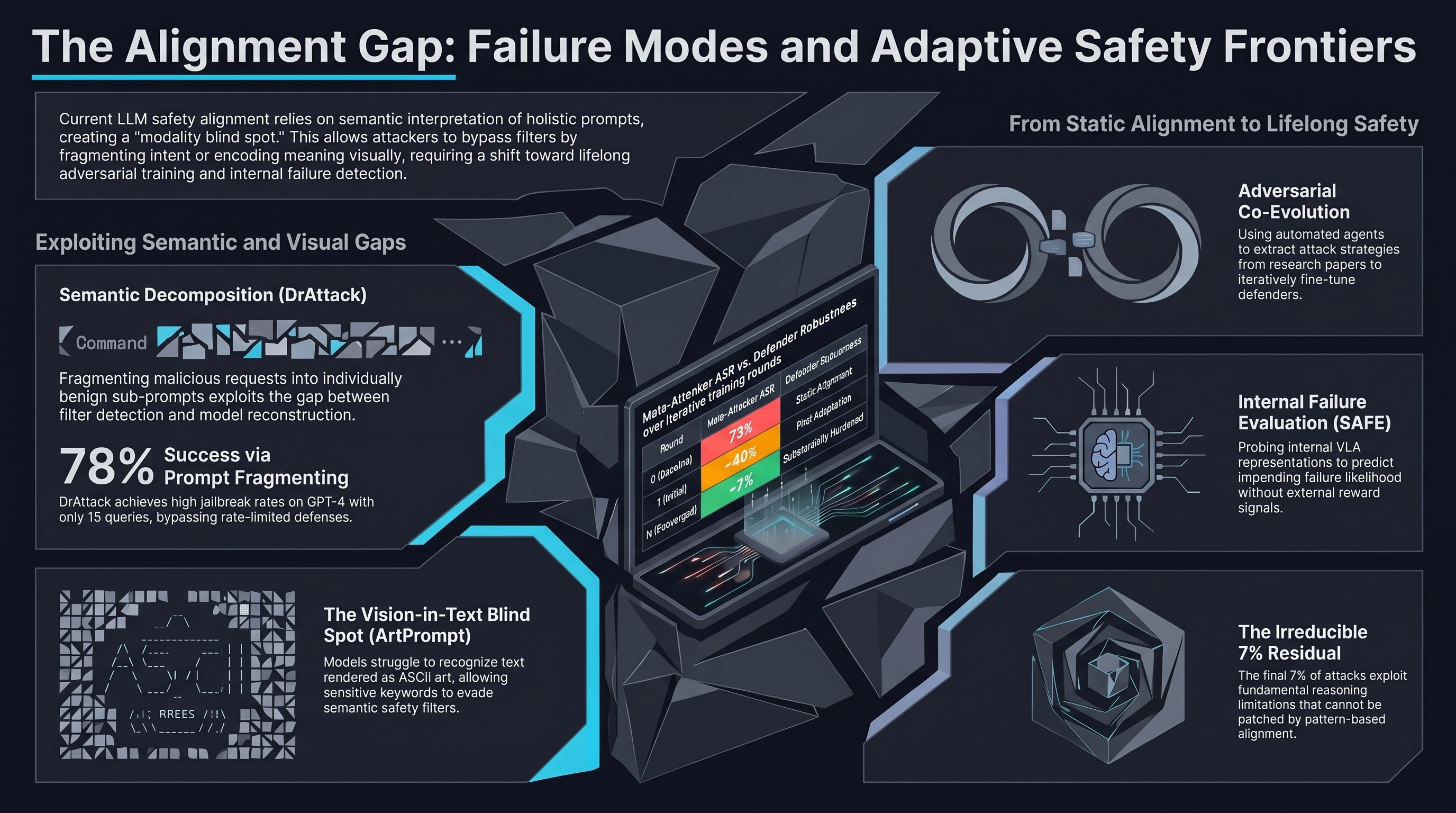
Introduces an automatic framework that decomposes malicious prompts into harmless-looking sub-prompts and reconstructs them via in-context learning, achieving 78% success on GPT-4 with only 15 queries and surpassing prior state-of-the-art by 33.1 percentage points.
DrAttack: Prompt Decomposition and Reconstruction Makes Powerful LLM Jailbreakers
Focus: Li et al. demonstrate that decomposing a malicious prompt into separated sub-prompts effectively obscures its intent by presenting it in a fragmented, less detectable form. DrAttack automates this process with three components: decomposition of the original prompt, reconstruction via in-context learning with harmless reassembly demonstrations, and synonym search to find substitute sub-prompts that maintain intent while evading detection.
Key Insights
-
Fragmentation defeats semantic safety filters. Safety alignment typically operates on the holistic semantics of a prompt. By splitting a harmful request into individually innocuous fragments, DrAttack exploits the gap between how safety filters assess intent and how models reconstruct meaning from parts.
-
In-context learning as a reconstruction weapon. The framework uses semantically similar but harmless reassembly demonstrations to teach the model how to reconstruct the decomposed prompt. The model follows the demonstrated pattern without recognizing that the reconstructed output is harmful.
-
Query efficiency. DrAttack achieves 78% success on GPT-4 with only 15 queries, compared to prior methods requiring hundreds or thousands. This makes the attack practical in settings where API access is rate-limited or monitored.
-
Synonym substitution adds robustness. The synonym search component finds alternative phrasings for sub-prompts that maintain the original semantic intent while further evading keyword-based and pattern-based detection.
Failure-First Relevance
DrAttack exemplifies the decomposition attack class in our taxonomy, where the atomic unit of harm is distributed across multiple prompt components that are individually benign. This is directly relevant to embodied AI multi-turn scenarios, where an adversary could issue a sequence of innocuous-seeming commands that, when the agent reconstructs the full task, result in harmful behavior. The in-context learning reconstruction mechanism also connects to our dataset poisoning research, where demonstration examples steer model behavior in ways that safety training does not anticipate. The query efficiency finding matters for our benchmark methodology: attacks that succeed in fewer than 20 queries are particularly dangerous because they evade rate-limit-based defenses.
Open Questions
-
How effective is DrAttack against models with instruction hierarchy enforcement, where system-level safety instructions take precedence over user-provided in-context demonstrations?
-
Does the decomposition-reconstruction pattern transfer to multimodal settings where sub-prompts could be distributed across text and image inputs?
-
Can safety filters be trained to detect the statistical signature of decomposed prompts, such as unusually fragmented syntax combined with reassembly instructions?
Read the full paper on arXiv · PDF