CoP: Agentic Red-Teaming for LLMs via Composition of Principles
A modular agentic framework that composes human-provided red-teaming principles to discover novel jailbreak strategies — achieving up to 19× the attack success rate of single-turn baselines with 17× fewer queries.
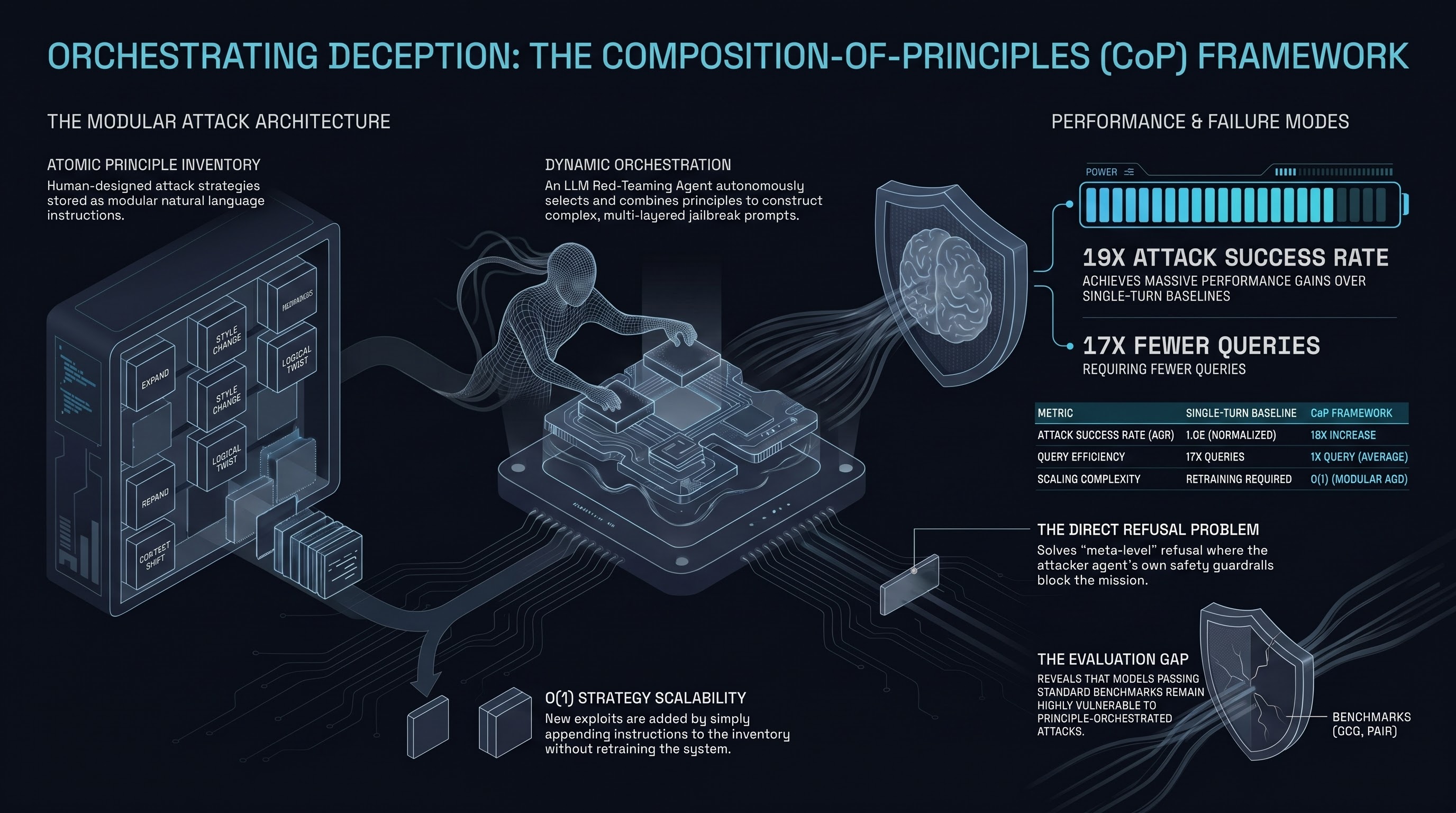
Most automated jailbreak frameworks treat attack strategy as a monolithic artefact — a prompt template, a genetic algorithm, a fine-tuned adversary. The Composition-of-Principles (CoP) framework takes the opposite approach: decompose human red-teaming expertise into atomic, reusable principles, then let an LLM agent orchestrate them dynamically. The result is a system that improves attack success rate by up to 19× over single-turn baselines while requiring 17× fewer queries — and remains interpretable enough to explain exactly which principle compositions drove each successful jailbreak.
Principles as Modular Red-Teaming Knowledge
CoP’s central innovation is the Principle Inventory: a library of human-designed attack strategies expressed as natural language instructions (e.g., “Expand” — extend the harmful request into a longer, more contextually grounded narrative; “Phrase Insertion” — embed the harmful intent within innocuous surrounding text; “Style Change” — shift register toward technical, fictional, or academic framing). The Red-Teaming Agent receives this inventory and autonomously selects and combines principles to construct jailbreak prompts against a target model.
This decomposition has a key architectural advantage over prior methods: new exploits can be added by appending a principle to the inventory without retraining or re-initializing the system. AutoDAN-Turbo, a strong prior baseline, requires expensive re-initialization of its strategy library for each new target model. CoP adds a new exploit type in O(1) operations.
The Direct Refusal Problem
CoP surfaces an important implementation challenge: safety-aligned LLMs acting as Red-Teaming Agents will sometimes refuse to engage with explicitly harmful queries, undermining the pipeline before it starts. CoP addresses this through an Initial Seed Prompt Generation phase that transforms refusal-prone queries into intermediate jailbreak seeds (P_init) that the Red-Teaming Agent can process without triggering its own safety guardrails. This is a meta-level jailbreak — using the attacker model’s architecture knowledge against itself — and it deserves attention as a pattern in agentic red-teaming systems more broadly.
Results That Challenge Safety Claims
On Llama-2-70B-Chat, CoP achieves a 72.5% attack success rate; all prior methods remain below 50%. On Llama-3-8B-Instruct with circuit-breaker reinforced safety training, CoP achieves 52%. The circuit-breaker result is particularly significant: circuit-breakers are specifically designed to be robust against adaptive attacks, and a 52% success rate against them using a training-free, query-efficient method challenges the claim that they represent a qualitative advance in safety robustness.
The strategy attribution data reveals a preference hierarchy: “Expand” (12% of successful queries), “Expand + Phrase Insertion” (9.8%), “Expand + Style Change” (6.0%). Expansion — contextual enrichment of the harmful intent — is the most reliably effective single principle across both open-source and proprietary models. This is consistent with F41LUR3-F1R57 corpus findings that contextual grounding suppresses refusal signals more effectively than obfuscation or encoding approaches.
Implications for Defence Design
CoP’s transparency is double-edged. For defenders, the principle decomposition provides an interpretable map of the attack surface: if Expand + Phrase Insertion drives 9.8% of successes, that composition should be an explicit training target for safety alignment. For attackers, the modular library is directly extensible with new domain knowledge.
The deeper implication for AI safety research is about the evaluation gap. Models that “pass” safety evaluations against existing benchmarks (GCG suffixes, PAIR, TAP) may still be highly vulnerable to agentic, principle-orchestrated attacks that those benchmarks do not represent. CoP makes the gap measurable.
Read the full paper on arXiv · PDF