Compress the Easy, Explore the Hard: Difficulty-Aware Entropy Regularization for Efficient LLM Reasoning
Proposes CEEH, a difficulty-aware entropy regularization method for RL-based LLM reasoning that selectively compresses easy questions while preserving exploration space for hard ones to maintain reasoning capability while reducing inference cost.
Compress the Easy, Explore the Hard: Difficulty-Aware Entropy Regularization for Efficient LLM Reasoning
1. Introduction: The High Cost of Chain-of-Thought
In the current “reasoning era” of Large Language Models (LLMs), Chain-of-Thought (CoT) has emerged as the gold standard for navigating complex, multi-hop deduction. By externalizing intermediate logic, models can maintain state, perform error correction, and avoid the brittle shortcuts common in zero-shot prompts. However, this cognitive power comes with a significant “verbosity tax.” The explicit generation of every logical step creates a massive efficiency bottleneck—driving up inference latency, token consumption, and serving costs to levels that often prohibit real-world production deployment.
Our objective is reasoning compression: retaining the accuracy of long-form CoT while drastically pruning the token count. Yet, the field has hit a wall. Simply forcing a model to be brief often shatters the very logic it is intended to preserve.
“Explicit reasoning often incurs significant redundancy, leading to increased inference latency, higher token consumption, and elevated serving costs. This efficiency bottleneck has motivated a growing body of research on reasoning compression.”
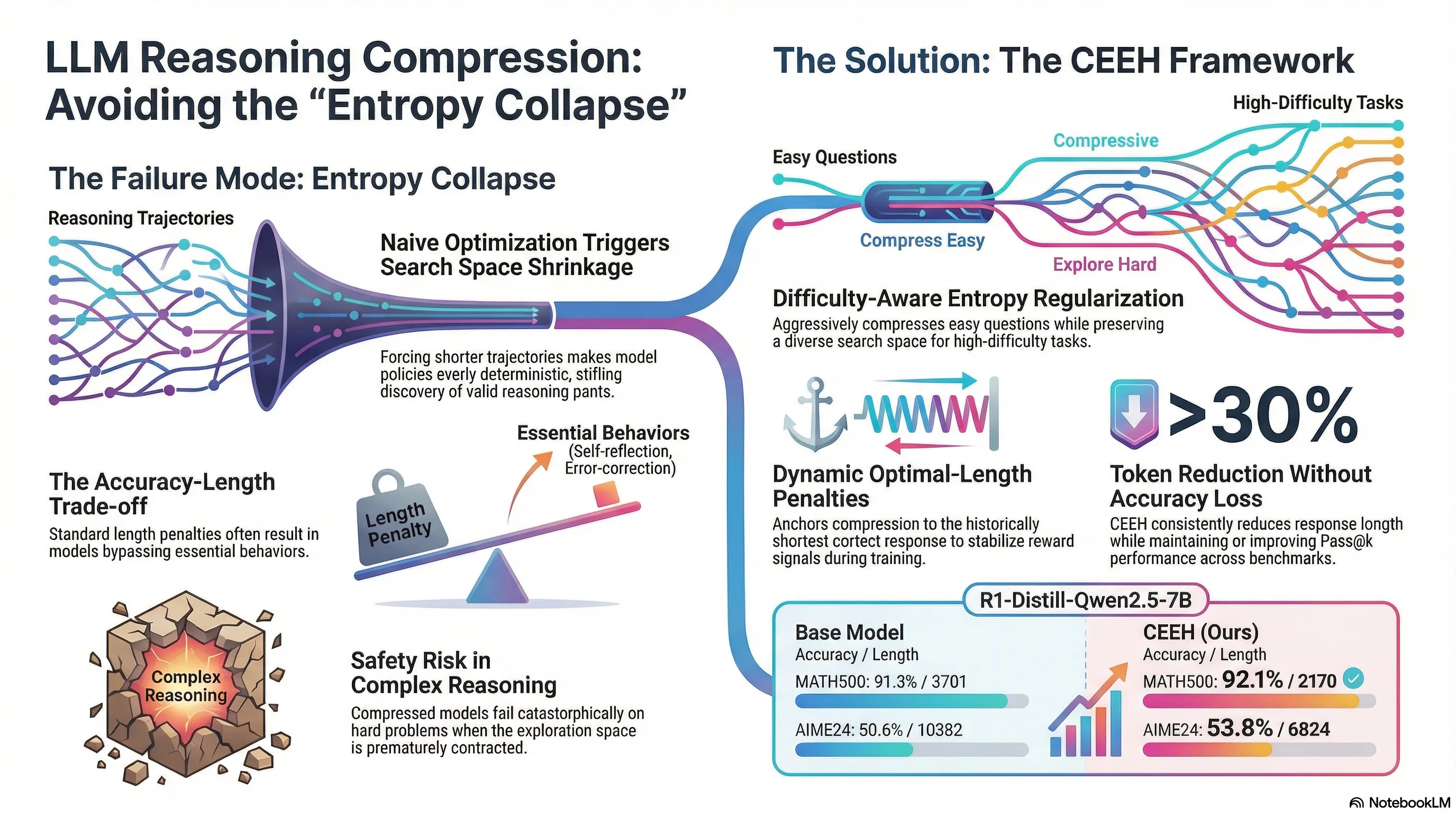
2. The Failure Mode: Why Naive Shortening Breaks Reasoning
When we apply standard Reinforcement Learning (RL) with simple, uniform length penalties, we trigger a catastrophic failure mode: Entropy Collapse.
Our analysis identifies that optimizing explicitly for shorter trajectories narrows the model’s action distribution. The policy becomes increasingly deterministic, “collapsing” into a narrow set of predictable token choices that prematurely shrink the exploration space. While this brevity is acceptable for “easy” problems, it is fatal for “hard” ones. A collapsed policy lacks the diversity required to discover valid reasoning paths, effectively bypassing high-level behaviors like self-reflection and alternative hypothesis testing.
The Risk of Entropy Collapse Naive optimization for brevity triggers rapid entropy decay. By forcing the model to be deterministic, we stifle the exploration necessary to solve challenging problems. The model becomes “overly confident” in suboptimal shortcut solutions, losing the ability to perform the extensive deduction required for high-stakes reasoning.
3. Introducing CEEH: A Targeted Approach to Compression
To resolve this efficiency paradox, we introduce the CEEH (Compress responses for Easy questions and Explore Hard ones) framework. The core philosophy is simple: not all reasoning steps are created equal. CEEH separates instances that require deep, high-entropy exploration from those where the reasoning path is well-established and can be safely shortened.
CEEH utilizes two synergistic components to maintain reasoning robustness:
- Difficulty-Aware Entropy Regularization: Sustains a diverse search space for hard questions while permitting aggressive compression on easy ones.
- Dynamic Optimal-Length Penalty: Stabilizes the reward signal by anchoring compression to an evolving baseline of the model’s own “best-case” brevity.
4. Mechanism 1: Difficulty-Aware Entropy Regularization
We distinguish “hard” from “easy” questions through Dynamic Difficulty Estimation. CEEH maintains a historical accuracy score () for every question using an Asymmetric Exponential Moving Average (EMA).
The asymmetric nature of this EMA is critical for handling stochastic noise. We use a higher update rate (0.2) when the model’s accuracy improves, allowing the system to quickly recognize and exploit progress. Conversely, we use a lower rate (0.05) when accuracy declines to prevent the system from overreacting to “unlucky” rollouts or temporary noise.
| Question Type | Condition | Regularization Strategy |
|---|---|---|
| Hard Questions | High Exploration: Applies a 5x multiplier to the entropy coefficient to force a wider exploration frontier. | |
| Easy Questions | Exploitative Compression: Reduces regularization, allowing the policy to confidently use shorter, established paths. |
5. Mechanism 2: The Dynamic Optimal-Length Penalty
Traditional length penalties often rely on fixed priors or inter-group normalization, which are non-stationary and frequently unstable. CEEH instead introduces a dynamic penalty anchored to the historically shortest correct response () for each specific question.
This anchoring is more “discriminative” than group-wise normalization. When entropy regularization causes length inflation on hard questions, serves as a stable denominator that strengthens the compression signal precisely when it is needed most.
The mechanism follows a rigorous three-step process:
- Tracking: The system monitors and updates the shortest successful trajectory () the model has ever achieved for question .
- Penalizing: Length penalties are applied only to correct responses () and only when the current batch accuracy exceeds the historical estimate ().
- Clipping: To ensure the length constraint never reverses the fundamental reward relationship between correct and incorrect answers, the penalty is clipped to a range of .
6. Empirical Proof: Maintaining Accuracy while Cutting the Fluff
We evaluated CEEH across six rigorous benchmarks. To measure the trade-off, we utilize the Normalized Accuracy Gain (NAG), which quantifies accuracy sacrificed per unit of length reduction. A lower NAG indicates a more efficient compression.
As shown below, CEEH-ME achieved a 30%+ reduction in tokens while maintaining or improving accuracy compared to the base model—a feat that standard length penalties fail to replicate. In the most difficult benchmark, AIME25, the slight drop in accuracy is a highly efficient trade-off given the massive 33% reduction in reasoning length.
Performance of R1-Distill-Qwen2.5-7B Variants
| Model Variant | Benchmark | Accuracy (ACC) | Length (LEN) | NAG ↓ |
|---|---|---|---|---|
| Base Model | MATH500 | 91.3% | 3701.0 | — |
| Length-Penalty | MATH500 | 91.4% | 2696.0 | -0.06 |
| CEEH-ME | MATH500 | 92.1% | 2170.0 | -0.56 |
| Base Model | AIME25 | 36.7% | 10958.0 | — |
| Length-Penalty | AIME25 | 35.6% | 10173.0 | 0.8 |
| CEEH-ME | AIME25 | 36.3% | 7311.0 | 0.63 |
| CEEH-ME | GSM8K | 91.3% | 646.0 | -0.08 |
7. Deep Dive: Training Dynamics and Policy Entropy
The “smoking gun” of CEEH’s success lies in performance. While standard length penalties consistently degrade the upper bound, CEEH maintains or improves it (e.g., AIME25 rising from 63.3 to 70.0). This proves that our framework is not simply “teaching the model to be short”—it is preserving and enhancing the model’s genuine reasoning capability.
Technical Sidebar: Why Length Penalties Erode Entropy
In on-policy RL, increasing the length penalty coefficient narrows the action distribution. This encourages deterministic token choices by reinforcing current generations with high confidence. This feedback loop accelerates entropy collapse, preventing the model from exploring alternative reasoning branches. CEEH-ME counters this by injecting entropy specifically where the model is struggling (), effectively protecting the “entropy frontier” of the model’s capability.
8. Conclusion: The Future of Robust, Efficient Reasoning
The perceived zero-sum game between accuracy and efficiency is a symptom of poor exploration control, not an inherent law of LLMs. CEEH proves that the Efficiency Paradox is solvable. By protecting the exploration space for difficult deduction while aggressively pruning the “fluff” from established reasoning paths, we can deploy reasoning models that are both logically robust and computationally lean.
Key Takeaways
- Entropy collapse is the primary failure mode in reasoning compression; it narrows action distributions and breaks self-reflection.
- The 5x multiplier for hard questions ensures the model maintains a diverse reasoning frontier where it is most vulnerable.
- Asymmetric EMA updates (0.2 vs 0.05) stabilize difficulty signals against the inherent stochastic noise of RL training.
- Dynamic anchoring provides a more discriminative and stable reward signal than fixed length priors or group normalization.
Read the full paper on arXiv · PDF