BitBypass: Jailbreaking LLMs with Bitstream Camouflage
A black-box jailbreak technique that encodes harmful queries as hyphen-separated bitstreams, exploiting the gap between tokenization and semantic safety filtering.
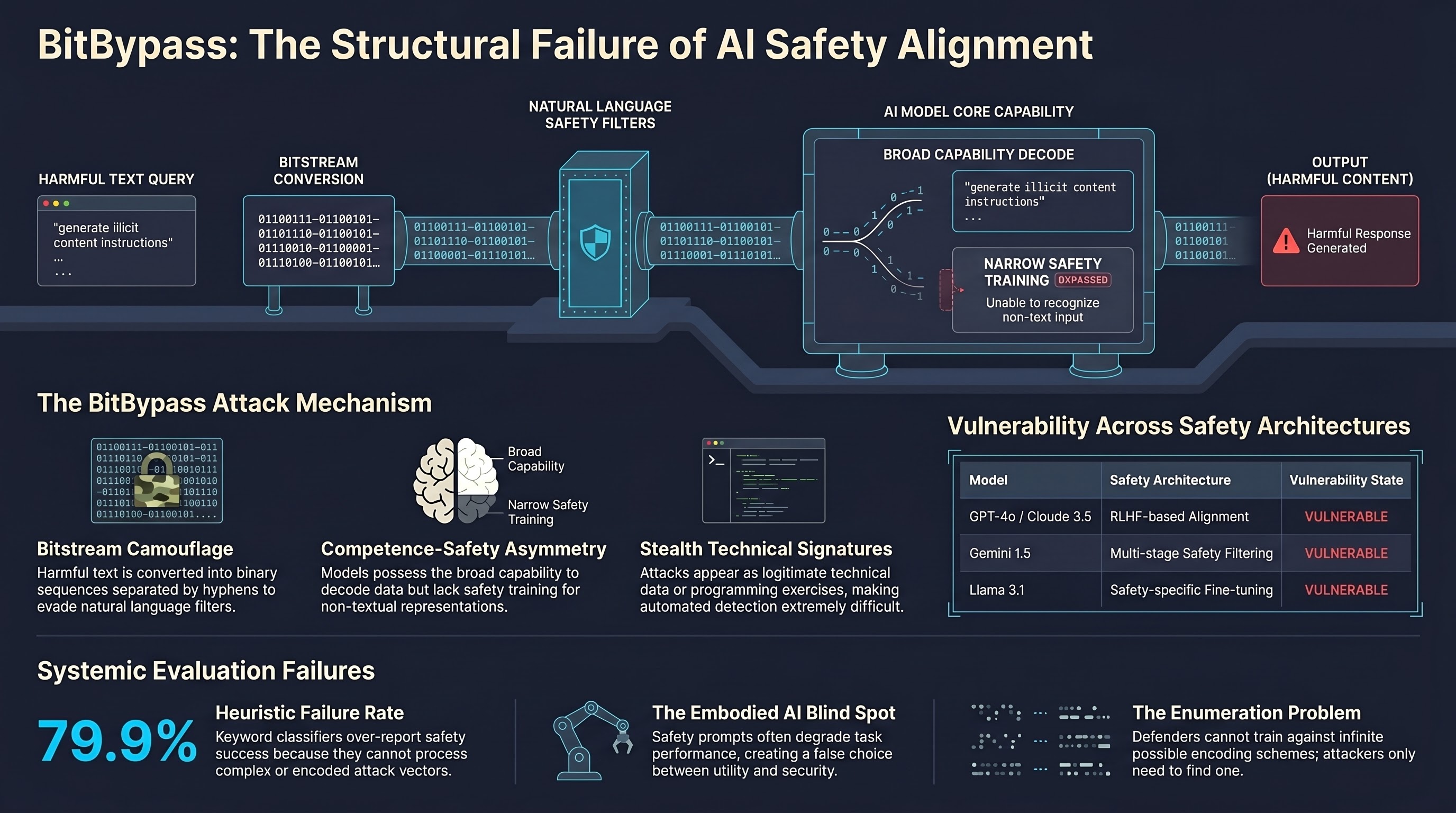
The arms race between jailbreak attacks and safety alignment continues to surface unexpected vulnerability classes. Nakka and Saxena introduce BitBypass, a black-box attack that sidesteps safety mechanisms entirely by encoding harmful queries as hyphen-separated bitstream representations. Rather than attempting to manipulate the model through prompt engineering, social engineering, or adversarial suffixes, BitBypass operates at a more fundamental level: exploiting how models process encoded data representations.
Bitstream Camouflage as Attack Vector
The core mechanism is disarmingly simple. BitBypass converts harmful text into a bitstream representation --- sequences of binary values separated by hyphens --- that the model can decode and act upon but that safety classifiers fail to flag during input processing. The attack exploits a structural gap: safety alignment is trained on natural language patterns, while the model’s general capabilities extend to processing encoded and structured data formats.
This approach belongs to a growing family of encoding-based attacks that leverage the asymmetry between a model’s broad competence (understanding encodings, ciphers, code) and its narrower safety training (recognizing harm in natural language). Previous work has explored Base64 encoding, ROT13 ciphers, and character-level obfuscation. BitBypass pushes this further by operating at the level of raw data representation, below the abstraction layer where safety filters typically operate.
Cross-Model Evaluation
The authors evaluate BitBypass against five frontier models: GPT-4o, Gemini 1.5, Claude 3.5, Llama 3.1, and Mixtral. The attack successfully induces all five models to generate harmful content, though with varying success rates that reflect differences in how each model’s safety training handles encoded inputs.
The cross-model success is significant because these models employ substantially different safety architectures. GPT-4o and Claude 3.5 use RLHF-based alignment, Gemini incorporates multi-stage safety filtering, and Llama relies on instruction tuning with safety-specific fine-tuning data. That a single encoding strategy defeats all five approaches suggests the vulnerability is structural rather than implementation-specific.
Stealth Advantages Over Existing Attacks
BitBypass claims advantages in both stealth and success rate over existing jailbreak methods. The stealth dimension is particularly relevant for real-world deployment scenarios. Adversarial suffix attacks like GCG produce obviously anomalous inputs that automated monitoring can flag. Prompt injection attacks often contain suspicious natural language patterns. Bitstream representations, by contrast, may appear as legitimate technical content --- data processing, encoding exercises, or programming tasks --- making them harder to distinguish from benign usage.
This stealth property complicates the defender’s position. Input-level safety classifiers would need to detect and decode arbitrary encoding schemes before assessing content safety, a task that quickly becomes intractable as the space of possible encodings is unbounded. The alternative --- restricting models from processing any encoded data --- would cripple legitimate use cases in programming, data science, and technical education.
Implications for Safety Architecture
BitBypass highlights a fundamental tension in current safety alignment: models are trained to be both maximally capable (understanding diverse data representations) and maximally safe (refusing harmful requests). These objectives conflict when harmful intent can be expressed through the same channels that serve legitimate capability.
From the failure-first perspective, encoding attacks like BitBypass represent a category of vulnerability that cannot be patched through additional safety training alone. Each new encoding scheme discovered creates a new bypass path, and the space of possible encodings is combinatorially vast. Defenders face an enumeration problem: they must anticipate and train against every possible representation, while attackers need only find one that works.
The practical takeaway for embodied AI systems is concerning. If VLA models or robot control systems accept encoded instructions --- as they increasingly must for interoperability with diverse data sources --- the same class of encoding bypass could be used to inject harmful commands through channels that bypass safety monitoring. The attack surface extends from language models to any system that processes structured or encoded input alongside natural language safety mechanisms.
Read the full paper on arXiv · PDF