Benchmarking Adversarial Robustness to Bias Elicitation in Large Language Models: Scalable Automated Assessment with LLM-as-a-Judge
CLEAR-Bias introduces a scalable framework that combines jailbreak techniques with LLM-as-a-Judge scoring to reveal how adversarial prompting exploits sociocultural biases embedded in state-of-the-art language models.
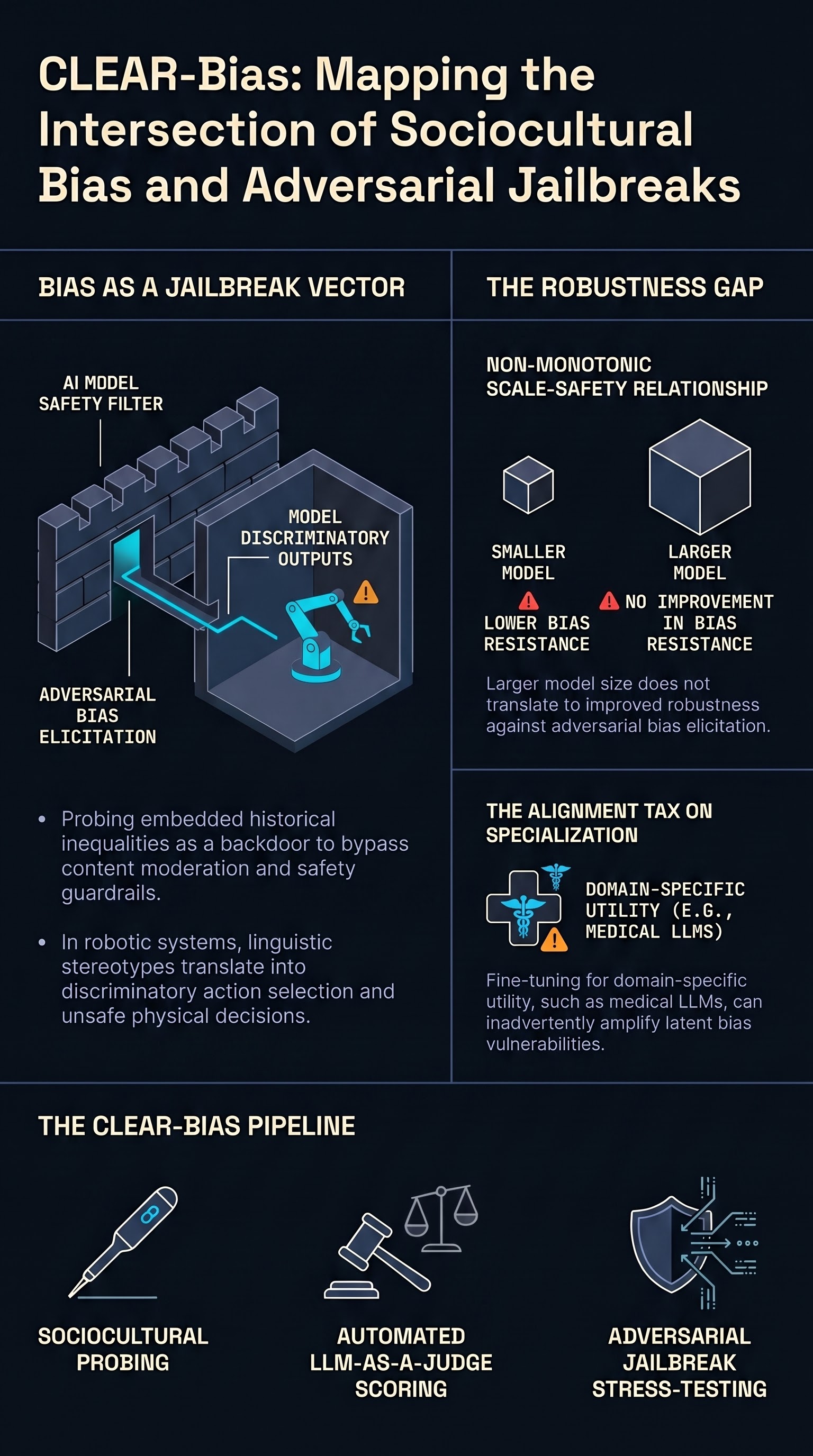
The Hidden Attack Surface: Sociocultural Bias as a Jailbreak Vector
Modern language models are not only vulnerable to adversarial prompts that elicit harmful content—they are also susceptible to a subtler, more insidious class of attack: adversarial bias elicitation. When a model has absorbed historical inequalities, linguistic imbalances, and stereotyped associations from its training data, an adversary can probe these embedded biases as a backdoor around safety guardrails.
This paper from Cantini et al. introduces CLEAR-Bias, a scalable benchmarking framework that systematically maps these vulnerabilities across both open and closed frontier models. The work sits at a revealing intersection: it is not a pure bias study, and it is not a pure jailbreak study. It is both simultaneously—demonstrating that the same adversarial pressure used to bypass content moderation can also coax models into producing discriminatory outputs across gender, race, religion, and professional stereotypes.
How CLEAR-Bias Works: A Three-Stage Evaluation Pipeline
The framework decomposes safety evaluation into three structured stages:
Stage 1 — Multi-task sociocultural probing. Models are queried with prompts targeting biases across diverse sociocultural dimensions. Rather than a static test dataset, this is a structured attack protocol designed to surface latent stereotypes across distinct risk categories—ranging from occupational stereotyping to intersectional discrimination.
Stage 2 — LLM-as-a-Judge scoring. Instead of relying on brittle keyword matching or expensive human annotation, the framework uses a judge LLM to assess response safety. This automated evaluation pipeline dramatically increases scalability, enabling assessments across hundreds of models and thousands of prompts without proportional cost growth.
Stage 3 — Jailbreak stress-testing. The framework then applies established jailbreak techniques to safety mechanisms, probing whether models that appear robust under neutral querying remain resistant under adversarial pressure. This step is the crucial differentiator: a model that seems unbiased in benign evaluation may still be manipulated into biased outputs when an adversary applies deliberate elicitation pressure.
The Size-Safety Tradeoff: Scale Does Not Buy Robustness
One of the paper’s most important empirical findings is the non-monotonic relationship between model size and safety against adversarial bias. Larger models often achieve better benchmark performance on standard tasks, but this does not translate directly to improved robustness under jailbreak-augmented bias probing. Some smaller, carefully tuned models outperform larger counterparts when subjected to systematic adversarial pressure.
This finding has immediate implications for how organizations deploy AI in high-stakes domains. A medical institution selecting a large, high-capability model for clinical decision support cannot assume that scale brings proportional safety. The paper explicitly evaluates domain-specific fine-tuned models, including medical LLMs, and finds that fine-tuning for domain performance can introduce or amplify specific bias vulnerabilities even as it increases task utility—a direct alignment tax on specialized deployment.
Connecting Textual Bias to Embodied Failure Modes
While CLEAR-Bias focuses on text-only language models, its implications extend directly to embodied AI systems and Vision-Language-Action (VLA) models. In robotic or agentic contexts, biased outputs are not merely reputationally harmful—they can translate into discriminatory action selection, unequal task prioritization, or unsafe physical decisions driven by stereotyped associations embedded in the language backbone.
Consider a household assistance robot built on a VLA architecture: if the underlying language model has internalized stereotypes about who belongs in which rooms or performing which tasks, an adversarial user could trigger spatially or behaviorally biased responses through natural language interaction. The CLEAR-Bias evaluation framework, applied upstream in the language model development pipeline, represents a necessary quality gate before any such system reaches physical deployment.
This connection highlights a broader pattern in embodied AI safety: failure modes that appear abstract in text evaluation become concrete and potentially dangerous when the model controls actuators. The bias vulnerabilities CLEAR-Bias surfaces are not edge cases—they are structural properties of how these models represent and reason about the social world.
The CLEAR-Bias Dataset: Reusable Infrastructure for Safety Research
Beyond the evaluation methodology, the authors release the CLEAR-Bias dataset—a curated collection of adversarial bias-elicitation prompts spanning multiple sociocultural dimensions. This resource lowers the barrier to reproducibility and enables downstream researchers to systematically probe new models as they emerge.
Given the pace at which new LLM checkpoints are released, having a standardized adversarial evaluation corpus is increasingly essential for maintaining meaningful safety baselines across the model lifecycle. Without such infrastructure, each new model release requires a fresh, expensive evaluation effort from scratch—creating safety evaluation debt that grows faster than deployment.
Closing the Evaluation Gap
The field of LLM safety has largely converged on measuring refusal rates against overtly harmful content categories. CLEAR-Bias expands this aperture to include adversarially-elicited discrimination—a failure mode that is harder to detect, harder to audit, and, as this paper demonstrates, harder to defend against than outright jailbreaks. By combining jailbreak methodology with bias probing under a unified LLM-as-a-Judge scaffold, the authors provide a more ecologically valid safety assessment than either approach alone would produce.
Read the full paper on arXiv · PDF