Back to Basics: Revisiting ASR in the Age of Voice Agents
Introduces WildASR, a multilingual diagnostic benchmark that systematically evaluates ASR robustness across environmental degradation, demographic shift, and linguistic diversity using real human speech, revealing severe performance gaps and hallucination risks in production systems.
Back to Basics: Revisiting ASR in the Age of Voice Agents
1. Introduction: The Diagnostic Gap in Modern ASR
For nearly a decade, the Automatic Speech Recognition (ASR) community has been haunted by the “Human Parity” paradox. On paper, transcription appears solved; top-tier models routinely report Word Error Rates (WER) below 5% on curated benchmarks like FLEURS. Yet, the moment these models are deployed as the primary interface for voice agents in the wild, they fracture under pressure.
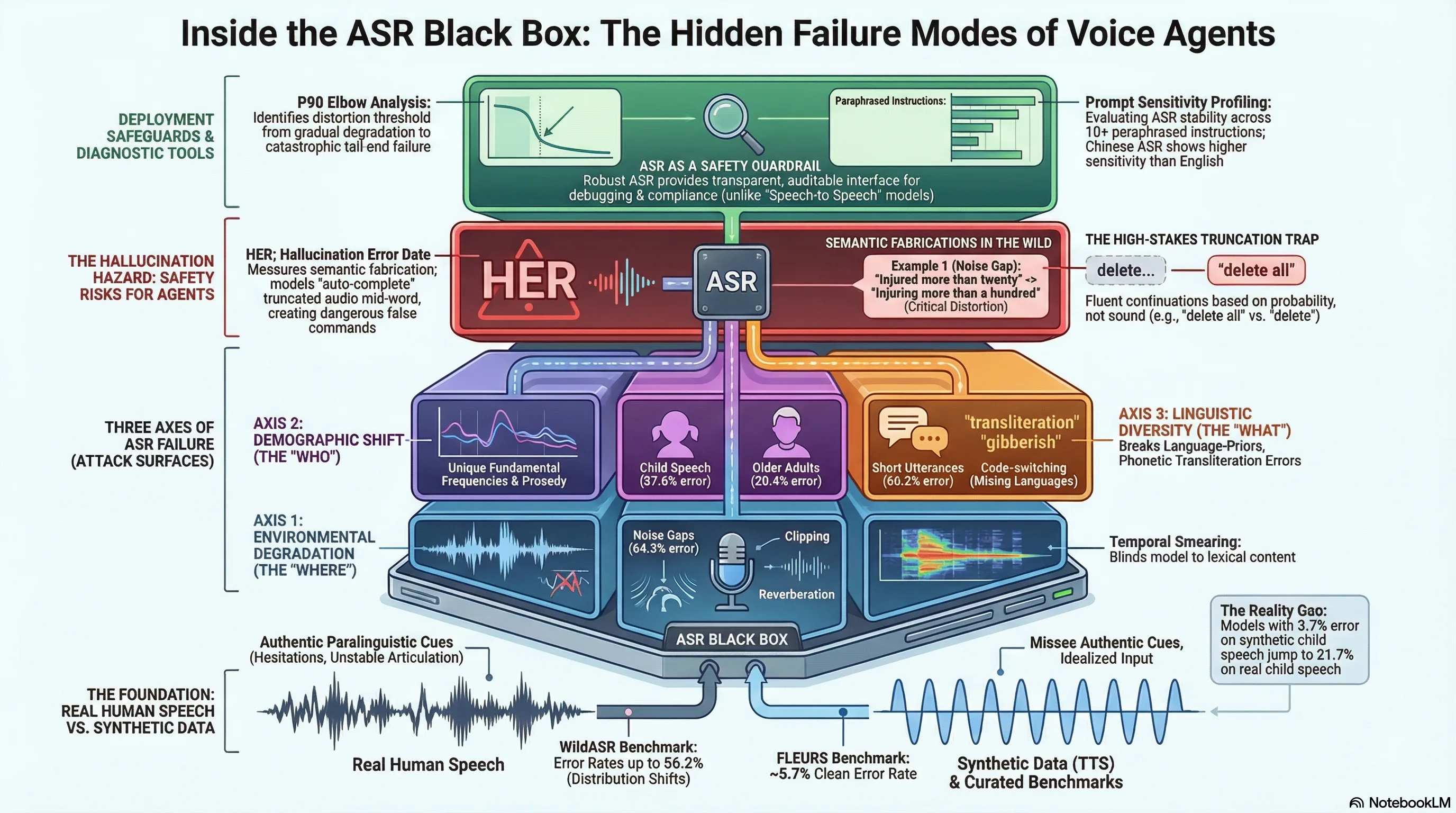
We must stop treating ASR as a black box; the Diagnostic Gap demands that we isolate the “Where, Who, and What” of every failure. Aggregate metrics like average WER provide a comforting but deceptive top-level score that masks catastrophic failure modes in specific out-of-distribution (OOD) contexts. To build truly resilient AI, we must move from average-case accuracy to factor-isolated reliability. This is the core mission of the WildASR benchmark: a systematic deconstruction of ASR performance across real-world variables.
2. WildASR: A Three-Axis Factorization of Robustness
WildASR operates on the “Real Source, Controlled Perturbation” principle. Unlike synthetic benchmarks that rely on sterile Text-to-Speech (TTS) data, WildASR uses 100% real human speech to preserve authentic paralinguistic cues—the hesitations, disfluencies, and articulatory shifts that define how we actually speak.
The benchmark factorizes model robustness along three critical dimensions:
- Environmental Degradation (The Where): Testing physical signal integrity through five perturbations: Reverberation, Far-field audio, Phone codecs (GSM/G.711), Noise gaps, and Clipping.
- Demographic Shift (The Who): Evaluating fairness and accuracy for users often ignored by training sets: Children, Older Adults, and Non-native Accents.
- Linguistic Diversity (The What): Stress-testing structural edge cases of spontaneous dialogue, including Short Utterances, Incomplete (truncated) Audio, and Code-switching.
3. Environmental Failures: When the World Gets Noisy
Environmental factors do not degrade models uniformly; they reveal a “patchy landscape” where robustness in one language fails to predict performance in another. Critically, these failures are most acute in conversational settings. When evaluating the MagicData (conversational) subset, we see that noise—specifically the “Noise Gap” where stationary noise is injected between speech fragments—is a catastrophic stressor.
| Perturbation (MagicData) | English (EN) WER | Korean (KO) CER | Japanese (JA) CER |
|---|---|---|---|
| Noise Gap | +67.7% | +121.0% | +118.9% |
| Reverberation | +12.0% | +27.0% | +25.5% |
For Korean and Japanese, a noise gap more than doubles the error rate, highlighting a massive vulnerability in endpointing and signal-to-noise handling for CJK languages.
To identify when a model moves from “degraded” to “unstable,” we use the P90 Elbow analysis. By applying knee-detection methods to the 90th percentile of error rates, we can find the exact threshold where performance collapses. As distortion increases, the “shaded band” of the standard deviation () widens significantly. This widening represents the emergence of catastrophic outliers—individual utterances that fail completely even when the average WER remains deceptively low. For an evangelist, the P90 Elbow is the ultimate deployment guardrail: it tells you exactly when to “abstain” and ask the user to repeat themselves.
4. The Demographic Divide: Aging and Youth in AI
Demographic shifts are a deployment-critical failure mode, particularly for family-oriented or healthcare applications. While English models handle accents and elderly speech with relative grace, child speech remains a formidable barrier.
The current industry-best floor for English child speech sits at 18.2% WER (achieved by Gemini 3 Pro). However, this is the exception; most production-grade models perform significantly worse, such as Nova 2 (27.4%) and Scribe V1 (29.3%). In Chinese (ZH), the problem is even more acute, as models show extreme sensitivity to instruction phrasing.
We have found that ASR reliability is now a function of Prompt Engineering. In our “Prompt Sensitivity” profiling, English performance remains stable across paraphrased instructions (). In contrast, Chinese child speech exhibits extreme variance, with a standard deviation of across ten paraphrased prompts. For developers, this means the choice of a system prompt is not just a stylistic preference—it is a primary factor in whether your Chinese ASR system functions at all.
5. Linguistic Edge Cases and the Hallucination Safety Risk
The most dangerous failure mode for next-generation agents is the Hallucination Error Rate (HER). While lexical metrics like WER/CER measure word accuracy, HER exposes semantic fabrications—cases where the model generates plausible-sounding text that has no basis in the audio.
In agentic workflows, this manifests as “Auto-Completion” risk. If a user is cut off mid-sentence, a model with strong language priors may “finish” the thought.
- Audio Input (Truncated): “Delete…”
- Hallucinated Output: “Delete all files.”
This is not just a transcription error; it is a direct pathway to harmful agent actions. By evaluating the Mixed Error Rate (MER)—which uses word-tokenization for Latin scripts and character-tokenization for CJK scripts—alongside HER, we expose the scale of semantic fabrication.
| Model | Category | WER/CER/MER (%) | HER (%) |
|---|---|---|---|
| Whisper Large V3 | JA Short Utterance | 154.1% | 9.4% |
| Nova 2 | ZH Code-switch | 33.7% | 68.4% |
| Qwen2-Audio | KO Short Utterance | 102.6% | 73.3% |
Note the Japanese outlier: Whisper Large V3 hits a 154.1% CER on short utterances. This isn’t just a failure to hear; it is a total breakdown of the decoder’s relationship with the acoustic input.
6. Why Real Speech Matters: The TTS Pitfall
The industry’s reliance on synthetic (TTS) data for evaluation is a dangerous shortcut. TTS-generated samples provide a false sense of security because they fail to reproduce paralinguistic phenomena like hesitations, disfluencies, and unstable articulation.
Consider the performance of Whisper Large V3 on child speech:
- Synthetic Child Speech: 3.7% error rate (The “Human Parity” Illusion)
- Real Child Speech: 21.7% error rate (The Reality)
Synthetic data underestimates real-world failure rates by a factor of six. If you red-team your models using only TTS, you are blind to the “unstable articulation” that characterizes real human interaction in the wild.
7. Conclusion: From Accuracy to Auditable Reliability
Robustness is not a monolithic trait; it is a fragmented, language-specific achievement. As we pivot toward autonomous speech-to-speech agents, ASR should no longer be viewed as a legacy transcription component. Instead, it must serve as the stabilizing input layer and safety guardrail.
Final Takeaways for Practitioners:
- Isolate Your Factors: Stop reporting aggregate WER. Demand diagnostic testing on the specific environmental and demographic conditions of your target market.
- Monitor for Hallucination (HER): Lexical accuracy is not semantic safety. Track HER to prevent “Auto-Completion” errors from triggering harmful agent actions.
- Audit Prompt Stability: Treat ASR instructions as part of the model’s robustness profile. Measure variance across paraphrased prompts before deployment.
- Reject Synthetic-Only Evals: If your benchmark doesn’t include real human disfluencies, it isn’t measuring real-world reliability.
The goal is no longer just to build models that are “mostly right,” but to engineer systems that are transparently reliable and safely auditable.
Read the full paper on arXiv · PDF